1. 概述
在深度学习中,卷积层(Convolutional Layer)和全连接层(Fully Connected Layer)是神经网络中最常见的两种层类型。它们构成了从动作识别、语言翻译、语音识别到癌症检测等各类任务中几乎所有神经网络的基础。
本文将分别介绍这两种层的结构与工作原理,并通过对比帮助你理解它们之间的主要区别。
2. 全连接层(FC Layer)
全连接层(Fully Connected Layer)是指:输入层中的每一个神经元都与输出层中的每一个神经元相连。
举个例子,假设我们有 7 个输入神经元  ,和 5 个输出神经元
,和 5 个输出神经元  。
。
在全连接层中,我们会对输入神经元进行加权线性变换,然后将结果通过一个非线性激活函数(如 ReLU、Sigmoid、Tanh 等)进行处理。其输出神经元的计算公式如下:
$$ \mathbf{y_i = f \left(\sum_{j=1}^7 w_{ij} \ x_j \right)} $$
其中 $ i \in [1, 5] $。
下图展示了这个例子中的 FC 层神经元连接方式:
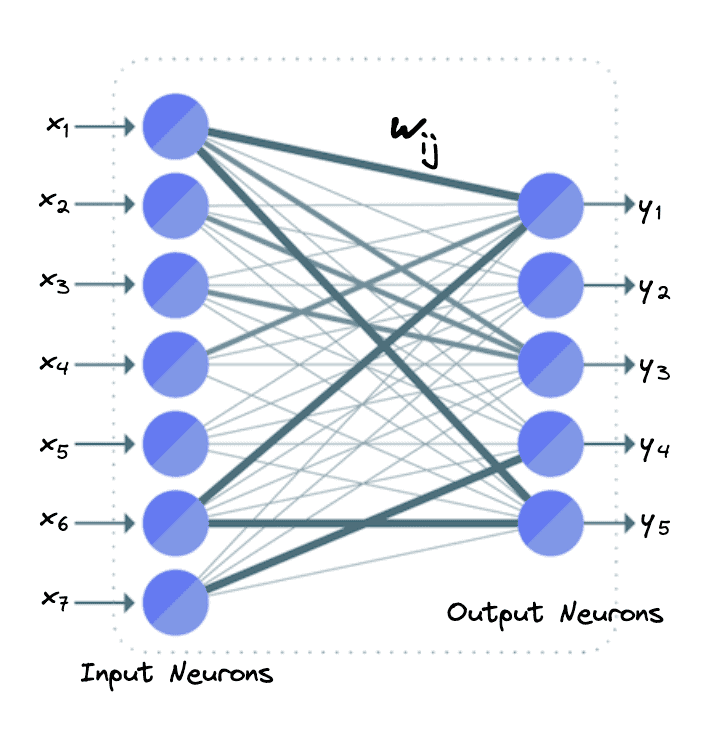
✅ 注意:在一个具有 n 个输入和 m 个输出的全连接层中,总共有 $ \mathbf{n \times m} $ 个权重参数,因为每对输入输出神经元之间都有一个独立的权重 $ w_{ij} $。
3. 卷积层(Conv Layer)
卷积层的核心操作是卷积运算(convolution),其原理是将一个图像与一个卷积核(也叫滤波器,filter)进行逐元素相乘再求和,从而生成一个特征图(feature map)。
具体来说,卷积操作分为以下几步:
- 在输入图像上滑动卷积核;
- 对卷积核和对应区域的图像像素进行逐元素相乘;
- 将所有乘积相加,得到一个输出值;
- 重复这个过程,覆盖整个图像。
下图展示了一个 $ 6 \times 6 $ 的图像与一个 $ 3 \times 3 $ 的卷积核在位置 (2, 2) 处进行卷积的过程:
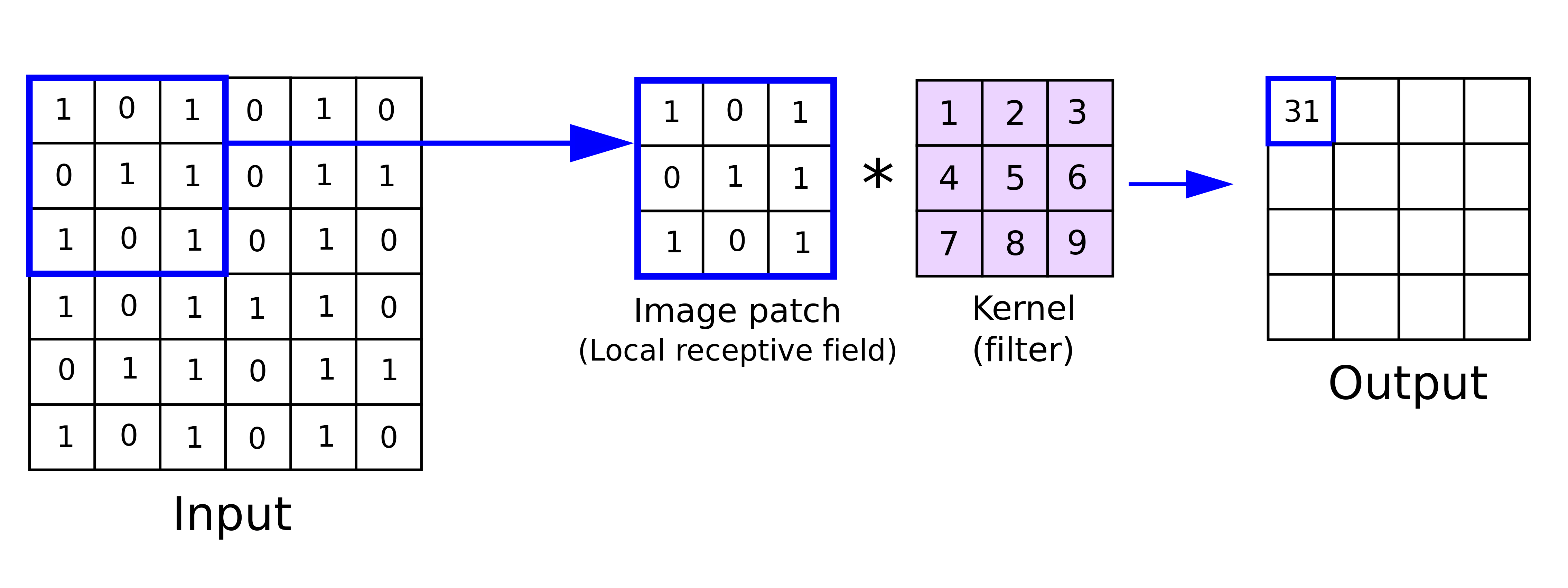
在卷积层中,输入与多个可学习的卷积核进行卷积操作,每个卷积核生成一个对应的激活图(activation map)。与全连接层不同的是,卷积层的参数数量与输入神经元数量无关,而是与卷积核的大小有关。
4. 主要区别
以下是卷积层与全连接层之间的主要区别:
✅ 连接密度
| 层类型 | 连接方式 | 特点 |
|---|---|---|
| 全连接层(FC) | 每个输入神经元都与每个输出神经元连接 | 密集连接,参数数量巨大 |
| 卷积层(Conv) | 每个输出神经元只与局部输入区域连接 | 局部连接,参数共享,适合图像等高维数据 |
✅ 参数数量
| 层类型 | 参数数量计算方式 | 说明 |
|---|---|---|
| 全连接层 | 输入数 × 输出数 | 随输入输出增长,参数爆炸式增加 |
| 卷积层 | 卷积核大小 × 输入通道数 × 输出通道数 | 参数固定,不随输入大小变化 |
✅ 权重共享
- 全连接层:每个连接都有独立的权重,没有共享。
- 卷积层:同一个卷积核在图像的不同位置共享权重,大幅减少参数数量,提高泛化能力。
✅ 适用场景
| 层类型 | 适用场景 | 说明 |
|---|---|---|
| 全连接层 | 分类、决策层 | 通常在神经网络的最后几层使用 |
| 卷积层 | 特征提取 | 适合图像、语音等空间结构数据 |
⚠️ 踩坑提醒:在图像识别任务中,如果直接使用全连接层处理高分辨率图像,会导致参数爆炸,训练效率极低,甚至无法训练。
5. 总结
本文介绍了卷积层和全连接层的基本结构和工作原理,并通过对比分析了它们在连接方式、参数数量、权重共享和适用场景上的主要区别。
- 卷积层更适合处理图像等高维数据,具有局部连接和权重共享的优势;
- 全连接层通常用于最后的分类或决策任务,但在处理高维数据时效率较低。
在实际构建神经网络时,通常会结合使用这两种层类型,以充分发挥它们各自的优势。