1. 概述
Encoder-Decoder 模型和循环神经网络(RNN)是处理文本序列最自然的方式之一。
在本教程中,我们将了解它们的基本概念、不同架构、应用场景、使用过程中可能遇到的问题,以及解决这些问题的最有效方法。
理解本文内容的前提是你对人工神经网络和反向传播算法有基本的了解即可。
2. 简介
2.1 使用 RNN 的编码器
对人类来说,理解文本是一个逐步积累信息的过程。我们阅读句子时,会逐词处理,直到读完整个句子。
在深度学习中,一个随着时间步重复相同结构、积累信息的系统就是循环神经网络(RNN)。
一般来说,文本编码器的作用是将文本转换为数值表示。虽然实现方式有很多种,但本教程中我们特指基于 RNN 的编码器。来看一个示意图:
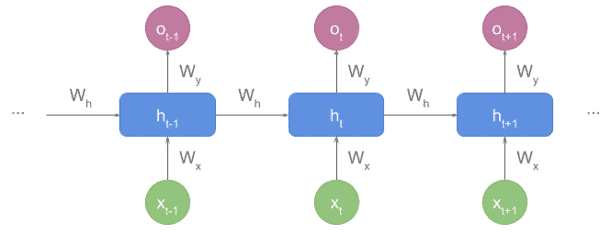
有些资料中会以“展开”形式展示 RNN:
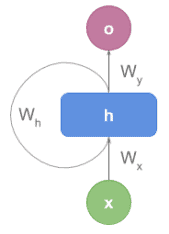
每个时间步 t 的 RNN 单元包含以下内容:
输入:
- 输入向量
x_t(表示当前词) - 隐藏状态向量
h_{t-1}(表示之前的状态)
输出:
- 输出向量
o_t(不是每个单元都会输出)
权重参数:
W_x:连接x_t和h_tW_h:连接h_{t-1}和h_tW_o:连接h_t和o_t
2.2 解码器
与编码器不同,解码器的作用是将一个表示序列状态的向量展开成对我们有意义的输出,比如文本、标签或类别。
解码器的关键特点是它不仅需要当前隐藏状态,还需要前一个时间步的输出。在解码开始时没有前一个输出,因此我们会使用一个特殊标记 <start> 来表示起始。
举个例子来说明机器翻译的工作原理:
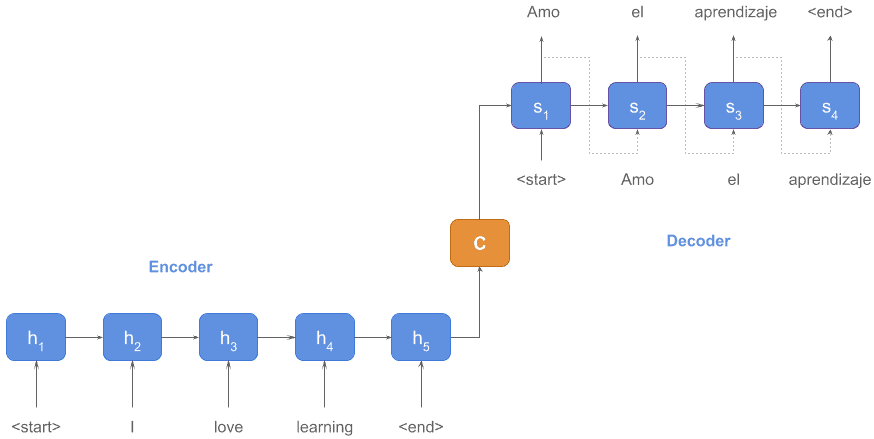
编码器输出的状态 C 表示源语言(英文)句子:“I love learning”。
解码器根据这个状态 C 生成目标语言(西班牙语)句子:“Amo el aprendizaje”。
注意:C 可以看作整个序列的向量表示,或者换句话说,我们可以用编码器粗略地从任意长度的文本中提取嵌入向量,但这不是推荐的做法,我们会在其他教程中详细说明。
2.3 更多细节
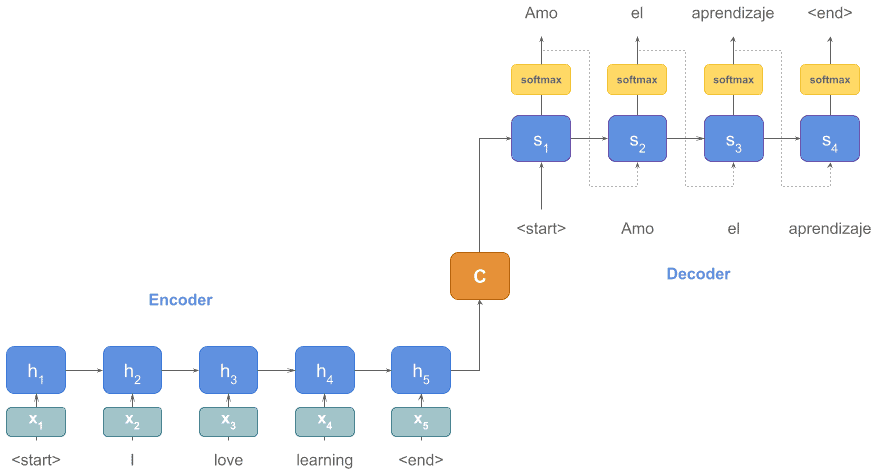
上图为了简化,直接用了“词”作为输入,但实际输入是词向量(word embeddings),如 x_1, x_2, ... 等等。
此外,解码器部分还应该包含一个 softmax 函数,用于从词汇表中选出当前状态和输入下概率最高的词。
我们来更新一下图示,加入这些细节:
3. 不同架构及其应用场景
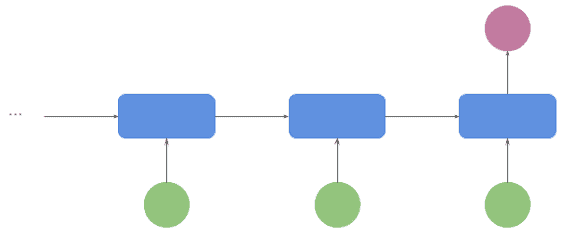
3.1 多对一(Many to One)
广泛用于分类任务,例如情感分析或词性标注。输入是一串词,输出是一个类别,由最后一个单元生成:
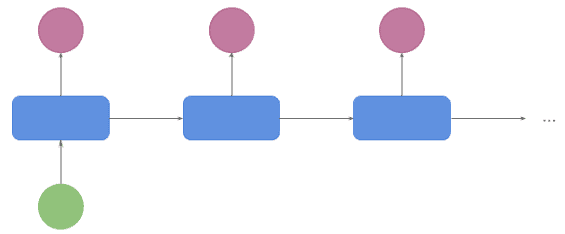
3.2 一对多(One to Many)
主要用于文本生成任务。输入是一个主题,输出是一串词:
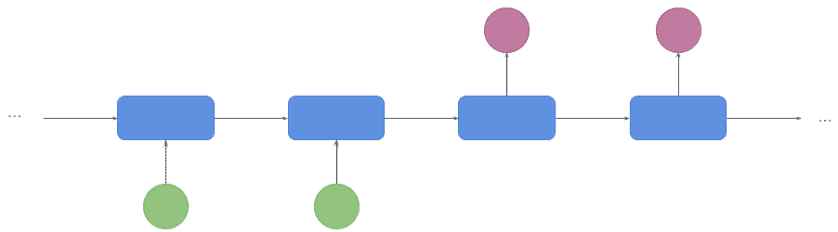
3.3 多对多(第一种)(Many to Many - 1st version)
这是机器翻译中最常见的架构(也叫 seq2seq)。输入和输出都是词序列。
编码器先完成整个序列的编码,生成最终状态后,解码器才开始工作:
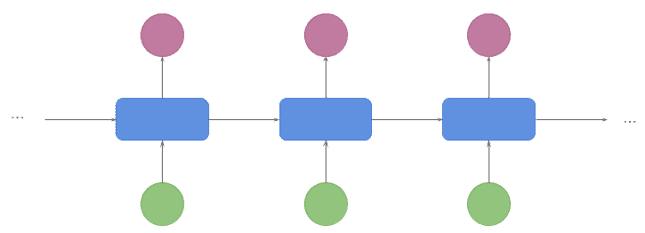
3.4 多对多(第二种)(Many to Many - 2nd version)
常见于视频字幕生成或词性标注任务。输入一帧帧处理的同时,输出也在逐步生成,不需要等待编码完成:
4. 优缺点分析
✅ 优点:
- 支持任意长度的输入
- 模型大小不随输入长度变化
- 能自然建模时间序列数据
❌ 缺点:
- 计算慢,必须按顺序处理(不能并行)
- 存在梯度消失和梯度爆炸问题
- 对长序列处理效果不佳
5. LSTM 与 GRU 单元
5.1 梯度消失与爆炸问题
梯度是用于更新网络权重的向量,使模型在未来表现更好。
由于反向传播和链式法则,当梯度较小时,它会随层数呈指数级衰减,导致深层网络的更新无法影响浅层网络,模型无法学习。
如下图所示,RNN 中早期的更新随着序列推进迅速减弱:
梯度爆炸则是相反的情况:如果梯度很大,它会指数级增长,导致训练过程极不稳定。
LSTM 和 GRU 就是为了解决这些问题而设计的。
5.2 基础 RNN 单元
基础 RNN 单元结构如下:
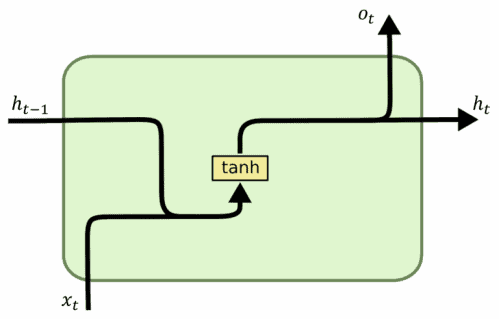
- 输入:前一个状态 + 当前词向量
- 输出:下一个状态 + 输出向量
下面是一个使用基础 RNN 的 TensorFlow 示例:
import tensorflow as tf
...
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, 64),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
5.3 LSTM
长短期记忆单元(LSTM)包含细胞状态、输入门、输出门和遗忘门。
结构如下图所示:
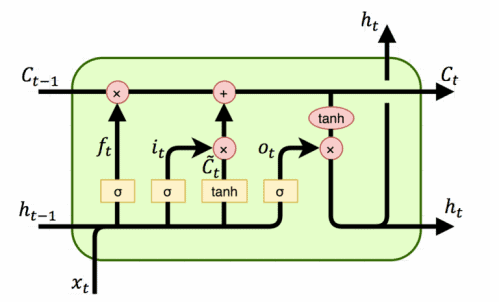
各部分作用如下:
- 细胞状态:单元的记忆
- 输入门:控制新值流入细胞的程度
- 遗忘门:控制旧值保留的程度
- 输出门:控制细胞值用于输出的程度
使用 LSTM 的 RNN 示例代码如下:
import tensorflow as tf
...
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, 64),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
5.4 GRU
门控循环单元(GRU)是 LSTM 的简化版,结构类似但参数更少(缺少输出门):
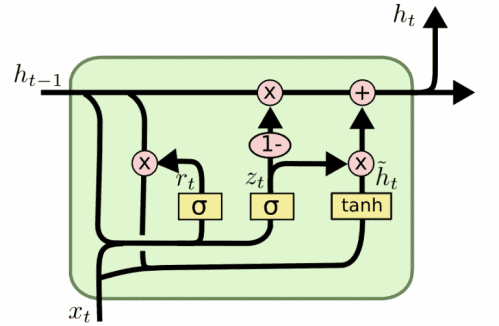
使用 GRU 的 RNN 示例代码如下:
import tensorflow as tf
...
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, 64),
tf.keras.layers.Bidirectional(tf.keras.layers.GRU(64)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
5.5 什么时候用哪个?
- 不要使用基础 RNN,性能太差
- LSTM vs GRU:没有统一规则,取决于任务。建议都试一下,选效果更好的
- 如果两者性能相近,优先使用 GRU,因为计算开销更低
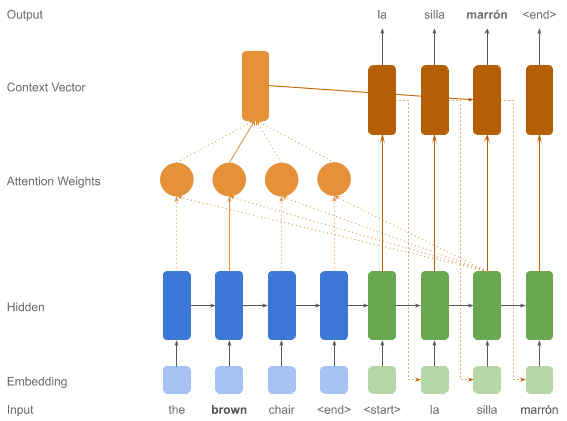
6. 注意力机制(Attention Mechanism)
虽然 LSTM 和 GRU 提升了 RNN 对长序列的处理能力,但有些任务仍需要更强的建模能力。
典型例子是神经机器翻译(NMT),编码器和解码器语法结构差异大。要翻译下一个词,我们需要关注输入句子中特定的几个词,顺序可能完全不同。
举个例子,将法语句子 “L'accord sure la zone économique européene a été signé en août 1992” 翻译成英文:

可以看到,“zone” 主要关注 “Area”,“européenne” 主要关注 “European”。
这正是注意力机制的作用:让解码器在生成下一个输出时,聚焦于输入序列中的特定部分。
结构图如下所示:
7. 总结
在本文中,我们学习了基于 RNN 的 Encoder-Decoder 模型的基本结构、常见架构及其应用场景。
我们也讨论了使用这些模型时可能遇到的问题,以及使用 LSTM、GRU 和注意力机制来解决这些问题的方法。
现在我们已经掌握了这些关键技术,并配有示例代码片段,可以开始构建自己的模型了。