1. 概述
自 word2vec 模型问世以来,它在自然语言处理(NLP)研究及其应用中产生了深远影响(例如,用于主题建模)。其中,Skip-gram 是 word2vec 的一个核心模型,它通过一种称为“负采样(Negative Sampling)”的技术进行训练,这种方法在实现上略显巧妙。
在本文中,我们将深入解析负采样的原理。如果你对 Skip-gram 和 CBOW 模型的区别还不太清楚,可以先参考相关文章。
2. Skip-gram 模型
word2vec 的核心思想是:出现在相同上下文中的词应具有相似的词向量。因此,在训练模型时,我们希望目标函数能够体现这种相似性。通常使用点积(dot product)来衡量向量间的相似性 —— 向量越相似,点积越大。
Skip-gram 模型的基本机制是:给定一个输入词,预测其周围的上下文词。通过这种方式,我们可以学习一个隐藏层,用于计算某个词作为输入词上下文出现的概率:
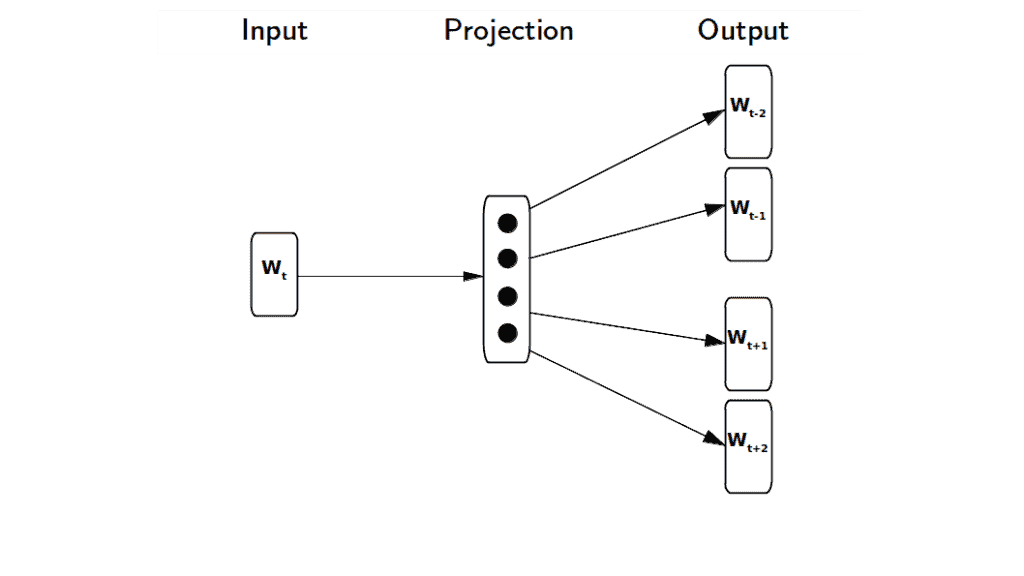
3. 计算瓶颈
假设我们有一段训练语料:词序列 w₁, ..., wₙ。根据 Mikolov 等人在论文《Distributed Representations of Words and Phrases and their Compositionality》中的描述,Skip-gram 的目标函数是最大化输入词周围上下文词的平均对数概率:
(1)
$$
\frac{1}{T} \sum_{t=1}^{T} \sum_{-c \le j \le c, j \ne 0} \log p(w_{t+j} | w_t)
$$
其中:
T是训练数据中所有词的数量;c是上下文窗口大小。
计算这个概率的一种方式是使用 softmax 函数:
(2)
$$
p(w_O|w_I) = \frac{\exp(v'^T_{w_O} v_{w_I})}{\sum_{w=1}^{W} \exp(v'^T_{w} v_{w_I})}
$$
其中:
v_w是词w作为输入词的向量表示;v'_w是词w作为输出词的向量表示;W是词汇表总词数。
这个公式的直觉是:出现在相同上下文中的词应具有相似的向量表示。分子部分通过点积来衡量两个词是否相关,若相关,结果较大;否则较小。
但问题在于分母,它需要对整个词汇表求和。 当词汇表大小达到几十万甚至上百万时,计算变得不可行。这就是负采样发挥作用的地方。
4. 负采样(Negative Sampling)
负采样的核心思想是:通过定义一个新的目标函数,最大化上下文词之间的相似度,同时最小化非上下文词之间的相似度。与传统的 softmax 不同,负采样不遍历整个词汇表,而是从非上下文词中随机选取少量样本(通常 k 在 2 到 20 之间)进行优化。
数据集越小,k 取值越大;反之则越小。
目标函数如下:
(3)
$$
\log \sigma(v'^T_{w_O} v_{w_I}) + \sum_{i=1}^{k} \mathbb{E}{w_i \sim P_n(w)} [\log \sigma(-v'^T{w_i} v_{w_I})]
$$
其中:
σ是 sigmoid 函数;Pₙ(w)是噪声分布,从该分布中采样负样本;- 该分布定义为:词频的 3/4 次幂,经过归一化后得到。
(4)
$$
P_n(w) = \frac{U(w)^{3/4}}{Z}
$$
其中 Z 是归一化常数。
最大化公式 (3) 的结果,会使上下文词的点积增大,非上下文词的点积减小。换句话说,上下文词的向量会更相似,非上下文词的向量则更不相似。
✅ 关键点:公式 (3) 中的计算仅针对 k 个负样本,而不是整个词汇表,这大大降低了计算复杂度。
5. 负采样目标函数的推导
假设 (w, c) 是训练数据中的一对上下文词,我们定义 p(D=1|w, c) 表示这对词来自训练数据的概率。反之,p(D=0|w, c) = 1 - p(D=1|w, c) 表示这对词不是上下文词的概率。
令 θ 为模型参数,D' 表示非上下文词集合,我们的目标是最大化:
(5)
$$
\text{arg max}{\theta} \prod{(w, c) \in D} p(D=1|w, c;\theta) \prod_{(w, c) \in D'} p(D=0|w, c;\theta)
$$
将其转换为对数形式:
(6)
$$
\text{arg max}{\theta} \sum{(w, c) \in D} \log p(D=1|w, c;\theta) + \sum_{(w, c) \in D'} \log (1 - p(D=1|w, c;\theta))
$$
使用 sigmoid 函数定义 p(D=1|w, c;θ):
(7)
$$
p(D=1|w, c;\theta) = \sigma(v_c \cdot v_w) = \frac{1}{1 + e^{-v_c \cdot v_w}}
$$
其中:
v_w是主词向量;v_c是上下文词向量。
代入公式 (6) 得:
(8)
$$
\text{arg max}{\theta} \sum{(w, c) \in D} \log \sigma(v_c \cdot v_w) + \sum_{(w, c) \in D'} \log \sigma(-v_c \cdot v_w)
$$
这个公式与公式 (3) 是等价的,只是在语料库上进行了求和。如果想了解更详细的推导过程,可以参考这篇论文:word2vec explained
6. 总结
本文介绍了 Skip-gram 模型的基本思想,并深入讲解了负采样的工作原理。简单来说,为了降低 softmax 函数在大规模词汇表上的计算开销,负采样通过仅从非上下文词中采样少量样本,来近似 softmax 的效果。
✅ 关键总结:
- Skip-gram 模型通过预测上下文词来学习词向量;
- 原始 softmax 计算成本高;
- 负采样通过引入噪声分布,仅采样少量负样本进行训练;
- 这种方法显著降低了计算复杂度,同时保持了较好的词向量质量。
⚠️ 踩坑提醒:
- 初学者容易误解负采样只是随机选词,但背后有严谨的数学推导;
- 实际实现中,负采样样本的分布也很重要,不能随意选取;
- 适当调整
k的值对模型性能影响较大。