1. 简介
在很多场景中,生成随机数是非常有用的,例如游戏开发、统计分析、密码学等领域。在这些场景中,通常每个随机数的生成都是一个独立事件,与过去或未来的结果无关。比如掷骰子,每次掷出的数字都是独立的,不受之前结果的影响。
但在某些情况下,我们希望对随机数加以限制,确保生成的数值不会重复。例如模拟一副洗牌后的扑克牌、从播放列表中随机选择歌曲等,都需要每个元素只出现一次。
本文将介绍几种常见的实现方式,帮助你在不同场景下高效生成不重复的随机数。
2. 记录历史法
最直观的方法是记录所有已生成的数字,每次生成新数时都检查是否已存在:
algorithm RememberingHistory(maximum):
// INPUT
// maximum = 随机数的最大值
// rng = 用于生成随机数的函数
// history = 已生成数字的集合
// OUTPUT
// 返回一个未出现过的随机数,并更新 history
number <- rng(0, maximum)
while number in history:
number <- rng(0, maximum)
history.add(number)
return number
✅ 优点:实现简单,逻辑清晰
❌ 缺点:性能差,尤其是当已生成数字很多时,碰撞概率高,循环次数剧增
⚠️ **时间复杂度为 O(2n)**,当生成的数字接近最大值时效率急剧下降
3. 提前洗牌法
既然我们要的是一个不重复的随机序列,那我们可以先生成一个打乱顺序的数字列表,然后依次从中取出:
algorithm PreShufflingNumbers(maximum, shuffled):
// INPUT
// maximum = 数字最大值
// shuffled = 打乱顺序后的列表
// OUTPUT
// 返回下一个随机数,并更新 shuffled
if shuffled is empty:
shuffled <- shuffle([1, 2, ..., maximum])
return pop first element from shuffled
✅ 优点:每次取数时间复杂度为 O(1),性能稳定
❌ 缺点:初始化成本高,尤其当 maximum 很大但实际只需要取少量数字时
⚠️ 如果 maximum 是 2^32,初始化几乎不可行
4. 动态洗牌法(推荐)
结合前两种方法的优点,在生成过程中动态洗牌,无需预先生成完整列表:
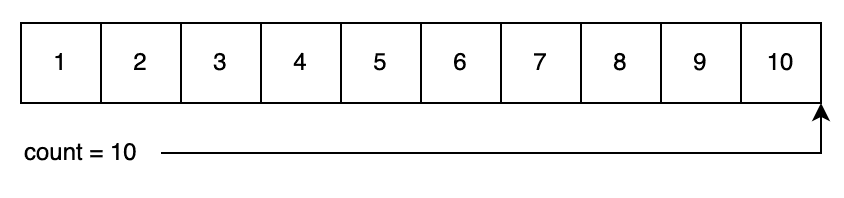
algorithm ShufflingDuringGeneration(maximum):
// INPUT
// maximum = 数字最大值
// numbers = [1, 2, ..., maximum]
// count = 当前可用数字的上限索引(初始为 maximum)
// OUTPUT
// 返回一个唯一的随机数
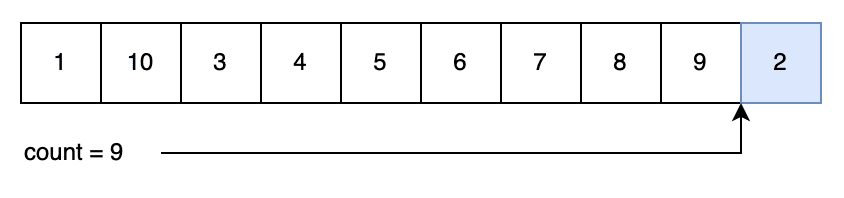
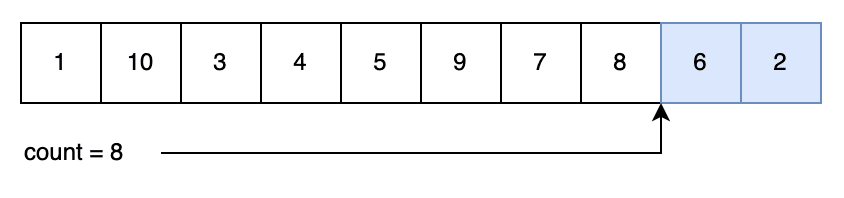
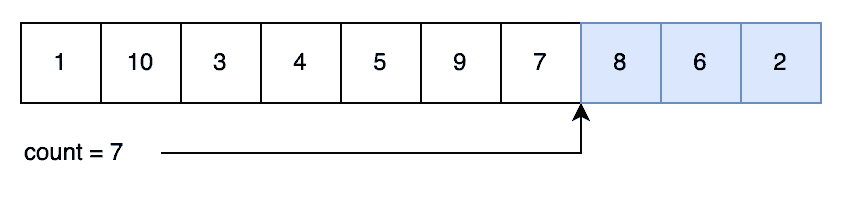
index <- rng(0, count)
count <- count - 1
swap(numbers[index], numbers[count])
return numbers[count]
这个算法的核心思想是:
- 每次从当前可用数字中随机选一个
- 将它交换到“已使用”区域的末尾
- 返回这个数字,并缩小可用区域
示例流程图:
初始状态:
第一次生成:
第二次生成:
后续生成示例:
最终状态:
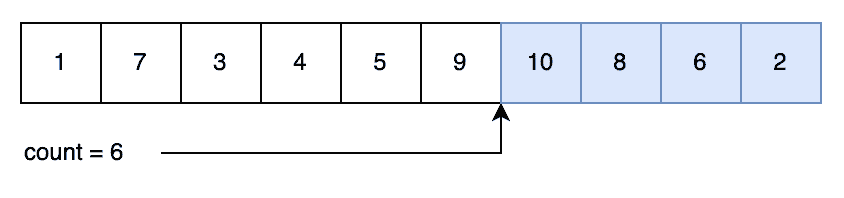
✅ 优点:O(1) 时间复杂度,无初始化开销,内存占用合理
⚠️ 适合大多数中等规模的随机数需求
5. 更进一步:内存优化方案
前面的方法都需要一个数组来保存所有可能的数字,当 maximum 是 2^32 时,内存占用会达到 16GB,显然不可行。
这时候我们只能放弃“动态洗牌”法,考虑以下替代方案:
✅ 方案一:使用记录法(即“记录历史法”)
- 仅记录已生成的数字
- 内存消耗取决于生成数量,而不是最大值
- 缺点:性能随生成数量增加而下降
✅ 方案二:使用伪随机函数 + 哈希
- 例如:使用一个递增计数器 + 加密哈希(如 SHA-256)生成伪随机数
- 可以保证唯一性(只要计数器不重复)
- 缺点:伪随机性质,不能保证真正的随机性
⚠️ 这些方法都不能保证真正的“随机”和“唯一”同时成立,需要根据业务场景权衡
6. 总结
| 方法 | 时间复杂度 | 内存消耗 | 适用场景 |
|---|---|---|---|
| 记录历史法 | O(n^2) | 中等(随生成数增长) | 小规模、低性能要求 |
| 提前洗牌法 | O(1) + O(n) 初始化 | 高 | 中小规模、需高性能 |
| 动态洗牌法 | O(1) | 中等 | 推荐方案,通用性强 |
| 哈希计数法 | O(1) | 极低 | 大规模、伪随机可接受 |
📌 选择建议:
- 如果你只需要从 1~100 中随机取 10 个不重复数,用“记录历史法”最简单
- 如果你需要从 1~10000 中取 5000 个不重复数,“动态洗牌法”是首选
- 如果你要生成 32 位随机数且不重复,“哈希 + 计数器”是唯一可行方案
📌 最后提醒:
- 不要盲目追求“完全随机”,很多场景伪随机就足够
- 如果你发现生成速度变慢,可能是你选错了算法,而不是随机函数的问题
希望你下次需要生成不重复随机数时,能快速想到这些方法中的一种。