1. 概述
在本教程中,我们将学习如何对表格或数据集中的特征进行标准化。
我们会先讨论标准化的用途以及适用场景,接着介绍三种最常见的特征标准化方法。
阅读完本文后,你将熟悉标准化的概念,并掌握其最常见实现方式的公式。
2. 标准化的基本概念
2.1. 什么是标准化?直觉上的理解
数据标准化之所以重要,是因为我们通常面对的原始数据集往往不是标准化后的。但在训练机器学习模型前,对数据进行标准化通常是非常有必要的。
我们来看一个例子:一个包含学生体重和身高的数据表:
| 学生 | 体重(kg) | 身高(cm) |
|---|---|---|
| Dotty | 89 | 182.1 |
| Hamza | 68 | 146.8 |
| Devonte | 75 | 170.5 |
| Alex | 68 | 154.8 |
| Reiss | 86 | 180.6 |
对应的散点图如下:
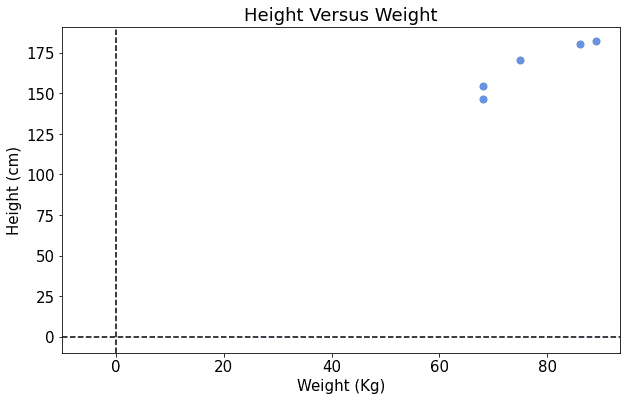
从图中可以看出,体重和身高之间似乎存在某种线性关系。我们可能想通过拟合一条直线来建模这种关系。
2.2. 参数训练的复杂性
我们考虑一个线性模型:
$$ y = ax + b $$
其中 $ a $ 是斜率,$ b $ 是截距。如果我们用随机的初始值 $ a = 0, b = 0 $ 开始训练,模型会像这样:
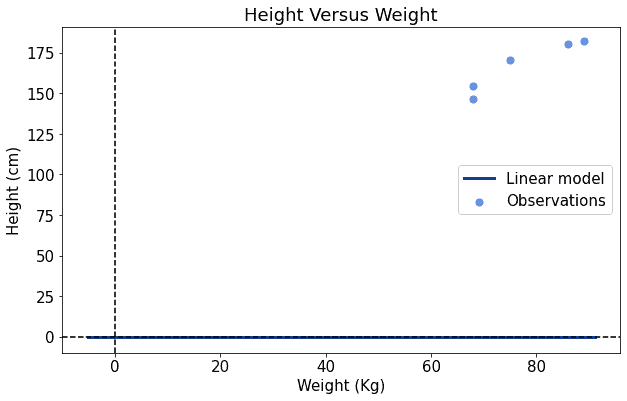
显然,这个模型离数据点差距很大。我们需要不断调整参数,直到拟合效果变好:
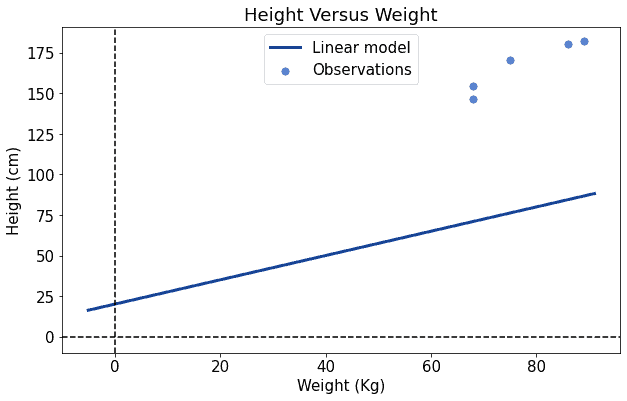
最终我们得到了一个不错的拟合结果:
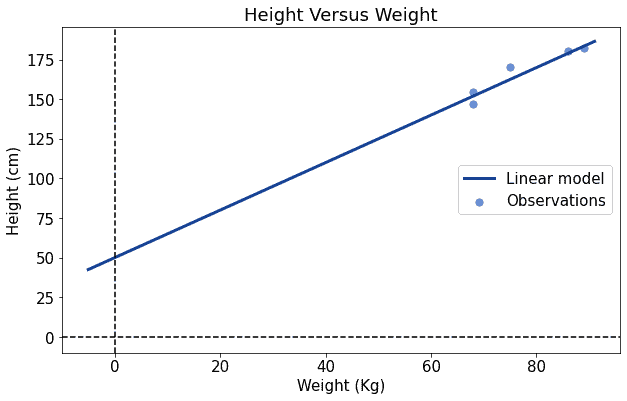
但这个过程需要多次迭代,收敛速度较慢。
2.3. 如果数据是标准化的会怎样?
现在我们来看一组经过标准化处理后的数据:
| 学生 | 体重 | 身高 |
|---|---|---|
| Dotty | 0.562 | 0.429 |
| Hamza | -0.438 | -0.571 |
| Devonte | -0.105 | 0.100 |
| Alex | -0.438 | -0.344 |
| Reiss | 0.419 | 0.386 |
对应的散点图如下:
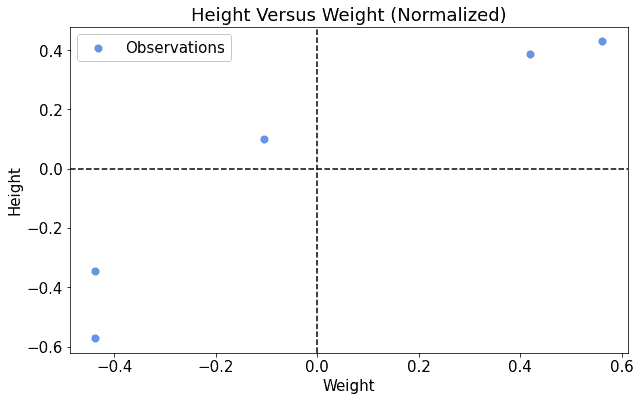
如果我们用同样的线性模型初始化参数,这次模型几乎一开始就贴近数据:
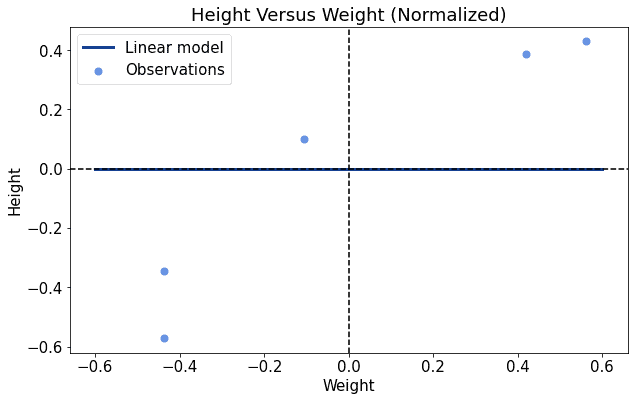
只需要稍微调整斜率就能很好地拟合数据:
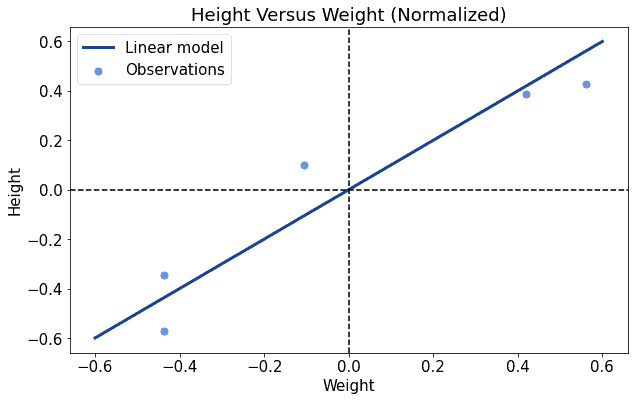
这个例子说明:标准化可以显著加快模型训练的收敛速度。
2.4. 为什么我们要做标准化?
总结一下:
✅ 标准化后的数据通常能加快模型训练
✅ 即使没有明显提升,也只是多了一些简单的数学运算(如减法和除法)
❌ 原始数据往往需要更长时间的参数搜索
所以,在没有特别理由的情况下,建议在训练模型前对数据进行标准化处理。
3. 常见误区与术语区分
3.1. 标准化 ≠ 正态分布
标准化是一个过程,它通过某种规则将原始数据映射到一个新的范围或分布。而正态分布(Normal Distribution)是一种特定的分布形态(即高斯钟形曲线)。
⚠️ 二者不能混淆。标准化不一定会得到正态分布,正态分布也不一定来自于标准化。
3.2. 标准化 vs 标准差归一化(Standardization)
这两个术语容易混淆:
- 标准化(Normalization):通常指将数据缩放到某个固定区间(如 [0, 1])
- 标准差归一化(Standardization):通常指将数据转换为均值为 0、标准差为 1 的分布(适用于正态分布)
✅ 在阅读文献或文档时,务必注意作者使用术语的上下文含义。
4. 常见标准化方法
我们来看三种最常用的标准化方法:
4.1. 缩放到 [0, 1] 区间(Min-Max Scaling)
这是最常用的标准化方法之一,公式如下:
$$ f(x) = \frac{x - \min(x)}{\max(x) - \min(x)} $$
✅ 适用于数据分布不均匀、但无明显异常值的情况
❌ 对异常值敏感(极值会拉低其他值的缩放比例)
下图展示了对体重和身高的 Min-Max 标准化结果:
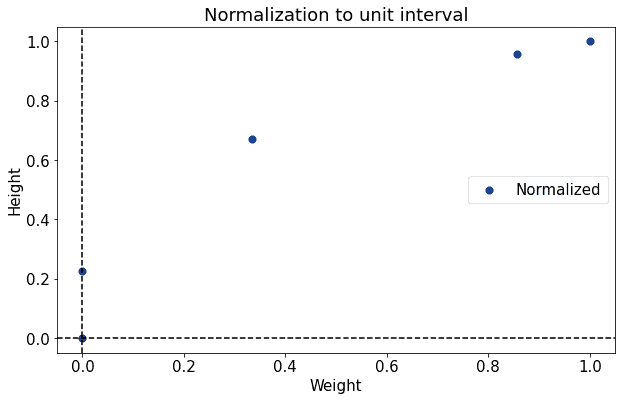
⚠️ 注意:如果 max(x) == min(x),会导致除以 0,需做异常处理。
4.2. 均值归一化 + 特征缩放(Mean Normalization with Feature Scaling)
该方法将数据中心化在均值附近,并缩放至 [0, 1] 范围:
$$ f(x) = \frac{x - \mu}{\max(x) - \min(x)} $$
其中 $ \mu $ 是特征的均值。
✅ 可以突出数据与均值的偏离
✅ 适用于数据有明显集中趋势的场景
4.3. 标准差归一化(Z-Score Normalization)
该方法利用均值和标准差进行标准化:
$$ f(x) = \frac{x - \mu}{\sigma} $$
其中 $ \mu $ 是均值,$ \sigma $ 是标准差。
✅ 适用于数据近似服从正态分布的情况
✅ 标准化后数据均值为 0,标准差为 1
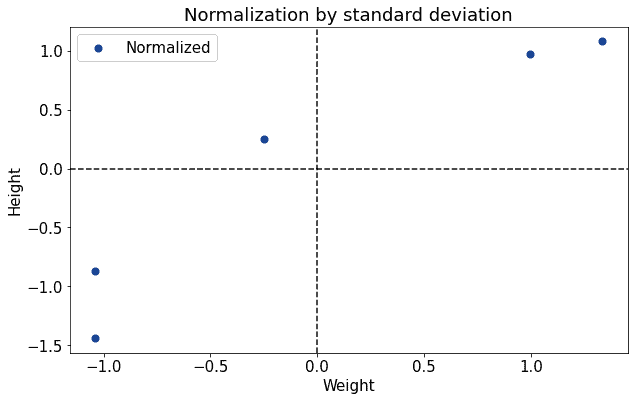
下图展示了使用 Z-Score 标准化后的双变量分布:
4.4. 如何选择合适的方法?
选择标准化方法通常取决于任务本身和数据分布特性。建议:
✅ 在新数据集上尝试多种方法
✅ 比较模型训练速度和性能
✅ 选择效果最佳的方案
5. 总结
在本文中,我们学习了:
- 什么是标准化,以及它为何重要
- 标准化与正态分布、标准差归一化的区别
- 三种常见的标准化方法及其适用场景
- 如何选择最适合的标准化方式
标准化是数据预处理的重要一环,合理使用可以显著提升模型训练效率和性能。