1. 简介
AI 相关的话题几乎每周都会出现在新闻中,不仅热度不减,可用的技术工具也越来越多。如今,我们有众多框架、库、平台可供部署和测试。面对如此多的选择,如何挑选出最适合当前项目需求的工具,往往是一个挑战。
如果我们每次都要手动实现神经网络结构、梯度计算、每一层的具体实现,那将是非常低效且容易出错的。与其花时间在数学公式编码和调试小 Bug 上,不如借助成熟工具来提升模型的准确性和输出质量。本文将介绍几款主流的 AI 引擎,分析它们的特点、适用人群,并帮助你为下一个项目选择合适的工具。
✅ 核心观点:选择 AI 工具时,需综合考虑开发经验、项目需求、性能要求、是否支持可视化等。
2. Keras
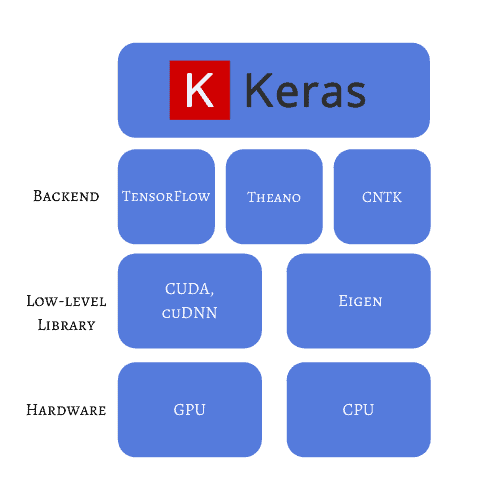
Keras 的宣传语是“为人类而非机器设计的”,它提供了高度抽象的接口,底层基于 TensorFlow 2 实现。它的目标是让开发者能够快速实现想法,特别是在常见的使用场景中。
Keras 的优势在于灵活性和易用性。例如,你可以用少量代码实现一个基于 CT 扫描的 3D 图像分类任务。YouTube 和 NASA 等大型组织也在其工作流中使用 Keras,因为它可以利用 GPU 或 TPU 加速运算,具备良好的扩展性。
此外,Keras 提供了图像、时间序列和文本数据的预处理功能,并内置了一些小型数据集(如 MNIST、CIFAR-10),非常适合用于测试模型原型。
✅ 适用人群:熟悉 Python,对机器学习有一定了解的开发者。
示例代码:
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=(784,)),
layers.Dense(10, activation='softmax')
])
3. OpenNN
OpenNN 是一个用 C++ 编写的开源神经网络库,适用于对性能有高要求的项目。
它适用于多种机器学习任务,例如:
- 回归:根据年龄预测员工薪资
- 分类:判断一封邮件是否为垃圾邮件
- 预测:预测公司股价走势
- 关联分析:根据用户购买记录预测可能购买的其他商品
OpenNN 提供了五个核心类用于模型构建和测试:数据集(DataSet)、神经网络(NeuralNetwork)、训练策略(TrainingStrategy)、模型选择(ModelSelection)、测试分析(TestingAnalysis)。
✅ 适用人群:熟悉 C++ 并具备机器学习基础知识的开发者。
4. DL4J(Deep Learning for Java)
考虑到 Java 仍然是世界上最广泛使用的编程语言之一,DL4J 的存在非常合理。
DL4J 是一个基于 JVM 的分布式深度学习库,底层使用 C、C++ 和 CUDA 实现,支持在 CPU 和 GPU 上加速训练。它还支持与 Apache Spark、Hadoop 等分布式计算框架集成。
DL4J 支持构建多种神经网络结构,包括卷积网络、循环网络、变分自编码器等。它还提供了模型加载、参数冻结、微调等实用功能。
✅ 亮点功能:提供基于 Spark 的可视化界面,可在浏览器中实时查看训练进度。
文档地址:DL4J 官方文档
示例代码:
MultiLayerNetwork model = new NeuralNetConfiguration.ListBuilder()
.layer(new DenseLayer.Builder().nIn(784).nOut(256).build())
.layer(new OutputLayer.Builder().nIn(256).nOut(10).build())
.build();
5. Amazon Machine Learning(Amazon ML)
Amazon ML 是 AWS 提供的一整套机器学习服务,涵盖模型构建、训练和部署全流程。它的一大优势是无需掌握神经网络原理即可使用 AI 功能。
它适用于欺诈检测、业务预测、图像分析等场景。但需要注意的是,它并非开源工具,免费版功能受限。
⚠️ 缺点:无法自定义模型结构、损失函数或优化器,灵活性较差。
6. Azure Machine Learning Studio
Azure ML Studio 是微软提供的端到端机器学习平台,支持拖拽式操作,非常适合快速原型开发。
它内置了自动机器学习(AutoML)功能,可自动完成特征工程、算法选择和超参数调优。结合内置的 DevOps 支持,可实现快速部署。
它也支持与开源框架集成,如 ONNX、TensorFlow、PyTorch,以及通过 Jupyter Notebook 进行 Python 或 R 编程。
⚠️ 缺点:免费版资源受限。
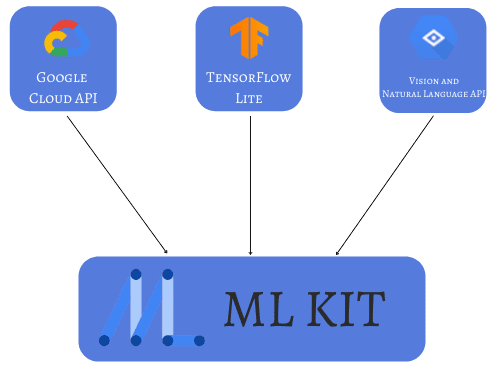
7. Google ML Kit
Google ML Kit 是一款面向移动端开发者的 SDK,支持 Android 和 iOS 平台,旨在让开发者轻松集成 AI 功能。
例如,只需几行代码即可实现人脸识别、文本识别、图像分类等任务。它也支持使用低级 API 自定义模型结构。
ML Kit 提供两种主要 API:
- Vision API:用于图像标注、文字识别、物体检测等
- Natural Language API:用于翻译、回复建议等
✅ 优势:支持云端和本地部署,即使在无网络环境下也能运行。
⚠️ 建议:虽然不需要成为神经网络专家,但最好具备一定的 ML 基础知识。
示例图片:
8. 总结
选择 AI 引擎时,需综合考虑以下几个因素:
| 考量维度 | 说明 |
|---|---|
| 开发语言 | 如 Python、C++、Java、移动端语言等 |
| 项目需求 | 是否需要高性能、可视化、分布式训练等 |
| 使用门槛 | 是否需要 ML 专业知识 |
| 是否开源 | 是否允许定制化、修改源码 |
| 部署环境 | 是否支持云端、移动端、本地部署 |
✅ 建议:如果你对 AI 技术有一定了解,推荐使用 Keras 或 DL4J;如果希望快速上手,可以考虑 Amazon ML 或 Azure ML;如果是移动端开发,Google ML Kit 是理想选择。
最后,掌握 AI 基础知识将大大提升你对工具的掌控力,也能更高效地调参、优化模型,提升训练效率与准确率。