1. 概述
在本教程中,我们将讨论一个经典问题:如何获取二叉树中从根节点到某个目标节点的路径。该问题在实际开发中常用于树结构遍历、路径查找等场景。
我们会介绍两种主要思路:
- 自顶向下(Top-Down):从根节点出发,使用 DFS 遍历查找目标节点
- 自底向上(Bottom-Up):从目标节点出发,逐级向上回溯到根节点
同时,我们还会讨论一个变种问题:找出所有从根节点出发,路径节点值之和等于目标值的路径。
2. 定义
在二叉树中,从根节点到目标节点的路径是指从根开始,沿着子节点关系,直到目标节点的一系列节点。
例如,考虑如下二叉树:
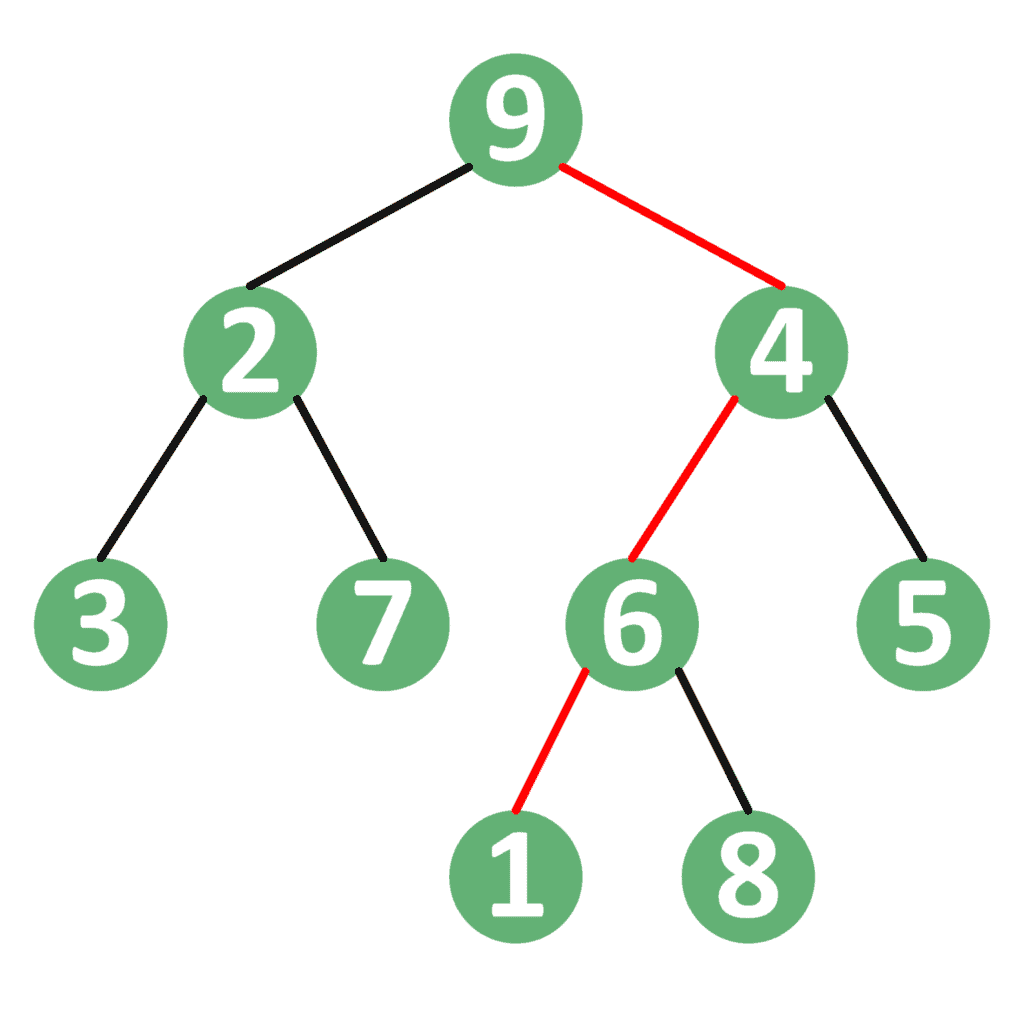
- 根节点为
9,要查找节点1的路径,路径为:9 → 4 → 6 → 1 - 要查找节点
7的路径,路径为:9 → 2 → 7
需要注意的是:
✅ 树是无环无向图,因此从根到任意节点只有一条路径
✅ 自顶向下和自底向上两种方法各有适用场景,取决于节点是否保存父节点信息
3. 查找从根到目标节点的路径
我们的问题描述如下:
给定一个二叉树的根节点和一个目标节点,返回从根到目标节点的路径(节点列表)
3.1. 自顶向下法(Top-Down)
使用 DFS 从根节点出发,递归查找目标节点。
✅ 实现逻辑:
- 初始化一个
path列表记录当前路径 - DFS 遍历左子树、右子树
- 找到目标节点后返回路径
- 若当前路径不包含目标节点,则回溯(删除当前节点)
Java 示例代码:
public class BinaryTreePath {
private List<TreeNode> path = new ArrayList<>();
public List<TreeNode> findPath(TreeNode root, TreeNode target) {
if (dfs(root, target)) {
return path;
}
return null;
}
private boolean dfs(TreeNode node, TreeNode target) {
if (node == null) return false;
path.add(node);
if (node == target) return true;
boolean found = dfs(node.left, target) || dfs(node.right, target);
if (!found) path.remove(path.size() - 1);
return found;
}
}
⚠️ 时间复杂度:
- **O(n)**,其中
n是树中节点数 - 最坏情况下需遍历所有节点
3.2. 自底向上法(Bottom-Up)
从目标节点出发,逐级向上回溯到根节点。
✅ 适用前提:
- 每个节点必须保存父节点引用
- 可以快速获取目标节点
Java 示例代码:
public List<TreeNode> findPathFromBottom(TreeNode root, TreeNode target) {
List<TreeNode> path = new ArrayList<>();
TreeNode current = target;
while (current != root) {
path.add(current);
current = current.parent;
}
path.add(root);
Collections.reverse(path);
return path;
}
⚠️ 时间复杂度:
- **O(h)**,其中
h是树的高度 - 不需要遍历整棵树,效率更高
3.3. 方法对比
| 方法 | 时间复杂度 | 是否需要父节点 | 是否推荐 |
|---|---|---|---|
| 自顶向下法 | O(n) | ❌ | ✅ |
| 自底向上法 | O(h) | ✅ | ✅ |
✅ 自底向上法效率更高,但依赖节点保存父节点信息
❌ 若无法获取父节点或目标节点,建议使用自顶向下法
4. 查找路径和为目标值的所有路径
另一个常见问题是:
找出所有从根节点出发,路径节点值之和等于目标值的路径
4.1. 自顶向下法(Top-Down)
使用 DFS 记录路径和,一旦满足目标值则保存路径。
Java 示例代码:
public class BinaryTreeSumPath {
private List<TreeNode> path = new ArrayList<>();
private List<List<TreeNode>> result = new ArrayList<>();
public List<List<TreeNode>> findPaths(TreeNode root, int targetSum) {
dfs(root, 0, targetSum);
return result;
}
private void dfs(TreeNode node, int currentSum, int target) {
if (node == null) return;
path.add(node);
currentSum += node.val;
if (currentSum == target) {
result.add(new ArrayList<>(path));
}
dfs(node.left, currentSum, target);
dfs(node.right, currentSum, target);
path.remove(path.size() - 1);
}
}
⚠️ 时间复杂度:
- **O(n × h)**,其中
n是节点数,h是树的高度 - 每次路径匹配需拷贝路径,最坏情况下路径数为
n,每条路径长度为h
4.2. 自底向上法(Bottom-Up)
❌ 不适用
原因:
- 无法确定目标节点(没有具体节点)
- 每个节点都要作为起点尝试向上查找,效率远低于自顶向下法
- 需要访问所有节点并维护父节点引用,实现复杂度高
5. 总结
| 问题类型 | 推荐方法 | 时间复杂度 | 说明 |
|---|---|---|---|
| 查找从根到指定节点的路径 | Bottom-Up | O(h) | 需保存父节点信息 |
| 查找路径和为目标值的路径 | Top-Down | O(n × h) | 更适合DFS遍历 |
| 查找所有路径 | Top-Down | O(n × h) | DFS最常用 |
✅ Bottom-Up 更快但依赖父节点引用
✅ Top-Down 更通用但效率略低
❌ Bottom-Up 不适用于路径和问题
如果你的树节点结构中没有父节点引用,或无法快速定位目标节点,建议优先使用 DFS 自顶向下法。