1. 简介
在信号处理中,一个常见的挑战是识别时间或空间中的关键点,例如峰值(peak)。这些点代表局部最大值(或最小值),在特定场景下具有明确的物理或逻辑意义。
举个例子,假设我们有一个可控的红外摄像头,目标是自动调整其方向,使其画面中包含尽可能多的热点(hotspot)。这里的“热点”其实就是图像上的一个局部最大值。因此,这个问题可以表述为:“调整摄像头方向,使检测到的峰值数量最大化”。
在本文中,我们将探讨几种实现峰值检测的可行技术方案,并分析其算法复杂度。
2. 定义说明
信号可以是一维、二维,甚至是多维的。在1D情况下,峰值检测已经不算简单,但在2D空间中,问题会更加复杂。更高维度的信号则通常用于科研领域,术语也会发生变化,比如“峰值”可能演变为“高密度区域(hyperdensity)”。
此外,信号可以是连续的(continuous),也可以是量化(quantized)的。连续信号通常以闭合公式表示,可以对任意点进行评估;而量化信号,如图像,则受限于分辨率和取值范围。
本文聚焦于二维量化信号,即图像,讨论以像素为单位的峰值检测。
2.1. 峰值(Peak)
峰值是指图像中某一点,其周围所有像素值都比它小:
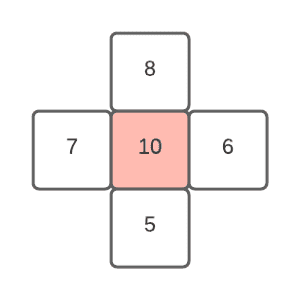
像素值的范围取决于应用场景。例如,普通灰度图像使用8位(值范围为0255),而科学应用可能使用64位浮点数(范围通常为01)。
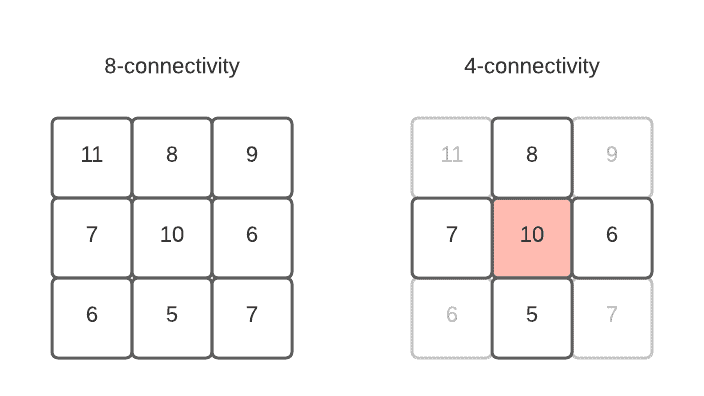
2.2. 像素连通性(Pixel Connectivity)
“周围像素”这个概念其实并不唯一。有两种常见定义方式:
- 4连通:仅包括上下左右四个方向的像素
- 8连通:包括所有八个相邻方向的像素
例如,下图展示了一个在4连通下是峰值、但在8连通下不是峰值的情况:
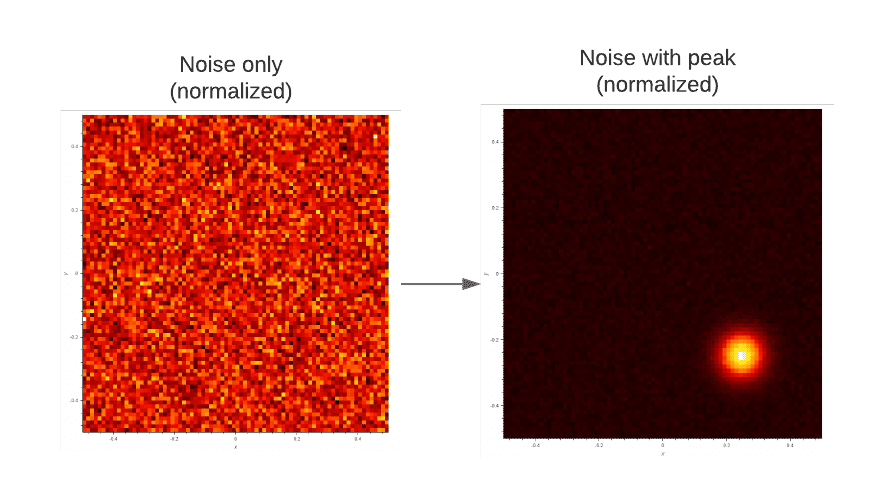
2.3. 噪声(Noise)
噪声是信号中非预期的变化。以红外摄像头为例,当我们对准一面白墙时,理论上图像应该是均匀的,但由于噪声的存在,可能会有很多像素被误判为峰值。实际中,真正的峰值通常会覆盖一个区域,这有助于我们将其与噪声区分开:
2.4. 图像中的峰值数量
前面提到“检测到的峰值数量”,这说明我们可能不知道图像中实际存在多少个峰值。根据不同的需求,我们可能面临以下几种情况:
- 恰好有
p个峰值 - 最多有
p个峰值 - 至少有
p个峰值
其中 p 是一个正整数。
例如,在宠物脚印的压力图像中,我们的目标是检测五个脚趾,即我们明确知道需要找5个峰值,这在后续分析中非常重要。
3. 峰值检测算法
不同的场景需要不同的算法策略。下面我们将介绍几种常见方法,并分析其优缺点。
3.1. 最大值法(Maximum Value)
如果图像中只有一个峰值,那我们只需找到图像中的最大值即可。
✅优点:简单高效
❌缺点:仅适用于单峰值场景
该方法的复杂度为线性:O(m × n),其中 m 是列数,n 是行数。
3.2. 局部最大值法(Brute Force Local Maxima)
如果我们想找出所有峰值(包括全局和局部),就需要对每个像素检查其周围8个或4个像素是否都小于它。
✅优点:可找出所有峰值
❌缺点:容易受噪声影响,误检多
复杂度同样是 O(m × n),但每一步的判断更复杂。
3.3. 高斯拟合(Gaussian Fit)
如果假设峰值符合高斯分布,我们可以通过拟合高斯曲线来精确定位峰值,并过滤掉不符合分布的“假峰”。
✅优点:可提高精度,过滤噪声
❌缺点:计算开销大,依赖分布假设
适合科学图像处理,如显微图像分析。
3.4. 快速查找一个峰值(Divide and Conquer)
如果我们只需要找到任意一个峰值,可以采用分治策略:
algorithm FindPeak(image):
// INPUT
// image = a 2D matrix representing the image
// OUTPUT
// (i, j) = coordinates of a 2D peak
m <- image.cols
j <- m / 2
(i, j) <- globalMax(j)
if image[i, j-1] < image[i, j] and image[i, j+1] < image[i, j]:
return (i, j) // as a 2D-peak
if image[i, j-1] > image[i, j]:
return FindPeak(image left to column j)
if image[i, j+1] > image[i, j]:
return FindPeak(image right to column j)
该算法从图像中间列开始,寻找该列最大值,然后判断是否是峰值。如果不是,就向值更大的方向继续查找。最终可以保证找到一个峰值,但不一定是全局最大值。
✅优点:速度快
❌缺点:只能找到一个峰值
复杂度分析如下:
- 每次查找列最大值需
O(n)时间 - 每次将列数减半,最多
log₂(m)次 - 总体复杂度为
O(n × log₂m)
3.5. 互相关法(Cross-correlation)
如果我们知道峰值的大致形状,可以将其作为模板进行匹配。这其实就是卷积(convolution)操作。
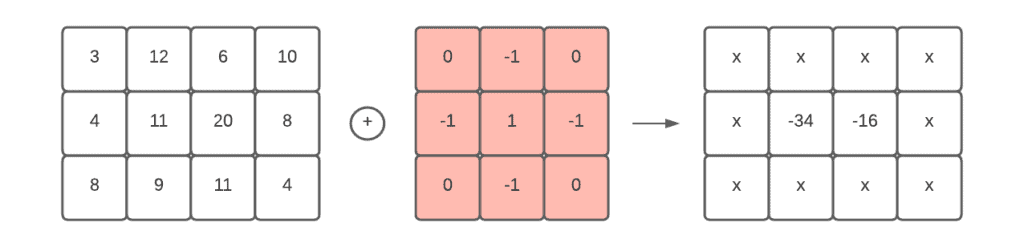
我们定义一个“核(kernel)”,在图像上滑动并计算相似度。最后设定一个阈值,筛选出高于该值的像素点作为候选峰值。
✅优点:适合模板匹配
❌缺点:参数敏感,不够灵活
最简单的实现方式是滑动窗口逐点计算,复杂度仍为 O(m × n)。
4. 总结
图像中的峰值检测是一个常见的图像处理问题。本文介绍了几种常见方法及其适用场景:
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 最大值法 | 快速简单 | 仅适用于单峰 | 单一热点检测 |
| 局部最大值法 | 找出所有峰值 | 易受噪声干扰 | 多峰检测 |
| 高斯拟合 | 精确、可过滤噪声 | 计算量大 | 科学图像分析 |
| 分治查找 | 快速找到一个峰值 | 不保证是最大值 | 快速定位 |
| 互相关 | 模板匹配有效 | 参数敏感 | 已知形状检测 |
在实际应用中,也可以结合多种方法,比如先用局部最大值法找出所有候选点,再用高斯拟合精确定位。对于更复杂的场景,还可以使用遗传算法、梯度下降等优化方法。