1. 简介
在本篇教程中,我们将深入理解计算机视觉系统中的人体姿态估计(Human Pose Estimation)是如何工作的。我们会学习如何从图像或视频中推断出人体的姿态及其含义,并探讨深度学习技术如何改变了姿态估计的流程。
文章内容适合有一定计算机视觉基础的开发人员或研究人员阅读,部分内容会涉及模型结构、数据流程以及常见挑战,旨在为读者提供一套系统性的认知框架。
2. 姿态估计概述
姿态估计(Pose Estimation)是计算机视觉中的一个基础问题,其目标是识别物体或人体的位置和方向。
在人体姿态估计中,我们通常通过估计手、头、肘等关键点的位置来实现。这些关键点构成了人体的骨架结构,是模型需要追踪的核心目标。
姿态估计模型接收图像或视频作为输入,输出检测到的各个关节的坐标,并附带一个置信度评分,用于表示估计的可靠性。我们也可以将姿态估计理解为:确定相机相对于特定人物或物体的位置和方向。
2.1. 人体姿态估计
人体姿态估计的目标是在图像或视频中识别并分类人体各部位和关节的位置。通常采用基于模型的方法来表示和推断人体在2D和3D空间中的姿态。
人体是一种柔性物体,当手臂或腿部弯曲时,各个关键点之间的相对位置会发生变化。因此,姿态估计模型必须具备处理这种动态变化的能力。
2.2. 2D与3D人体姿态估计
- 2D姿态估计:从图像或视频中估计人体关键点在二维空间中的位置。模型输出每个关键点的X和Y坐标。
- 3D姿态估计:在2D基础上增加Z轴(深度),模拟物体在三维空间中的姿态。3D估计更具挑战性,涉及复杂的参数建模和数据集构建。
传统方法依赖于手工特征提取和图模型,现代方法则多采用深度学习模型,显著提升了单人和多人姿态估计的性能。
2.3. 人体姿态估计的重要性
姿态估计在多个领域有广泛应用,如自动驾驶、行为识别、运动分析等。相比传统的物体检测(仅提供边界框),姿态估计能提供更细粒度的信息(如关节坐标),因此在需要精确动作分析的场景中尤为重要。
2.4. 自底向上 vs 自顶向下方法
| 方法 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 自底向上(Bottom-up) | 先检测所有关键点,再聚类为个体 | 效率高,适合多人场景 | 难以处理遮挡或密集场景 |
| 自顶向下(Top-down) | 先检测人体边界框,再估计关键点 | 准确性高 | 计算开销大,依赖检测器性能 |
3. 姿态的定义方式
在计算机视觉和机器人学中,姿态(Pose)通常指物体的位置和方向组合。姿态估计的目标就是确定物体在特定坐标系下的位置和方向。
3.1. 姿态定义的基本思想
姿态定义模型需具备鲁棒性,能够应对不同体型、肢体长度变化、遮挡等现实挑战。当前主流方法包括:
- 绝对姿态估计:直接预测关键点在全局坐标系下的位置。
- 相对姿态估计:基于参考姿态进行偏移预测。
- 混合姿态估计:结合以上两种方式。
3.2. 区域模型(Area Models)
区域模型使用轮廓来估计2D姿态,通常将人体各部位建模为矩形,近似表示人体形状。例如,Active Shape Model(ASM) 使用主成分分析记录人体轮廓变化。
3.3. 体积模型(Volumetric Models)
体积模型用于3D姿态估计,常见的如GHUM(Generative Human Model)模型,使用几何网格表示人体结构,支持深度学习训练和3D姿态恢复。
3.4. 骨架模型(Skeleton-Based Models)
骨架模型使用关节位置和肢体方向来表示人体结构,适用于2D和3D姿态估计。例如:
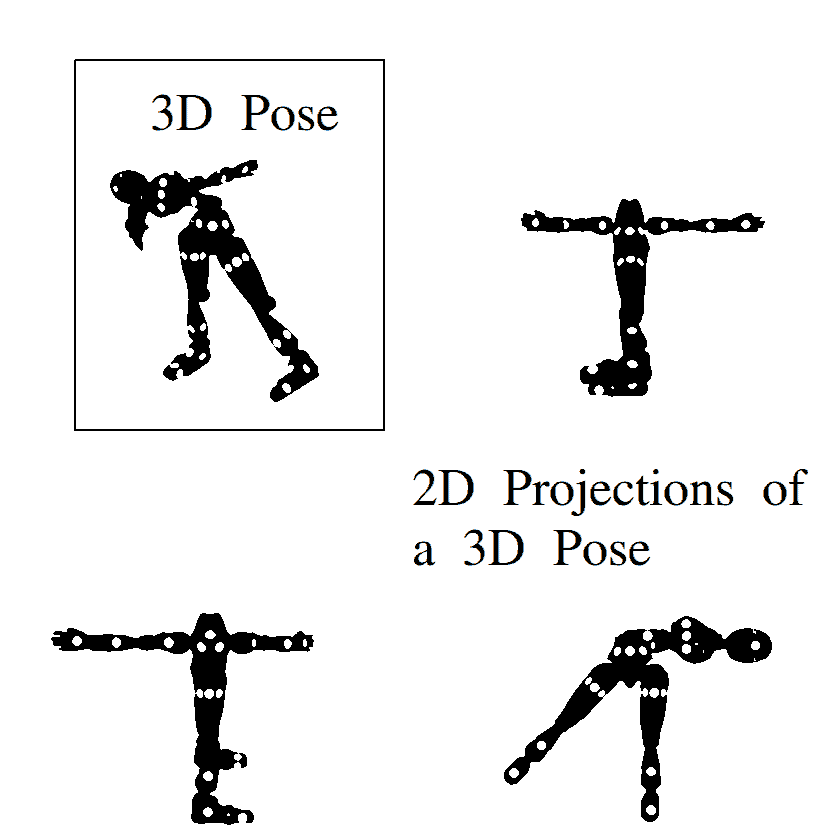
这类模型广泛应用于运动分析、动作识别等场景,例如运动员动作评估。
3.5. 单人 vs 多人姿态估计
- 单人姿态估计:输入图像中仅包含一个目标,处理相对简单。
- 多人姿态估计:需要同时检测和估计多个个体的姿态,流程如下:

第一阶段使用卷积网络预测2D关键点和3D初步表示;第二阶段使用全连接网络预测每个个体的3D姿态。
4. 姿态估计流程(Pipeline)
姿态估计流程通常包括以下四个主要步骤:

4.1. 姿态主体隔离
首先从图像或视频帧中提取包含人体的边界框(Bounding Box):

这一步是关键,因为姿态模型通常只处理单个目标。
4.2. 原始姿态估计
使用姿态定义模型对每个边界框进行关键点检测,生成姿态的视觉表示。
4.3. 姿态识别与语义映射
将检测到的姿态与已有的姿态库进行比对,赋予其语义含义。例如:
通过模型比对机制,确定姿态所属的动作类别。
5. 基于深度学习的姿态估计
深度学习模型具有强大的函数逼近能力,可以将原本用于分类任务的卷积神经网络(CNN)用于定位任务。
5.1. 基本流程
- 数据收集:姿态估计高度依赖标注数据(关键点坐标)。
- 数据预处理:包括图像归一化、关键点对齐等。
- 模型训练:选择合适的网络结构(如HRNet、SimpleBaseline)和损失函数(如MSE、L1 Loss)。
- 验证与调优:通过验证集评估模型性能,并调整超参数。
5.2. 基于上下文的姿态识别
不同的活动通常对应不同的姿态。例如,在足球比赛中,跑动和踢球的姿势更常见,而坐着的姿势较少。
问题: 如果模型知道图像属于某个活动类别(如“篮球”),是否能提升姿态估计的准确性?
✅ 答案是肯定的。通过引入上下文信息,可以增强模型对关键点位置的预测能力。
6. 总结
本文系统讲解了人体姿态估计的基本原理、模型类型、处理流程以及深度学习的应用。总结如下:
- 姿态估计的目标是识别人体关键点的位置和方向。
- 分为2D和3D两种形式,各有优劣。
- 模型类型包括区域模型、体积模型、骨架模型。
- 处理流程包括:目标检测、姿态估计、语义映射。
- 深度学习显著提升了姿态估计的精度和效率,但也面临数据不足、遮挡等问题。
- 上下文信息(如活动类型)有助于提升模型性能。
如果你是计算机视觉从业者或研究者,建议关注当前主流模型(如HRNet、SimpleBaseline、PoseNet)并结合具体业务场景进行调优和部署。