1. 引言
在计算机科学中,许多问题涉及将任意空间划分为多个区域。这类问题在计算机图形学、图像处理、游戏开发以及地理空间分析等领域频繁出现。
以基于位置的服务为例,比如 Google Maps,它需要处理数以百万计基于空间坐标的查询请求。比如,查找某个区域内所有超市的位置。同时为数百万用户实时处理这类查询,显然是一项极具挑战性的任务。
正是在这种背景下,Quadtrees(四叉树)和 Octrees(八叉树)成为现代软件开发中的基础数据结构。它们提供了一种高效分解和查询空间信息的方法。在本教程中,我们将深入探讨这些结构的工作原理以及它们为何如此有用。
2. 一维情况
为了便于理解,我们先从一个简单的一维例子入手。假设我们要将一个数轴从 1 到 6 的区间进行划分,目标是构建一种结构,可以高效地支持区间查找。
由于数轴本身是有序的,最高效的划分方式是每次从中间切分。 如果递归进行这种划分,并将每个区间作为节点存储在 二叉搜索树 中,我们就能得到如下结构:
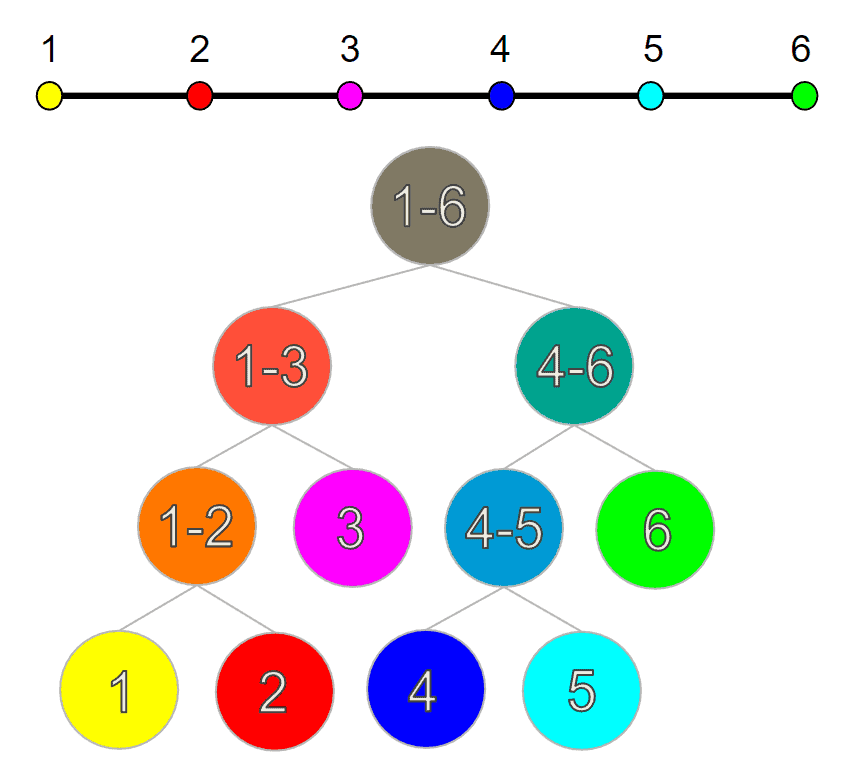
这种结构确实能让我们在数轴上进行快速的区间查找。但这只是一个一维的例子,我们不禁要问:如何将这一思想推广到二维或更高维度?
3. 二维情况
举个例子:假设我们在一个二维平面上随机分布了一些点,我们的目标是高效地查找某个二维区域内包含哪些点。
为了实现类似一维中的高效查找,我们同样可以使用递归划分的方式。 不过这次我们要在两个轴上都进行划分。每次划分都会将当前区域均等地分成  个象限(quadrants),如下图所示:
个象限(quadrants),如下图所示:
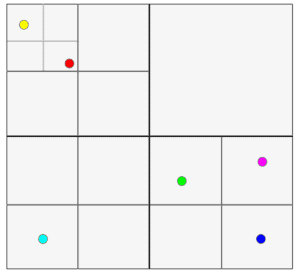
为了存储这些子区域,我们仍然使用树结构,只不过每个节点必须恰好有四个子节点,分别对应四个象限;如果该节点是叶子节点,则没有子节点。这种结构就被称为 Quadtree(四叉树)。
3.1 构建 Quadtree
要构建一个 Quadtree,首先我们需要定义一些基本的数据结构,比如包含 x 和 y 坐标的二维点,以及用于描述区域边界的包围盒(bounding box):

接着定义 Quadtree 类本身,并设定每个子区域最多能容纳的点数。我们从一个单位正方形作为根节点开始,递归地插入点。如果当前区域未达到容量上限且没有进一步划分,则直接插入点;否则进行划分,并递归地将点插入到合适的子节点中:

4. 三维情况
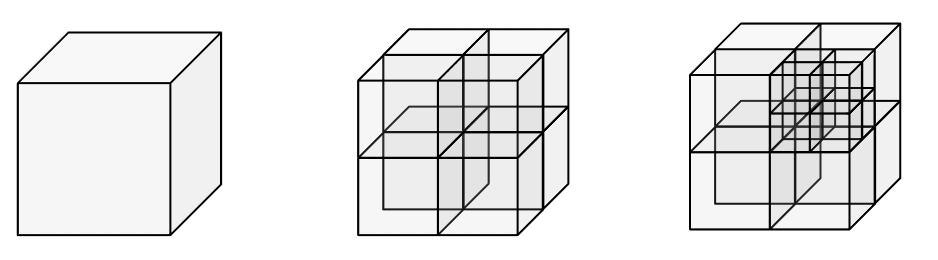
即使我们进入三维空间,比如在一个真实世界的物理模拟中,我们依然可以沿用同样的策略。 唯一的不同是:这次我们要将空间划分为  个八分之一空间(octants),并用树结构来表示这些区域。这种结构被称为 Octree(八叉树):
个八分之一空间(octants),并用树结构来表示这些区域。这种结构被称为 Octree(八叉树):
5. 小结
本文我们探讨了基于递归空间划分的两种重要数据结构:Quadtrees 和 Octrees。通过具体的示例说明了它们为何能在计算机科学的多个领域中成为高效处理空间数据的首选结构。无论是地图服务、游戏开发,还是物理模拟,它们都扮演着关键角色。掌握其原理,对于解决实际问题非常有帮助。