1. 简介
QuickSelect 是一种用于查找 n 个元素数组中第 k 大元素 的算法,也被称为 Hoare 选择算法,由其发明者命名。
它与快速排序(QuickSort)类似,区别在于 QuickSort 在每次划分后会递归处理两个子数组,而 QuickSelect 只处理包含目标第 k 大元素的那个子数组。
本文将分析 QuickSelect 的:
- 最坏情况时间复杂度
- 最好情况时间复杂度
- 平均情况时间复杂度
2. QuickSelect 算法流程
QuickSelect 的核心逻辑如下:
algorithm QuickSelect(a, ℓ, h, k):
// a = 输入数组
// ℓ = 子数组起始索引(初始为 1)
// h = 子数组结束索引(初始为 n)
// k = 要找的第 k 大元素
if ℓ == h:
return a[ℓ]
else if ℓ < h:
p <- 选择一个 pivot,划分数组并返回 pivot 的新索引
if k == p:
return a[p]
else if k < p:
return QuickSelect(a, ℓ, p-1, k) // 递归左子数组
else:
return QuickSelect(a, p+1, h, k) // 递归右子数组
下图展示了 QuickSelect 的执行过程:
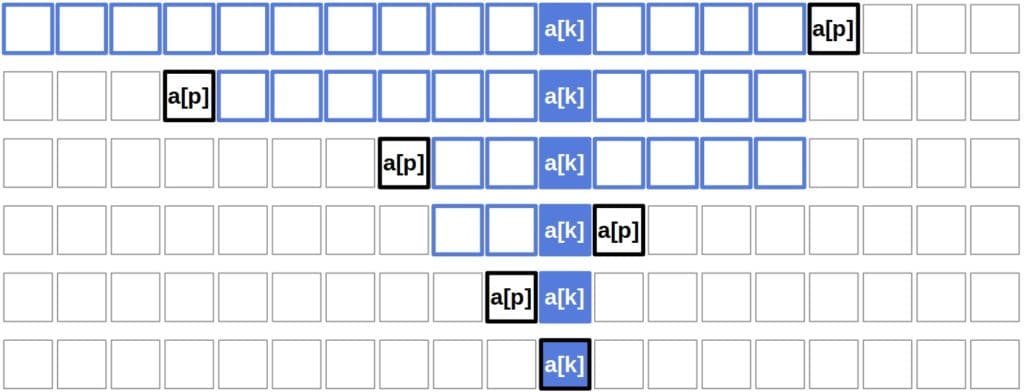
2.1. 划分方法(Partitioning)
本文使用 Lomuto 分区法,并随机选择 pivot。该方法逻辑如下:
algorithm LomutoPartitioning(a, ℓ, h):
// a = 输入数组
// a[ℓ:h] = 子数组
// ℓ < h
Randomly select r from {ℓ, ℓ+1, ..., h}
Swap a[h] with a[r]
x <- a[h] // pivot
k <- ℓ - 1
for j <- ℓ to h - 1:
if a[j] <= x:
k <- k + 1
Swap a[j] with a[k]
Swap a[k + 1] with a[h]
return k + 1
Lomuto 分区法易于分析,虽然还有其他方法(如 Hoare 分区),但它们的复杂度相近或分析方式类似。
3. 最坏情况复杂度分析
3.1. 最坏情况结构
QuickSelect 每次递归调用都会缩小子数组范围。最坏情况是:
- 每次只排除一个元素(即 pivot 不是目标元素)
- 总共进行 n 次递归调用
这意味着每次划分后,pivot 总是位于当前子数组的最左或最右端。
3.2. 复杂度推导
Lomuto 分区复杂度为 Θ(n),每次递归减少 1 个元素,因此:
$$ T(n) = \Theta(n) + T(n-1) $$
展开递归得:
$$ T(n) = \Theta(n) + \Theta(n-1) + \cdots + \Theta(1) = \Theta\left(\frac{n(n+1)}{2}\right) = \Theta(n^2) $$
✅ 结论:QuickSelect 在最坏情况下时间复杂度为 O(n²)
4. 最好情况复杂度分析
如果第一次划分就选中了目标元素作为 pivot,算法只需一次划分即可完成。
此时复杂度为:
$$ T(n) = \Theta(n) $$
✅ 结论:QuickSelect 在最好情况下时间复杂度为 O(n)
5. 平均情况复杂度分析
5.1. 什么是平均情况?
平均情况指的是算法在所有可能输入上的期望复杂度。通常假设输入是随机的(均匀分布)。
也可以通过随机化策略(如随机选择 pivot)来确保算法行为与输入无关。
5.2. 分析模型
我们假设输入数组中所有元素互不相同,可以看作是 {1, 2, ..., n} 的一个排列。
每次划分中 pivot 是随机选择的,其位置在 [ℓ, h] 内服从均匀分布。
我们只分析比较次数,因为交换次数不会超过比较次数。
定义随机变量:
$$ X_{i,j} = \begin{cases} 1, & \text{元素 } i \text{ 和 } j \text{ 被比较过} \ 0, & \text{否则} \end{cases} $$
总比较次数为:
$$ \sum_{i=1}^{n-1}\sum_{j=i+1}^{n} X_{i,j} $$
期望比较次数为:
$$ C_n = E\left[\sum_{i=1}^{n-1}\sum_{j=i+1}^{n} X_{i,j}\right] = \sum_{i=1}^{n-1}\sum_{j=i+1}^{n} q_{i,j} $$
其中 $ q_{i,j} $ 是 $ X_{i,j} = 1 $ 的概率。
5.3. 计算 q_{i,j}
考虑三种情况:
- $ k \leq i < j $
- $ i < j \leq k $
- $ i < k < j $
在每种情况下,只有当 $ i $ 或 $ j $ 被优先选为 pivot 时,才会比较它们。
计算得:
$$ q_{i,j} = \begin{cases} \frac{2}{j-k+1}, & k \leq i < j \ \frac{2}{k-i+1}, & i < j \leq k \ \frac{2}{j-i+1}, & i < k < j \end{cases} $$
将这些情况分别求和,最终可得:
$$ C_n = O(n) $$
✅ 结论:QuickSelect 在平均情况下时间复杂度为 O(n)
6. 其他分区方法与 pivot 选择策略讨论
我们分析的是使用 Lomuto 分区 的 QuickSelect,但也可以使用 Hoare 分区,它从数组两端扫描。
- Hoare 分区比 Lomuto 更少交换,但比较次数略多
- 无论哪种分区方法,QuickSelect 的时间复杂度不变
pivot 也可以不随机选择,而是固定选第一个、最后一个或中间元素。虽然复杂度相同,但随机选择在实际运行中可能更快。
使用 Median of Medians 优化最坏情况
通过 Median of Medians 算法选择 pivot,可以保证每次划分后子数组大小减少至少 30%,从而将最坏情况复杂度优化到 O(n)。
递推式为:
$$ T(n) \leq \Theta(n) + T(0.7n) $$
展开后得:
$$ T(n) = O(n) $$
✅ 结论:使用 Median of Medians 可将 QuickSelect 的最坏情况复杂度优化为 O(n)
7. 总结
| 情况 | 时间复杂度 | 说明 |
|---|---|---|
| 最坏情况 | O(n²) | 每次划分只减少 1 个元素 |
| 最好情况 | O(n) | 第一次划分就找到目标 |
| 平均情况 | O(n) | 假设输入均匀分布或 pivot 随机选择 |
| 使用 Median of Medians | O(n) | 最坏情况也线性 |
📌 结论:常规实现的 QuickSelect(使用 Hoare 或 Lomuto 分区)在最坏情况下为 O(n²),但在平均和最好情况下为 O(n);使用 Median of Medians 可保证最坏情况也为 O(n)