1. 简介
本文将比较两种经典的排序算法:快速排序(Quicksort) 和 堆排序(Heapsort)。
快速排序因其在大多数场景下性能优异而被广泛使用;而堆排序则在内存受限的场景中更受青睐。我们将分别介绍这两种算法的工作原理,并从时间复杂度、空间复杂度、实际性能等多个维度进行对比,帮助你理解它们各自的适用场景。
2. 快速排序(Quicksort)
快速排序基于分治法(Divide and Conquer)策略,其核心思想是通过一个“基准(pivot)”将数组划分为两个子数组,左边元素小于基准,右边元素大于基准,然后递归地对子数组进行排序。
其基本步骤如下:
- ✅ 选择基准(Pivot):从数组中选择一个元素作为基准
- ✅ 划分(Partition):将小于基准的元素移到其左侧,大于基准的移到右侧
- ✅ 递归处理:对左右两个子数组重复上述过程
快速排序的平均时间复杂度为 O(n log n),最坏情况下为 O(n²)(当每次选择的基准都是最值时)。
下面是一个快速排序的流程图示:
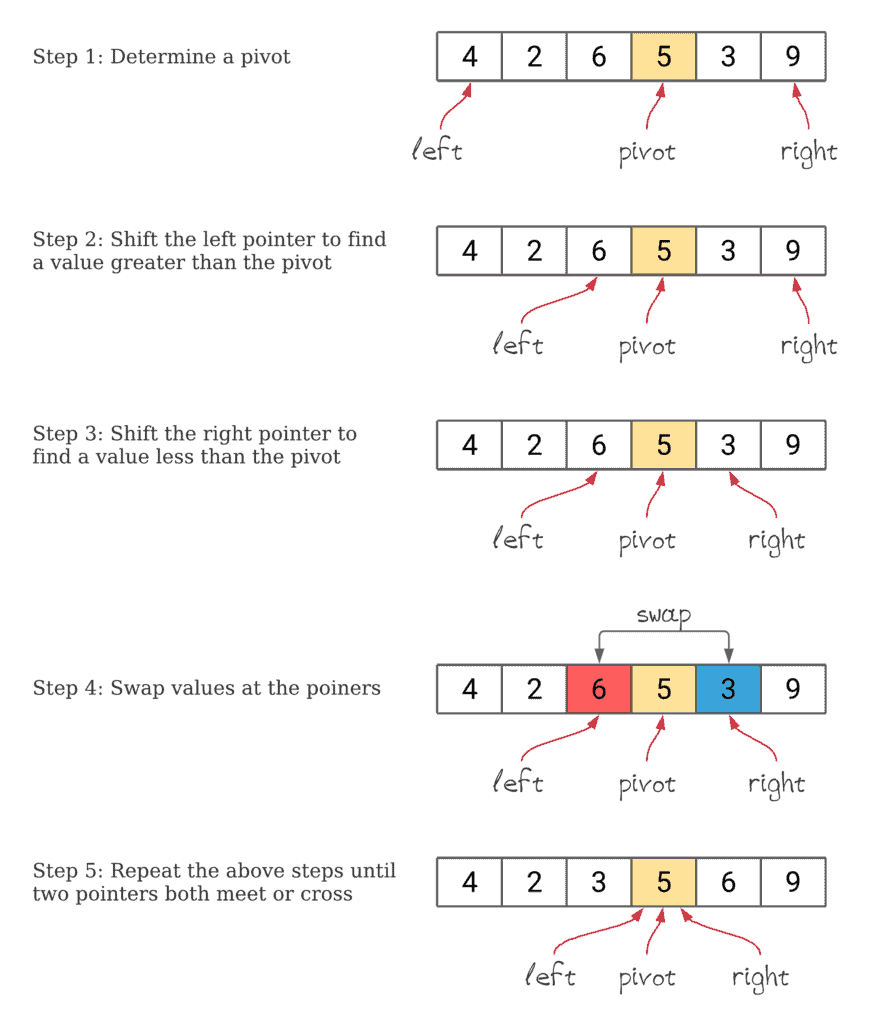
3. 堆排序(Heapsort)
堆排序是一种基于二叉堆(Binary Heap)结构的比较排序算法。它利用堆的性质(父节点值大于/小于子节点)来高效地找出最大或最小元素。
堆排序的主要步骤如下:
- ✅ 构建堆:将输入数组构造成一个最大堆或最小堆
- ✅ 提取根节点:将堆顶元素(最大/最小)取出并放入排序结果
- ✅ 调整堆(Heapify):将剩余元素重新构造成堆
- ✅ 重复步骤 2~3,直到堆中只剩一个元素
堆排序的时间复杂度始终为 O(n log n),且空间复杂度为 O(1),非常适合内存受限的环境。
以下是一个堆排序的图示示例:
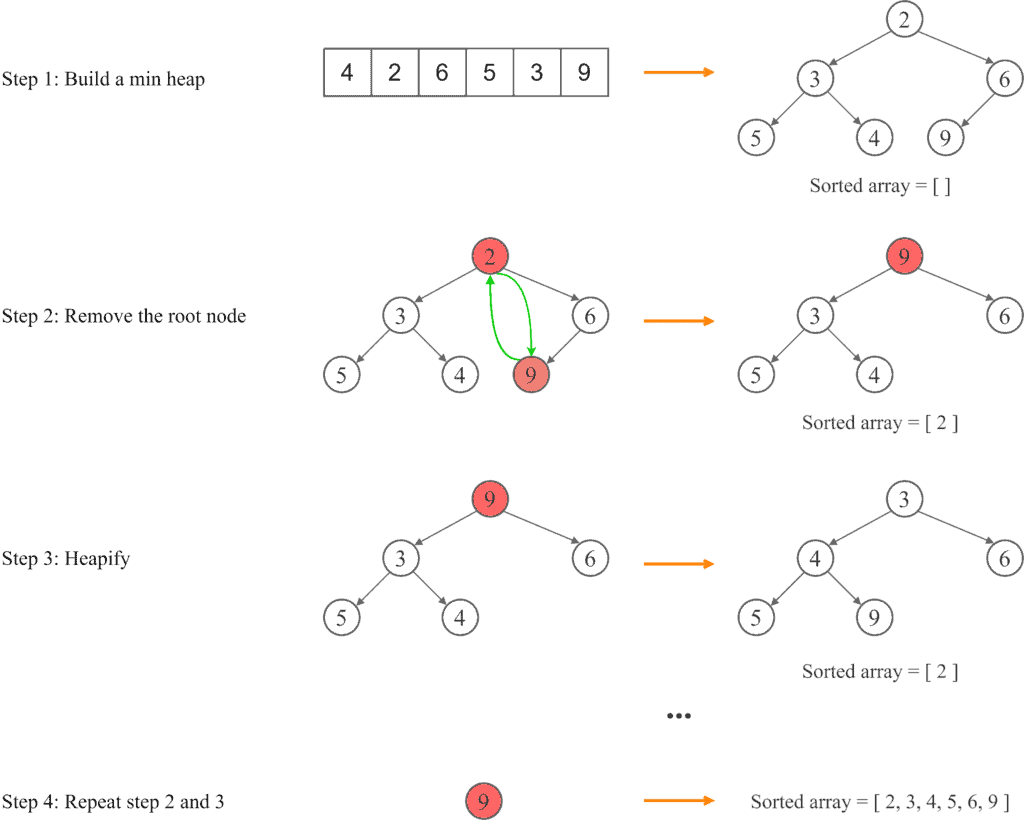
4. 快速排序 vs 堆排序对比
下面从多个维度对快速排序和堆排序进行对比:
| 特性 | 快速排序 | 堆排序 |
|---|---|---|
| 排序方法 | 分治法 | 选择类(基于堆) |
| 稳定性 | 不稳定 | 不稳定 |
| 是否原地排序 | 是 | 是 |
| 时间复杂度 - 平均 | O(n log n) |
O(n log n) |
| 时间复杂度 - 最坏 | O(n²)(可能) |
O(n log n) |
| 空间复杂度 | O(log n)(递归栈) |
O(1) |
| 适用场景 | 内存充足,追求速度 | 内存受限,如嵌入式系统 |
各自优缺点
快速排序
✅ 优点:
- 实际运行速度快,适合大多数数据集
- 平均复杂度为
O(n log n) - 可通过优化 pivot 选择避免最坏情况
❌ 缺点:
- 最坏情况下时间复杂度退化为
O(n²) - 递归深度大时可能导致栈溢出
堆排序
✅ 优点:
- 最坏情况仍为
O(n log n) - 空间复杂度低,仅为
O(1)
❌ 缺点:
- 实际运行速度通常比快速排序慢
- 常数因子较大,影响性能
实际应用建议
- 快速排序适合内存充足、追求效率的场景,比如服务器端数据处理、大数据集排序
- 堆排序更适合内存受限的环境,如嵌入式系统、内核排序等
⚠️ 踩坑提醒:虽然堆排序在理论上比快速排序更“稳定”,但实际性能往往不如快速排序。尤其在现代 CPU 架构中,快速排序的缓存命中率更高,执行效率更优。
5. 总结
快速排序和堆排序都是经典的排序算法,各有优势:
- 快速排序:速度快,适合大多数场景,但需注意 pivot 选择和递归深度
- 堆排序:空间效率高,适合内存受限环境,但常数因子大,实际运行较慢
根据实际场景选择合适的排序算法,是提升程序性能的关键之一。在工程实践中,也可以考虑使用优化版本的快速排序(如 Java 的 Arrays.sort())或混合排序策略(如 TimSort)来兼顾性能与稳定性。