1. 引言
在排序算法中,我们通常会根据执行效率和空间占用等因素来选择合适的算法。
本文将重点对比两种经典的排序算法:快速排序(Quicksort) 和 归并排序(Mergesort)。它们都采用分治策略(divide-and-conquer),但在性能表现和内存使用方面有明显差异。
2. 快速排序(Quicksort)
快速排序是一种原地排序算法(in-place sorting),采用分治思想,其主要步骤如下:
- 选择一个基准值(pivot)
- 将小于 pivot 的元素移到其左侧,大于 pivot 的元素移到右侧
- 对左右两个子数组递归执行上述操作,直到排序完成
示例演示
我们以一个数组 [15, 3, 8, 10, 5, 23] 为例,演示快速排序的执行过程:
第一步:选择基准值
我们选择最右侧元素 23 作为 pivot。
第二步:划分数组
将小于 23 的元素放左边,大于的放右边(不关心顺序):

第三步:递归处理左右子数组
我们继续对左侧子数组 [15, 3, 8, 10, 5] 执行快速排序,选择 5 作为 pivot:

继续对 [15, 8, 10] 排序,选择 10 作为 pivot:

最终得到一个有序数组。
小贴士
✅ 快速排序适合内存有限的场景,因为它是原地排序。
❌ 但其最坏时间复杂度为 O(n²),当 pivot 选择不当会显著影响性能。
⚠️ pivot 的选择策略对性能影响很大,常见策略有:首元素、尾元素、中间元素、随机选择、三数取中等。
3. 归并排序(Mergesort)
归并排序也是一种分治算法,但不同于快速排序,它不是原地排序算法,需要额外的临时数组来合并子数组。
其主要步骤如下:
- 将数组不断拆分成两个子数组,直到每个子数组只有一个元素
- 将两个有序子数组合并成一个有序数组
示例演示
我们以同样的数组 [15, 3, 8, 10, 5, 23] 来演示归并排序的过程。
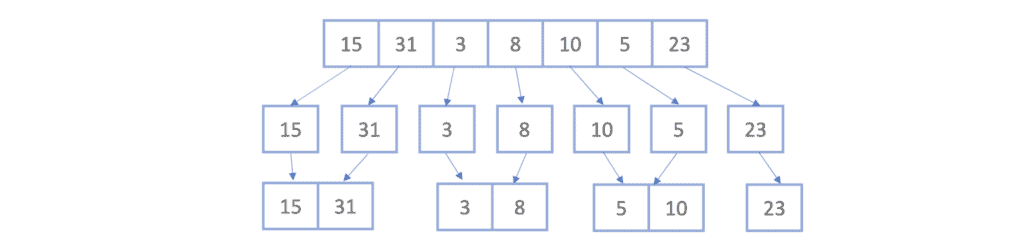
第一步:不断拆分
直到每个子数组只剩一个元素:

第二步:两两合并
合并后的四个有序子数组如下:
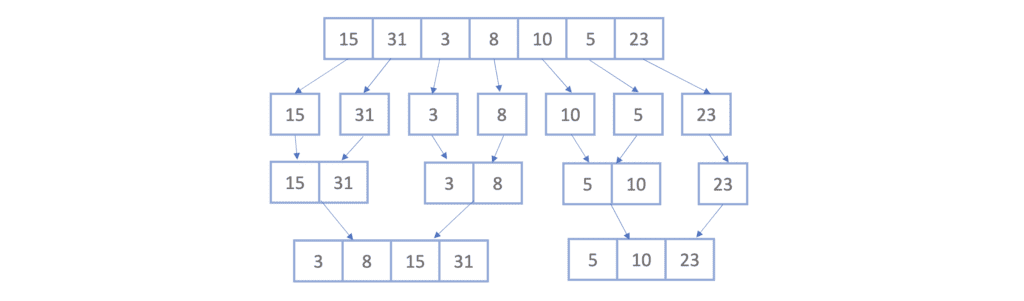
继续合并,得到两个更大的有序子数组:
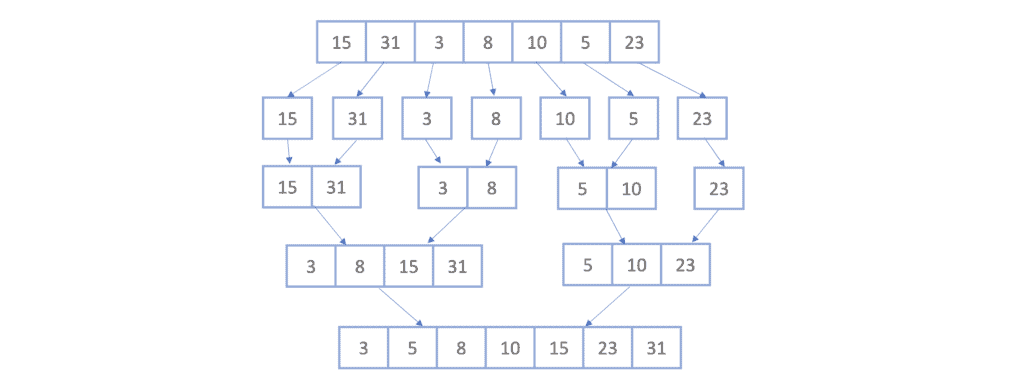
最终合并成一个完整的有序数组:
小贴士
✅ 归并排序性能稳定,最坏和平均时间复杂度都是 O(n log n)。
✅ 是稳定排序算法。
❌ 需要额外的 O(n) 空间,不适合内存受限的场景。
⚠️ 合并操作需要额外操作,性能略逊于快速排序(尤其在小数据量时)。
4. 快速排序 vs 归并排序
| 特性 | 快速排序 | 归并排序 |
|---|---|---|
| 是否原地排序 | ✅ 是 | ❌ 否(但有原地变体) |
| 最坏时间复杂度 | ❌ O(n²)(pivot 选择不当) | ✅ O(n log n) |
| 平均时间复杂度 | ✅ O(n log n) | ✅ O(n log n) |
| 稳定性 | ❌ 不稳定(但有稳定变体) | ✅ 稳定 |
| 空间复杂度 | ✅ O(log n)(递归栈) | ❌ O(n) |
| 适用场景 | ✅ 小数据集表现好 | ✅ 大数据集更优 |
📌 参考研究:一些研究表明,快速排序在小数据量时性能更优,而归并排序在大数据量时更稳定可靠。
5. 总结
本文我们对比了快速排序与归并排序的实现原理和性能特点:
- 快速排序是原地排序,平均性能好,但最坏情况可能退化为 O(n²)
- 归并排序性能稳定,适用于大数据排序,但需要额外空间
- 选择排序算法时需根据数据规模、内存限制、是否需要稳定排序等多维度综合考虑
✅ 踩坑提醒:在实际开发中,如果你使用快速排序处理大数据集,一定要注意 pivot 的选择策略,否则很容易“踩坑”导致性能下降。
✅ Java 的 Arrays.sort() 对原始类型使用的是双轴快速排序(Dual-Pivot Quicksort),对对象数组使用的是归并排序的变体(TimSort),说明两者在不同场景下各有优势。
如需更深入理解排序算法的实现细节,可以参考我们其他文章中关于链表排序、非递归归并排序等内容。