1. 概述
本文我们将探讨“随机性”的概念及其在计算机科学中的应用。
首先,我们会从本体论和认识论的角度来探讨随机性的理论基础。接着,我们会讨论随机生成和随机采样的问题。
在本文结束时,你将理解为何随机性在计算机科学、统计学和密码学中如此重要。
2. 随机性的理论基础
2.1 随机性理论简介
在我们探讨随机性在技术中的应用之前,先介绍其理论基础。随机性的抽象概念在学术上是“模糊定义”的,也就是说,对于“纯粹的随机性”到底意味着什么,学界存在分歧。不过,大家普遍接受“随机现象”和“随机抽样”的概念。
随机性是哲学、混沌理论、概率论、以及近年来的计算机科学、人工智能和量子计算等多个领域共同研究的主题。它的重要性在于许多现实世界的技术,例如密码学和人工群体智能,都依赖它作为其理论基础之一。
随机性还有一个更深层的含义:它与事件结果的先验不可预测性有关。在科学中,随机性的假设防止了将自然界简化为可预测规则集的决定论倾向,我们稍后会更详细地讨论这一点。
2.2 不只是理论
随机性不仅在理论上重要,在科学研究的方法论中也扮演着关键角色。这是因为科学假设的验证需要实证测试,而这又依赖于一种方法来解决样本偏差问题。我们会在后面详细讨论这一点。
然而,关于随机性是否真实存在于现实世界中,还是只是人类知识有限的产物,学界仍存在争议。前者认为随机性是自然界的一种属性,称为“本体论随机性”;后者则认为它是观察者知识状态的反映,称为“认识论随机性”。
我们将在本节中探讨这两种观点。理解了随机性的本体论和认识论基础后,我们就能更好地理解它在实际技术中的应用。
2.3 非决定论的宇宙
关于世界的一个古老观点是:宇宙(kosmos)具有内在的秩序和完美性。这种完美性体现在星体、行星乃至人类生活的数学精确性上。这种观点被称为“决定论”(determinism)。
决定论在科学中曾是非常成功的思路,尤其在20世纪上半叶以前。在物理学中,牛顿利用决定论构建了[宇宙模型],尽管后来被证伪。在牛顿力学中,宇宙就像一个钟表装置,所有组成部分的行为都是确定且可预测的:
在这个理论下,只要知道宇宙在某一时刻的状态和支配其行为的规则,就能完全预测未来和还原过去。因此可以说,牛顿力学不承认随机性的存在。
在一个牛顿式的宇宙中,一个拥有宇宙状态和规则完全知识的存在(如拉普拉斯妖),对所有目的而言都是全知的。对于这个存在来说,任何掷骰子的结果都是已知的,因此未来没有任何不确定性:
2.4 混沌理论与随机性
然而,绝对决定论被混沌理论所否定。混沌理论表明,即使初始状态非常相似,同一个系统的演化路径也可能大相径庭。这被称为“对初始条件的敏感依赖性”。
最著名的例子是“逻辑斯蒂映射”(logistic map):
$$ x_{n+1} = r \cdot x_n \cdot (1 - x_n) $$
这个系统由参数 $ r $ 决定,但除此之外是完全确定的。它的行为根据初始配置(即 $ r $ 的值)而剧烈变化。这就是所谓的“分岔图”(bifurcation diagram):
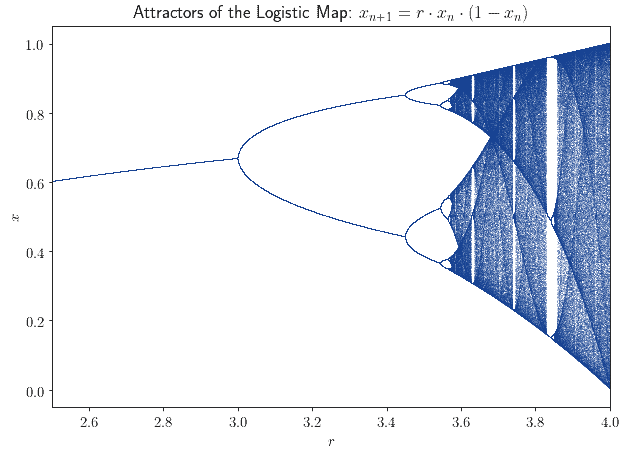
对于观察者来说,这个系统的行为可能看起来是随机的。但实际上,它的奇怪行为来源于一个简单的确定性规则。如果我们知道系统的初始状态,就能以完全的精度预测其未来演化:
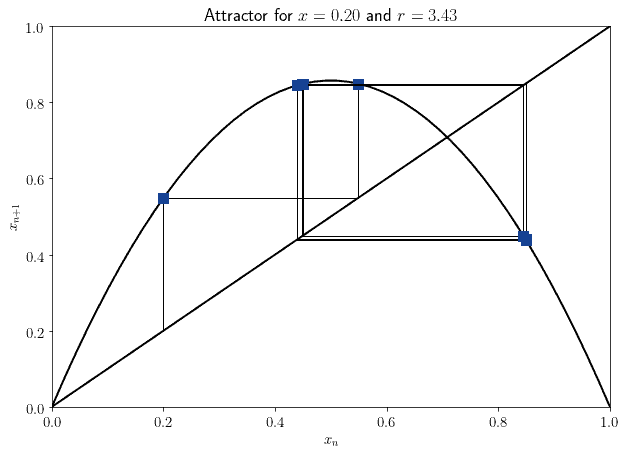
由此引出了一个观点:一个系统的行为是否显得随机,取决于我们对它的了解程度。对于一个无知的观察者来说,系统可能是随机的;而对于一个知识丰富的观察者来说,同样的系统可能是确定性的。于是,随机性作为观察者知识状态的属性,开始进入科学讨论。
2.5 量子随机性
另一个关于随机性的观点来自量子力学,特别是著名的“双缝实验”。该实验表明,测量一个系统的状态,无论是什么状态或什么系统,都会改变它本身。这反过来会使原本可能成立的预测失效。
由于宇宙本身可能是一个量子系统,这意味着我们要验证任何预测的准确性,就必须对宇宙进行量子测量。而这又会改变宇宙的状态,从而使其预测失效。
那么问题来了:具体某一个测量结果是如何被选中的?
根据“哥本哈根解释”,当进行测量时,所有可能的结果中会随机选择一个,其余结果被丢弃。在这里,随机性作为观察者与系统互动的结果,物理地进入了游戏。
2.6 不是一个世界,而是多个世界
另一种观点认为,随机性根本不存在,因为每当一个事件有多个可能结果时,所有的结果都会同时发生。这就是所谓的“埃弗雷特解释”(Everettian interpretation),也称为“多世界解释”。
在该解释中,测量结果的随机选择并不存在。相反,所有可能的测量结果同时发生,但观察者只能感知到其中一个结果。
在这种背景下,随机变量的概率分布可以被解释为“世界概率分布”。形象地说,如果你掷一个骰子,宇宙就会分裂,为每一个可能的结果生成一个副本:
但观察者只能感知到他所处宇宙中的那个结果。
虽然不同的解释对双缝实验的深层含义存在分歧,但它们都同意一点:观察者和观测行为在事件结果中起着根本性作用。这为随机性的“认识论”解释打开了大门,而非“本体论”。
2.7 认识论解释
我们可以沿着这条路径继续,把随机性看作不是宇宙的属性,而是事件与观察者之间关系的属性。如果一个事件的随机性源于观察者,那么随机事件就不能脱离某个特定观察者来描述。
两个不同观察者对同一过程结果的随机性判断可能不同。例如:
一个人在屏幕后掷骰子并看到结果,另一个人看不到。如果宇宙允许随机性,那么对于两个观察者来说,这个结果都是随机的。但当第一个观察者看到结果后,它还随机吗?
从第二个观察者的角度看,结果仍然是随机的。但如果他后来知道了结果,那骰子的随机性就消失了:
因此,合理的解释是:随机性与观察者所拥有的知识有关。随着观察者获得更多关于事件的信息,其随机性可能会减少,甚至消失。
这个例子支持所谓的“认识论随机性”观点。在这种背景下,随机性仅表示观察者对预测或某些测量结果的不确定性,而不具有更深层的本体论意义。
2.8 为什么这很重要?
随机性的本体论和认识论基础非常重要。因为许多关键技术,如区块链和加密技术,都需要随机性才能正常运作。正如我们上面所看到的,随机性是否是宇宙的本体属性并不明确,它更可能是观察者状态的反映。
除非宇宙本身是内在随机的,否则我们在开发利用随机性的应用时必须考虑观察者的角色。这是因为在某些上下文中(尤其是加密的对抗性方法中),不同观察者对随机变量未来值的预测能力不同。因此,他们对哪些变量是“随机的”也可能有不同看法。
简而言之,如果随机性不存在,我们就无法用它来构建任何东西。而正如我们所见,随机性是否是宇宙的属性尚不明确。但它可以是一个衡量预测不确定性的良好方式;从这个意义上说,随机性理论在技术发展的理论基础中占有一席之地。
3. 随机序列与随机生成
3.1 序列的随机性
现在我们来讨论生成和采样随机变量的问题。在实践中,这是我们应用随机性理论的两个主要方向。
在这一节中,我们感兴趣的是:当我们面对一个新的数字序列时,如何判断它是否是随机的?
假设有人告诉我们一个数字:

这个数字是随机的吗?它的数字看起来彼此之间没有关联,我们可能会怀疑它是随机的。再让这个人多给几个数字看看:

无论这个人生成数字的规则是什么,序列中的下一个数字似乎都与之前的相同。这意味着序列中的任意一个数字的信息量都非常有限。
再想象一下,这个人又给了我们一个新序列:

这个新序列看起来比之前的“更随机”。这是因为,无论对方生成序列的规则是什么,我们都无法仅凭数字本身轻易猜出它。
3.2 随机生成
这引出了我们对[随机序列生成]的思考。理想情况下,我们希望一个随机数序列没有任何算法可以预测下一个数字。
但如果我们使用任何算法来生成一个数字序列,那么这个算法就可以用来计算序列中的任何元素。因此,我们无法通过算法生成真正的随机数。
因此,我们能做的最好就是使用一些算法,使得重构我们使用的生成过程变得特别复杂或代价高昂。这些算法被称为“伪随机数生成器”,因为它们不使用真正的随机性,而是使用近似。
3.3 伪随机生成:中方法
伪随机数的生成一直是数学家关注的问题,比如冯·诺依曼。他提出了“中方法”(Middle Square Method),可以生成任意长度的伪随机数序列。
该方法包括:将一个起始数字(称为“种子”)平方,然后提取中间的几位数字作为下一个数字。然后对这个新数字重复同样的操作。
以下是一些种子对应的前几个生成结果:
| Seed | x₁ | x₂ | x₃ | x₄ | x₅ | x₆ |
|---|---|---|---|---|---|---|
| 11 | 12 | 14 | 19 | 36 | 29 | 84 |
| 1234 | 5227 | 3215 | 3362 | 3030 | 1809 | 2724 |
| 1000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 |
| 987654 | 460423 | 989338 | 789678 | 591343 | 686543 | 341290 |
但这种方法存在一个严重问题:如果序列中某个数字的中间位是0,它将一直保持为0。例如,种子为1000时,序列很快收敛到0,使得该算法在该种子下无效。
其他伪随机生成器也存在问题。例如,Dual_EC_DRBG 曾因可预测性引发争议,后来被证明存在漏洞,最终被市场淘汰。
这意味着我们选择的生成方法很重要。如果不小心,可能会得到一些毫无意义的序列。正如克努斯(Dr. Knuth)所说:“生成随机数不应该用随机的方法,而应该使用理论。”
4. 随机采样
4.1 随机采样与统计
随机性还帮助我们通过小样本研究总体特征,避免因偏见而犯错。如果我们对一个大数据集进行随机采样,随着样本大小的增加,样本的统计特征会趋近于总体:
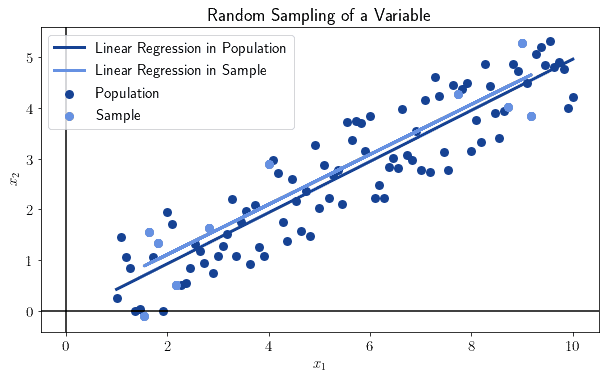
这适用于所有统计量和总体。但前提是样本必须是随机选取的,否则该规则不适用。
4.2 非随机采样
我们可以看看不随机采样的后果。一般而言,非随机采样会导致样本统计量出现严重偏差。
例如,我们随意选择离中位数最近的10个观测值来计算统计量:
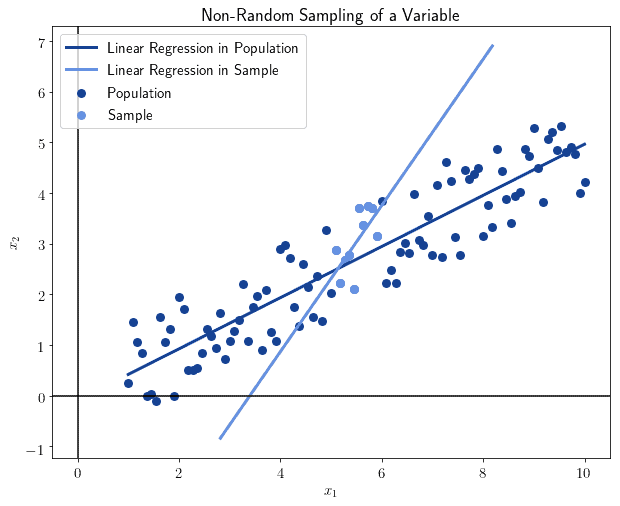
可以看到结果明显不同。这不是偶然:非随机选择的样本会导致结果失真,失去对总体的代表性。
4.3 随机变量的分布
现在我们来讨论随机变量的分布形状。有些形状特别直观。例如,如果我们从均匀分布 (0, 1) 中随机采样 $ x $(样本大小为1000),那么 $ x $ 也是均匀分布的:
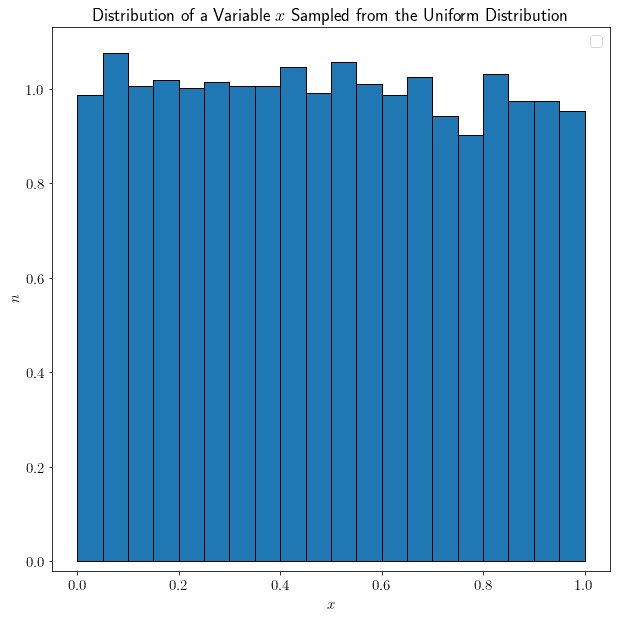
除了随机波动,每个子区间中的样本数量大致相等。我们也可以从正态分布中采样,结果也会是正态分布:
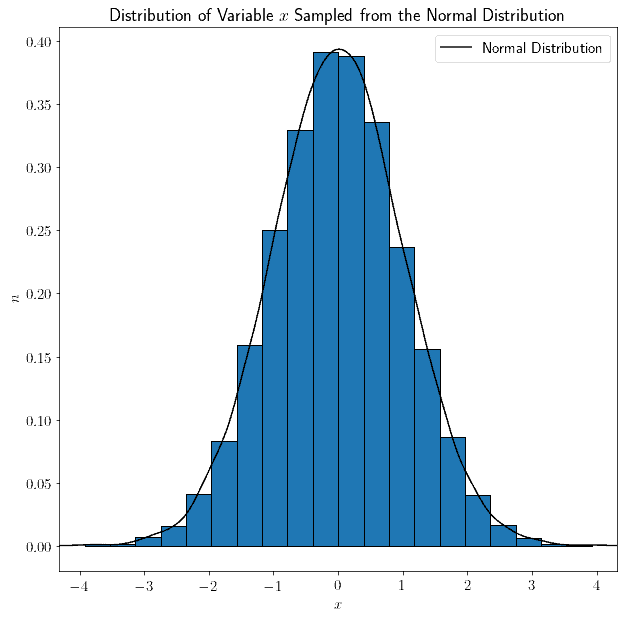
一般来说,从分布 $ D $ 中随机采样的变量 $ x $,其分布形状与 $ D $ 相同。
4.4 随机变量的组合
但这个规则不适用于多个变量及其线性组合。我们可以用实验验证这一点。假设 $ x $ 和 $ y $ 是从均匀分布中采样的随机变量,我们可以研究它们的和 $ x + y $:
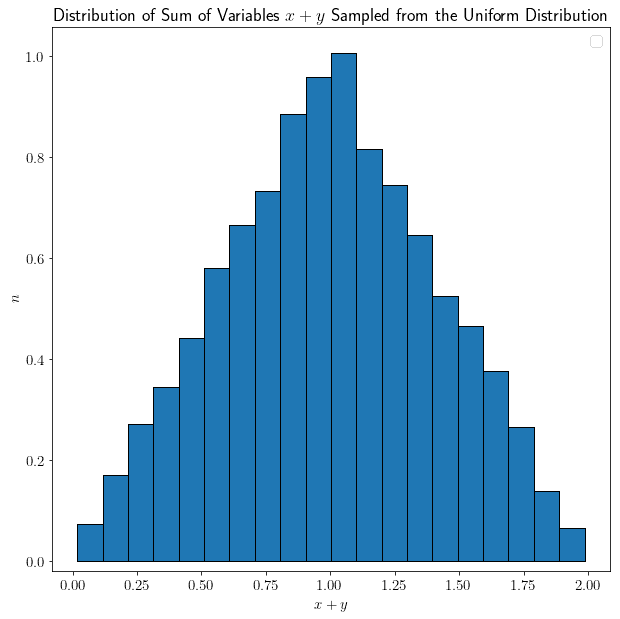
令人惊讶的是,它们的和不再是均匀分布,而是呈现出一个非常特殊的形状。再加入一个从均匀分布中采样的变量 $ z $:
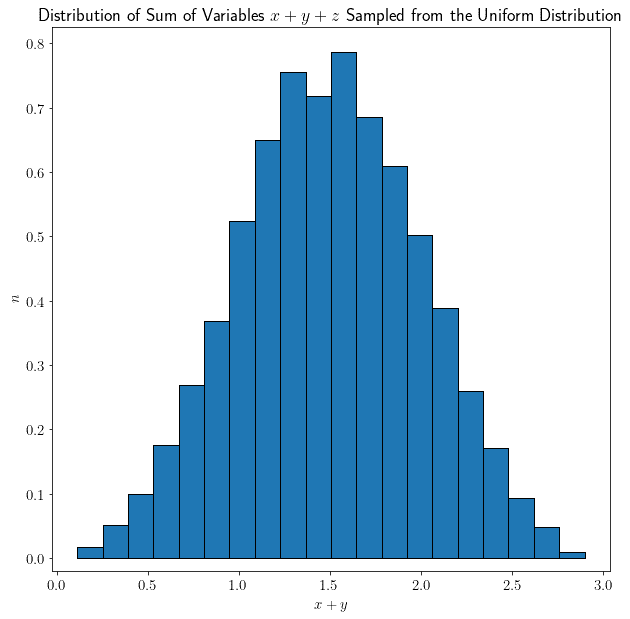
形状变得更加明显。最后,我们加入100个从均匀分布中采样的变量 $ x_1, x_2, ..., x_{100} $:
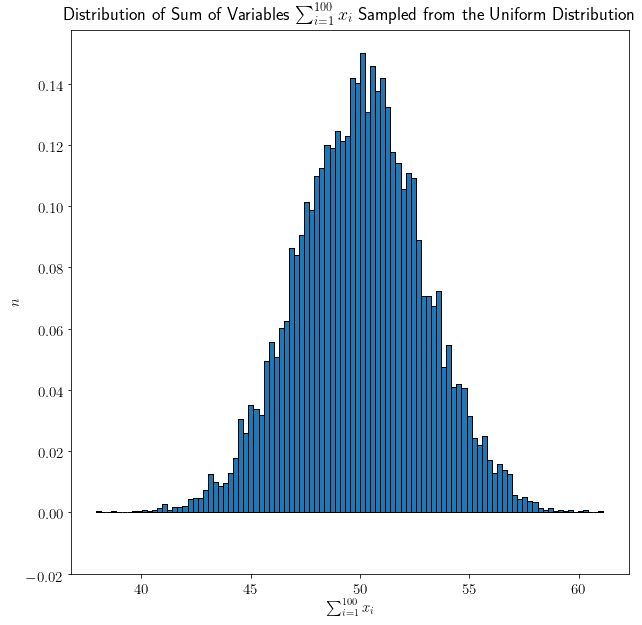
现在这个形状更加清晰,看起来就像正态分布。
4.5 中心极限定理
我们可以用数学形式化上面的观察结果,这就是著名的中心极限定理(Central Limit Theorem)。
该定理指出:随着我们考虑的随机变量数量增加,无论它们的原始分布是什么形状,它们的和会趋向于正态分布。
用数学符号表示如下:
如果 $ \overline{x}_i $ 表示变量 $ x_i $ 的平均值,$ \mu $ 和 $ \sigma $ 分别表示原始分布的均值和标准差,则所有 $ x $ 的和的分布 $ N $ 可以表示为:
$$ \lim_{n \to \infty}\frac{\overline{x}_{n} - \mu}{\sigma / \sqrt{n}} = \mathcal{N}(\mu, \sigma^2) $$
其中 $ \mathcal{N}(\mu, \sigma^2) $ 是正态分布。
4.6 中心极限定理的应用
我们可以通过一个实际例子来理解这个定理的重要性。假设我们掷两个骰子 $ d_1 $ 和 $ d_2 $,并求它们的和。我们可能会认为,由于每个骰子在 [1, 6] 上是均匀分布的,它们的和在 [2, 12] 上也应该是均匀分布的。
但实际分布如下:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
用图表表示如下:
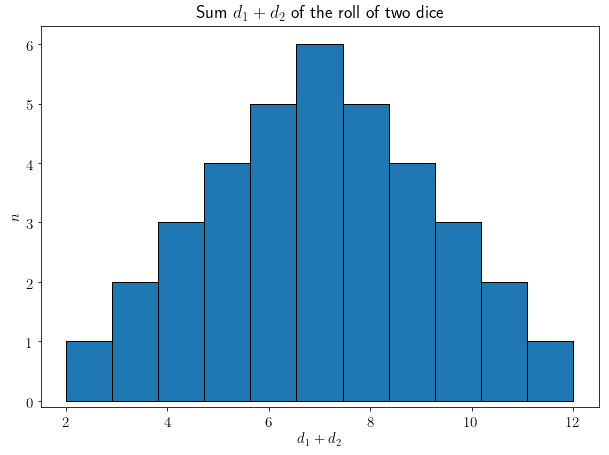
可以看出,正态分布的形状在仅两个骰子的和中就已经开始显现。如果我们掷更多骰子,中心极限定理告诉我们,正态分布的形状将更加明显。
5. 总结
在本文中,我们首先从本体论和认识论的角度探讨了随机性的基础。
然后,我们研究了随机生成和随机采样在计算机科学中的实际应用差异。
最后,我们学习了中心极限定理,并通过掷骰子的例子理解了它在统计学中的重要作用。
理解随机性不仅是理论问题,更是许多现代技术的基础。掌握它,有助于我们在开发安全系统、人工智能模型或数据分析工具时做出更明智的设计决策。