1. 概述
循环神经网络(Recurrent Neural Networks, RNNs)是处理序列数据最成功的神经网络架构之一。 本文将从 RNN 的基本结构讲起,分析其与传统前馈神经网络的区别,介绍常见的 RNN 变体(如 LSTM 和 GRU),并列举其典型应用场景。
如果你已经对神经网络有基本了解,并希望掌握处理时间序列、文本等序列型数据的方法,那本文将是一个不错的参考。
2. 基本结构
RNN 的核心思想是:通过隐藏状态(hidden state)在时间步之间传递信息,从而让网络具备“记忆”能力。
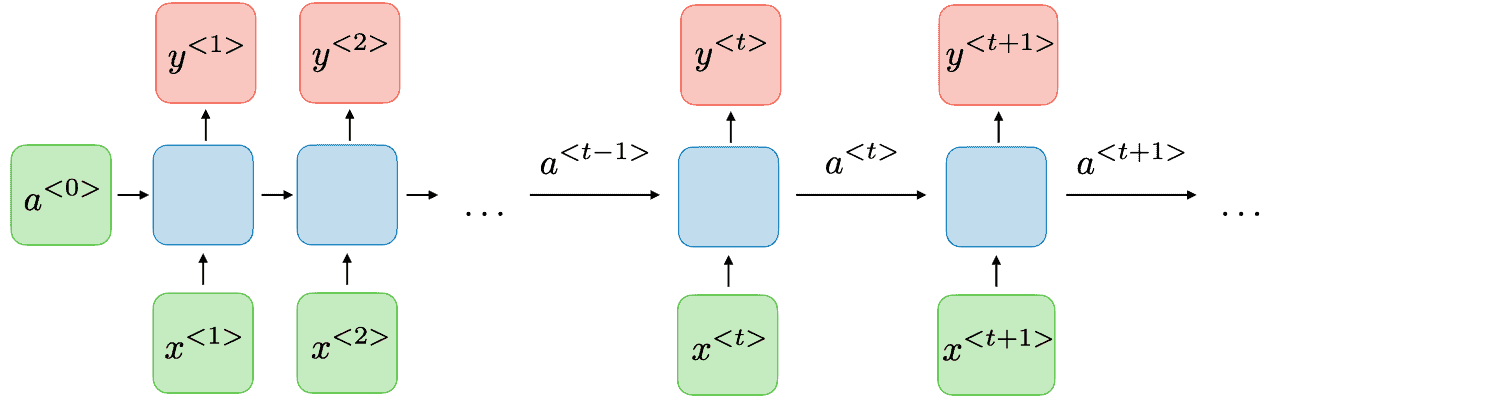
每个 RNN 单元(cell)依次处理输入序列中的一个元素,同时将当前的隐藏状态传递给下一个单元。例如,第 i 个单元接收输入向量  ,计算出隐藏状态
,计算出隐藏状态  ,并传给第 i+1 个单元。
,并传给第 i+1 个单元。
下图展示了一个典型的 RNN 结构:
✅ 示例代码(TensorFlow)
import tensorflow as tf
class RNNModel(tf.keras.Model):
def __init__(self, units, input_feature_dim, num_classes):
super(RNNModel, self).__init__()
self.rnn_layer_1 = tf.keras.layers.SimpleRNN(units, return_sequences=True, input_shape=(None, input_feature_dim))
self.rnn_layer2 = tf.keras.layers.SimpleRNN(units, return_sequences=False)
self.fc = tf.keras.layers.Dense(num_classes)
def call(self, inputs):
x = self.rnn_layer_1(inputs)
x = self.rnn_layer2(x)
output = self.fc(x)
return output
# 超参数
input_feature_dim = 10
units = 20
num_classes = 3
model = RNNModel(units, input_feature_dim, num_classes)
✅ 示例代码(PyTorch)
import torch
import torch.nn as nn
class RNNModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(RNNModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.rnn(x, h0)
out = self.fc(out[:, -1, :])
return out
# 超参数
input_size = 10
hidden_size = 20
num_layers = 2
num_classes = 3
model = RNNModel(input_size, hidden_size, num_layers, num_classes)
⚠️ 注意:在多层 RNN 中,除了最后一层外,其他层应设置
return_sequences=True,以便将整个序列传递给下一层。
3. 与传统网络的区别
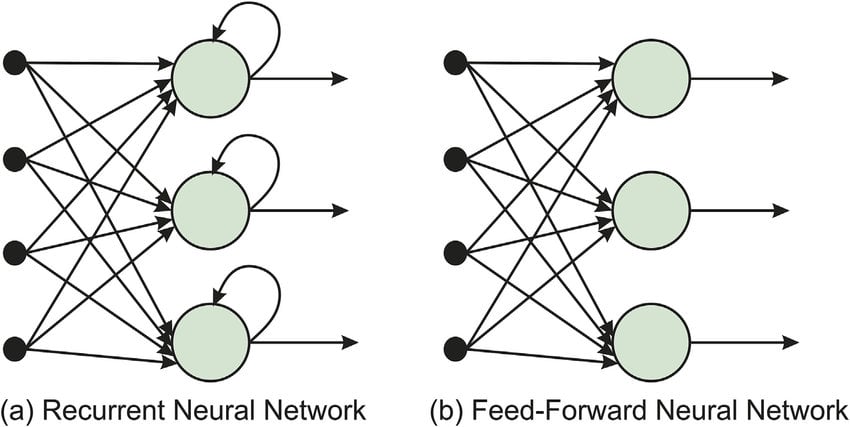
传统前馈神经网络(Feedforward Neural Networks)对每个输入是独立处理的,不具备“记忆”能力。而 RNN 的核心优势在于:
- 引入了隐藏状态作为记忆机制
- 允许信息在多个时间步间流动
下图对比了 RNN 与传统网络的结构差异:
✅ 踩坑提醒:在使用 RNN 时,要特别注意输入序列的长度和 batch_first 设置是否一致,否则容易出现维度错误。
4. RNN 的变体
虽然原始 RNN 结构简单,但在处理长序列时容易出现梯度消失问题。为了解决这些问题,研究人员提出了多种变体。其中最常用的是:
4.1. LSTM(Long Short-Term Memory)
LSTM 通过引入记忆单元(memory cell)和三个门控机制(输入门、遗忘门、输出门),显著缓解了梯度消失的问题,非常适合处理长序列依赖。
✅ 示例代码(TensorFlow)
class LSTMModel(tf.keras.Model):
def __init__(self, units, input_feature_dim, num_classes):
super(LSTMModel, self).__init__()
self.lstm_layer = tf.keras.layers.LSTM(units, return_sequences=False, input_shape=(None, input_feature_dim))
self.fc = tf.keras.layers.Dense(num_classes)
def call(self, inputs):
x = self.lstm_layer(inputs)
output = self.fc(x)
return output
✅ 示例代码(PyTorch)
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :])
return out
4.2. GRU(Gated Recurrent Unit)
GRU 是 LSTM 的简化版本,只包含两个门控(更新门和重置门),但性能接近 LSTM,且计算效率更高。
✅ 示例代码(TensorFlow)
class GRUModel(tf.keras.Model):
def __init__(self, units, input_feature_dim, num_classes):
super(GRUModel, self).__init__()
self.gru_layer = tf.keras.layers.GRU(units, return_sequences=False, input_shape=(None, input_feature_dim))
self.fc = tf.keras.layers.Dense(num_classes)
def call(self, inputs):
x = self.gru_layer(inputs)
output = self.fc(x)
return output
✅ 示例代码(PyTorch)
class GRUModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(GRUModel, self).__init__()
self.gru = nn.GRU(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.gru(x, h0)
out = self.fc(out[:, -1, :])
return out
✅ 推荐使用顺序:LSTM > GRU > SimpleRNN
5. 应用场景
RNN 及其变体在多个领域都有广泛应用,以下是一些最常见的使用场景:
5.1. 自然语言处理(NLP)
- 文本生成(如 Chatbot)
- 机器翻译
- 文本分类
- 语音识别
5.2. 时间序列预测
- 股票价格预测
- 天气预报
- 销售趋势预测
5.3. 视频处理
- 视频动作识别
- 视频摘要生成
- 视频分类
5.4. 强化学习
- 机器人路径规划
- 游戏 AI 决策系统
- 动态环境状态建模
6. 总结
本文系统介绍了 RNN 的基本结构、与传统神经网络的区别、主流变体(LSTM、GRU)及其代码实现,并列举了其在多个领域的典型应用场景。
✅ 推荐学习路径:
- 先掌握基本 RNN 的工作原理
- 再深入理解 LSTM 和 GRU 的内部机制
- 最后结合实际项目进行调参和优化
如果你在处理序列数据时遇到长依赖问题,不妨尝试 LSTM 或 GRU。它们在大多数任务中表现优于原始 RNN。