1. 引言
在本篇文章中,我们将探讨函数的一个重要特性:引用透明性(Referential Transparency)。这个特性在多种编程语言和编程范式中都有体现。理解它有助于我们写出更易优化、更易维护的代码,尤其在并发和缓存方面具有重要意义。
2. 引用透明性简介
引用透明性指的是:一个函数在相同输入下始终返回相同输出,并且不会产生副作用。换句话说,这样的函数可以被它的返回值直接替换,而不影响程序的行为。
2.1. 示例
我们来看一个简单的加法函数:
int add(int a, int b) {
return a + b;
}
这个函数是引用透明的,因为它只依赖传入的参数,且没有副作用。
但如果我们把输入逻辑也写进函数内部,比如从标准输入读取参数:
int add() {
Scanner scanner = new Scanner(System.in);
int a = scanner.nextInt();
int b = scanner.nextInt();
return a + b;
}
这个函数就不再是引用透明的了,因为每次调用可能会读取不同的输入,导致输出不同。
为了让它保持引用透明,我们可以把输入逻辑从函数中抽离出来:
int add(int a, int b) {
return a + b;
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int a = scanner.nextInt();
int b = scanner.nextInt();
int result = add(a, b);
System.out.println("Sum: " + result);
}
✅ 结论:add() 是引用透明的,而 main() 不是。
3. 与编程范式的关联
引用透明性受编程范式影响很大。不同范式中函数与外部状态的交互方式不同,从而影响其是否具备引用透明性。
3.1. 命令式编程(Imperative Programming)
命令式编程强调“怎么做”,常见语言如 C、C++。
在命令式编程中,全局变量 和 静态变量 是导致函数不透明的常见原因。
示例一:使用全局变量
#include <stdio.h>
int a, b; // 全局变量
int add() {
return a + b;
}
int main() {
printf("Enter two numbers: ");
scanf("%d %d", &a, &b);
printf("Sum: %d\n", add());
return 0;
}
⚠️ add() 没有参数,但它依赖全局变量 a 和 b,因此不是引用透明的。
示例二:使用静态变量
#include <iostream>
int add(int x) {
static int s = 0;
s += x;
return s;
}
这个函数每次调用都会改变静态变量 s 的值,导致相同输入返回不同结果,因此也不是引用透明的。
3.2. 面向对象编程(Object-Oriented Programming)
面向对象语言如 Java、C#,强调封装和状态管理。
类的成员变量(属性)是导致方法不透明的主要因素。
示例
public class Adder {
private int a;
private int b;
public Adder(int a, int b) {
this.a = a;
this.b = b;
}
public int sum() {
return a + b;
}
}
虽然 sum() 看起来是引用透明的,但如果类中有其他方法修改了 a 或 b,它就不再透明了。因此,依赖类状态的方法本质上是非透明的。
3.3. 函数式编程(Functional Programming)
函数式语言如 Haskell、Lisp 强制所有函数都必须是引用透明的。
示例(Haskell)
add :: Int -> Int -> Int
add a b = a + b
main :: IO ()
main = do
putStrLn "Enter first number:"
a <- readLn
putStrLn "Enter second number:"
b <- readLn
let s = add a b
putStrLn ("Sum: " ++ show s)
在 Haskell 中,除了 main(它属于 IO Monad),所有函数都是引用透明的。
✅ 函数式编程的优点:
- 更容易推理和测试
- 更容易并行执行
- 更容易优化(如缓存、编译器优化)
4. 引用透明性的应用场景
引用透明函数具有许多实用优势,尤其适用于以下场景:
4.1. 缓存(Caching)
✅ 引用透明函数非常适合缓存,因为它的输出只取决于输入。我们可以缓存其结果,避免重复计算。
Map<String, Integer> cache = new HashMap<>();
int compute(int x, int y) {
String key = x + "," + y;
if (cache.containsKey(key)) {
return cache.get(key);
}
int result = x * y + (x - y);
cache.put(key, result);
return result;
}
⚠️ 这种缓存机制只有在函数是引用透明的前提下才安全。
4.2. 并行化(Parallelisation)
✅ 引用透明函数可以在多个线程中安全并行执行,因为它们不依赖外部状态,也不会修改共享变量。
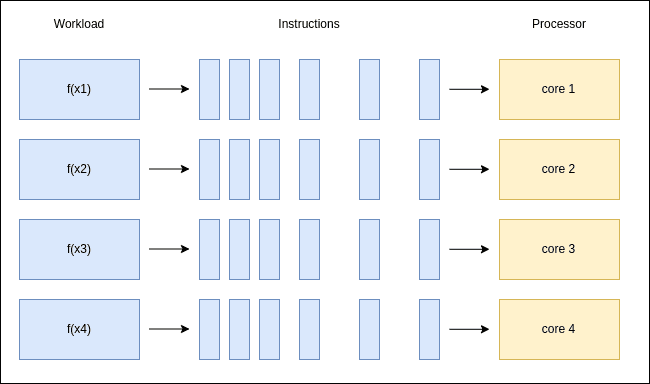
4.3. 流水线化(Pipelining)
✅ 引用透明函数可以被安全地重叠执行,比如在数据流处理中,我们可以提前开始处理下一个输入,而无需等待前一个流程完成。
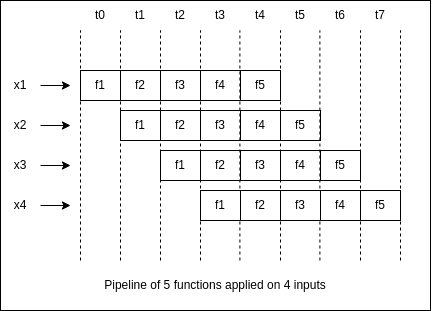
⚠️ 如果函数是非透明的,可能存在隐藏的依赖关系,导致流水线执行结果错误。
5. 总结
引用透明性是一种重要的函数属性,它要求函数的输出只依赖于输入参数,且不产生副作用。这种特性在函数式编程中被强制执行,在其他范式中则需要开发者有意识地避免使用全局变量、类状态和静态变量等外部状态。
✅ 引用透明函数的优势:
- 更容易推理和测试
- 更容易缓存和优化
- 更容易并行和流水线执行
如果你希望写出高质量、可维护、可扩展的代码,引用透明性是一个非常值得掌握的概念。