1. 引言
在理论计算机科学中,形式语言(Formal Languages)被用来建模不同类型的计算过程,并研究算法与自动机的性质。常见的形式语言包括正则语言(Regular Languages)、上下文无关语言(Context-Free Languages)和图灵机语言等。
在本文中,我们将重点探讨正则语言——一种可以被有限自动机识别的形式语言。我们会介绍它的定义、特性、识别方法、实际应用场景以及它的局限性。
2. 正则语言概述
正则语言是一类可以通过正则表达式描述,并且能被有限自动机(Finite Automata)识别的语言。它用于定义符合特定模式的字符串集合,比如字符序列或单词。
正则语言在计算机科学中具有基础性地位,它不仅帮助我们理解计算理论,还在编译器设计、文本处理等软件工具中扮演重要角色。
2.1 形式化定义
一个正则语言可以形式化地定义为:能被有限自动机(FA)识别的所有字符串的集合。
FA 是一个五元组:
**(Q, Σ, δ, q₀, F)**,其中:
- Q:有限状态集合
- Σ:有限输入符号集合(输入字母表)
- δ:转移函数,定义为 δ: Q × Σ → Q
- q₀:初始状态,属于 Q
- F:终止状态集合,是 Q 的子集
FA 和正则表达式通过规则定义语言的结构。字符串必须满足这些规则才能被识别为语言中的合法成员。
2.2 常见正则语言示例
以下是一些典型的正则语言:
- 表示偶数的二进制字符串
- 恰好包含两个 'a' 的字符串集合
- 所有能被 3 整除的二进制数
- 包含子串 "01" 的所有字符串
这些语言都可以通过有限自动机或正则表达式来表示。
3. 正则语言的特性
正则语言具有一些重要的数学和计算特性,有助于我们识别、操作和分析它们。
3.1 封闭性(Closure Properties)
正则语言在以下操作下是封闭的:
✅ 并集(Union):若 L₁ 和 L₂ 是正则语言,则 L₁ ∪ L₂ 也是正则语言
✅ 连接(Concatenation):L₁·L₂ 是正则语言
✅ Kleene 闭包(Kleene Star):L* 也是正则语言
这些封闭性意味着我们可以通过组合已知的正则语言来构造新的正则语言。
3.2 正则表达式(Regular Expressions)
正则表达式是一种简洁、灵活的方式来定义正则语言。例如,考虑一个语言:所有包含偶数个 0 的字符串,可以用如下正则表达式表示:
1*(01*01*)*
解释:
1*匹配任意数量的 1(01*01*)*确保有偶数个 0,并允许任意数量的 1 插入其中
3.3 与有限自动机的等价性
正则语言可以被有限自动机识别,反之亦然:每个正则语言都可以用有限自动机表示。
例如,前面的正则表达式 1*(01*01*)* 可以用如下 NFA(非确定性有限自动机)表示:
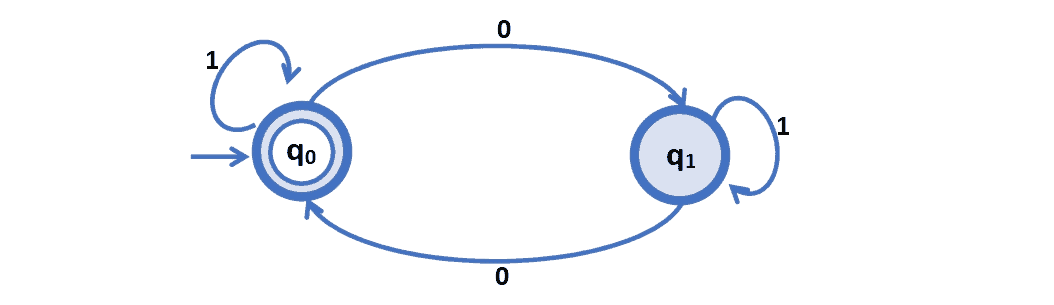
这个 NFA 只接受那些最终停在状态 q₀ 的字符串,即偶数个 0 的字符串。
4. 判断语言是否为正则语言
判断一个语言是否是正则语言,通常有以下几种方法:
4.1 泵引理(Pumping Lemma)
泵引理指出:如果一个语言是正则语言,那么存在一个“泵长度” p,使得该语言中所有长度 ≥ p 的字符串都可以被拆分为 xyz 三部分,并满足以下条件:
|xy| ≤ p|y| > 0- 对于任意 k ≥ 0,
xy^kz也在该语言中
这个引理常用于反证法,证明某个语言不是正则语言。
4.2 Myhill-Nerode 定理
Myhill-Nerode 定理指出:一个语言是正则语言当且仅当它在最小确定性有限自动机(DFA)中具有有限数量的不可区分字符串(Inequivalent Strings)。
如果能证明某个语言有无限多个不可区分字符串,则该语言不是正则语言。
4.3 封闭性验证法
利用正则语言的封闭性进行验证:如果某个语言在并、连接、闭包等操作下不保持正则性,则它不是正则语言。
4.4 与上下文无关语言(CFL)比较法
如果一个语言能被证明等价于某个上下文无关语言(CFL),那它就不是正则语言。因为 CFL 比正则语言更强大,能够描述更复杂的结构。
5. 正则语言的实际应用
正则语言虽然能力有限,但在实际工程中用途广泛,例如:
✅ 模式匹配:用于文本编辑器、编程语言中查找和替换特定格式字符串
✅ 词法分析:在编译器设计中识别关键字、标识符等
✅ 输入验证:验证用户输入是否符合格式要求(如邮箱、电话)
✅ 网络协议解析:定义 HTTP、FTP、SMTP 等协议的报文格式
✅ 生物信息学:分析 DNA 序列中的特定模式
6. 正则语言的局限性
尽管正则语言用途广泛,但也有明显限制:
❌ 表达能力有限:无法描述嵌套结构(如括号匹配、HTML 标签嵌套)
❌ 无法处理无界结构:不能处理长度不固定、需记忆状态的结构
❌ 不支持递归:不能表达需要递归定义的语言结构
因此,正则语言适用于简单模式识别,但更复杂的语言结构需要更强的模型(如上下文无关文法、图灵机等)。
7. 总结
正则语言是形式语言中最基础的一类,能被有限自动机识别,也能用正则表达式描述。它在词法分析、输入验证、文本处理等领域有广泛应用。
然而,正则语言的能力有限,无法处理嵌套、递归等复杂结构。对于这些场景,需要使用更强大的语言模型,如上下文无关语言或图灵机可识别语言。
理解正则语言的定义、性质和限制,有助于我们在实际开发中合理选择语言模型,避免“用错工具”的踩坑。