1. 什么是服务发现?
服务发现(Service Discovery)是微服务架构中一个核心概念,其核心目标是帮助服务在动态环境中自动识别和定位其他服务实例。
在微服务架构中,一个服务通常会有多个实例运行在不同的主机或容器中。这些实例的 IP 地址和端口是动态变化的,例如在 Kubernetes 中部署时,Pod 重启或扩容都会导致实例地址变动。
服务发现机制通过一个注册中心(Service Registry)来记录所有服务实例的网络位置。当一个服务实例启动时,它会向注册中心注册自己的信息;当客户端需要调用该服务时,它会从注册中心查询可用实例,并选择一个进行通信。
这种机制解决了服务间通信时的动态地址问题,避免了硬编码配置,提高了系统的灵活性和可维护性。
2. 为什么需要服务发现?
在没有服务发现的系统中,服务间的调用需要手动配置 IP 和端口,这在静态环境中尚可接受,但在微服务架构中,服务实例频繁变动,手动维护这些信息几乎不可行。
以下是一些典型场景:
- 自动扩缩容:服务根据负载自动扩展实例数量,新实例的地址无法提前预知。
- 滚动更新:新版本部署时,旧实例下线,新实例上线,地址变化频繁。
- 容错处理:当某个实例宕机时,需要自动切换到其他可用实例。
这些问题都需要一个统一的服务发现机制来协调。
3. 服务发现的工作原理
服务发现通常包含两个核心流程:
✅ 注册(Registration):服务实例启动时向注册中心注册自身信息(如 IP、端口、健康状态等)。
✅ 发现(Discovery):客户端或服务消费者通过查询注册中心获取目标服务的可用实例列表。
举个例子:
一个订单服务(Order Service)要调用用户服务(User Service)获取用户信息。由于用户服务可能有多个实例,订单服务无法直接知道要调用哪个。于是:
- 用户服务实例启动后,向注册中心注册自身地址;
- 订单服务在调用前先查询注册中心,获取用户服务的可用实例;
- 订单服务根据负载均衡策略选择一个实例进行调用。
4. 服务发现实现方式
服务发现主要有两种实现模式:
4.1. 客户端发现(Client-Side Discovery)
在这种模式下,服务消费者负责从注册中心获取服务实例列表,并自行实现负载均衡逻辑。
流程如下:
- 服务实例注册到注册中心;
- 服务消费者查询注册中心获取服务实例列表;
- 服务消费者使用负载均衡策略选择一个实例并发起调用。
优点:
- 不依赖额外的负载均衡器,节省一次网络跳转;
- 更灵活,适合多语言、多框架的微服务架构。
缺点:
- 服务消费者需要实现服务发现逻辑,增加了复杂性;
- 需要为不同语言/框架重复实现注册和发现逻辑。
常见实现工具包括:
- Netflix Eureka(已进入维护模式)
- Consul(支持客户端发现)
- Zookeeper(传统方案,适合强一致性场景)
4.2. 服务端发现(Server-Side Discovery)
在这种模式下,服务调用请求先经过一个负载均衡器,由负载均衡器负责从注册中心获取服务实例并路由请求。
流程如下:
- 服务实例注册到注册中心;
- 服务消费者将请求发送到负载均衡器;
- 负载均衡器查询注册中心,选择一个实例进行转发。
优点:
- 服务消费者无需实现发现逻辑,简化客户端;
- 负载均衡逻辑统一,易于维护;
- 更适合多语言、多平台的混合架构。
缺点:
- 需要额外部署和管理负载均衡器;
- 多了一层网络跳转,可能影响性能。
常见实现工具包括:
- Kubernetes + kube-proxy(默认使用服务端发现)
- Nginx + Consul Template
- AWS ALB(Application Load Balancer)
5. 服务注册中心(Service Registry)
服务注册中心是服务发现的核心组件,本质上是一个高可用的数据库,用于存储服务实例的元数据(如 IP、端口、状态等)。
服务注册中心需要满足以下要求:
✅ 高可用性(High Availability):注册中心必须持续可用,否则整个服务发现机制失效。
✅ 强一致性(Consistency):多个注册中心节点之间数据必须同步,确保服务消费者获取到的信息准确。
✅ 快速响应(Low Latency):服务消费者频繁查询注册中心,延迟过高会影响系统性能。
常见的服务注册中心有:
- Consul:支持服务注册、健康检查、KV 存储,适合中小规模部署;
- Zookeeper:老牌注册中心,适用于对一致性要求高的系统;
- Eureka:Netflix 开源,已被 Consul 和 Kubernetes 逐渐取代;
- etcd:Kubernetes 默认使用 etcd 作为注册中心,适合云原生环境;
- Nacos:阿里巴巴开源,支持服务注册、配置中心、元数据管理等。
6. 服务注册方式
服务注册通常有两种方式:
6.1. 自注册(Self-Registration)
服务实例在启动后主动向注册中心注册自身信息,并定期发送心跳以维持注册状态。
优点:
- 实现简单,无需额外组件;
- 控制权在服务内部,适合轻量级架构。
缺点:
- 服务与注册中心耦合,需为不同语言/框架重复实现;
- 心跳机制复杂,容易出现注册信息过期。
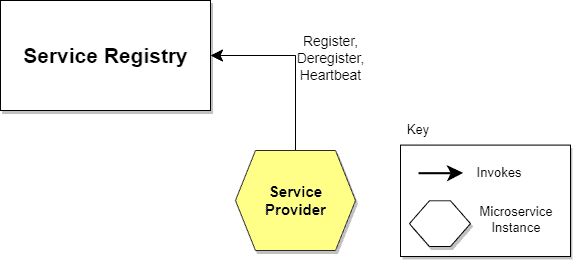
6.2. 第三方注册(Third-Party Registration)
由外部系统(如部署平台或注册中心本身)负责监控服务实例状态,并自动完成注册与注销。
优点:
- 服务与注册中心解耦,便于统一管理;
- 支持集中式注册逻辑,降低开发复杂度。
缺点:
- 需要额外组件支持,部署复杂;
- 依赖外部系统稳定性。
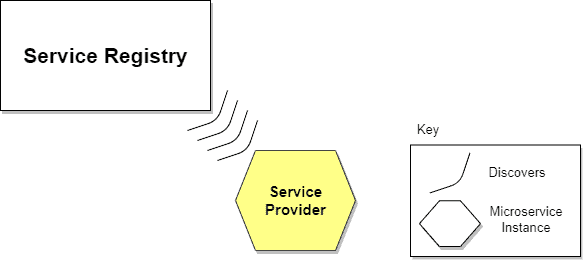
7. 总结
服务发现是微服务架构中不可或缺的一环,它解决了服务实例动态变化带来的通信难题。通过注册中心和发现机制,服务可以自动注册、注销,并被其他服务动态发现和调用。
两种主要的服务发现模式:
- 客户端发现:服务消费者负责查找和负载均衡,适合轻量级、多语言环境;
- 服务端发现:通过负载均衡器统一处理,适合大规模、云原生架构。
选择哪种方式取决于你的技术栈、部署环境和团队能力。在实际项目中,结合使用 Kubernetes + etcd 或 Nacos 是一种常见且成熟的方案。
如果你正在构建或维护一个微服务系统,服务发现是你必须掌握的核心技能之一。否则,你可能会在部署、扩容、故障转移等场景中频繁踩坑。