1. 概述
在图论中,最短路径问题存在多种变体。本文重点讨论其中一种:在带权图中找出一条从起点到终点,并且必须经过某些节点的最短路径。
我们将详细解释该问题,并提供多种解决方案。最后还会对这些方案进行比较,帮助你在不同场景下选择最优解。
2. 问题定义
我们给定一个带权无向图,目标是:
- 找出从源节点
S到目标节点G的最短路径; - 要求路径必须经过某些指定的节点(称为 must-visit nodes),顺序不限。
以如下图为例:
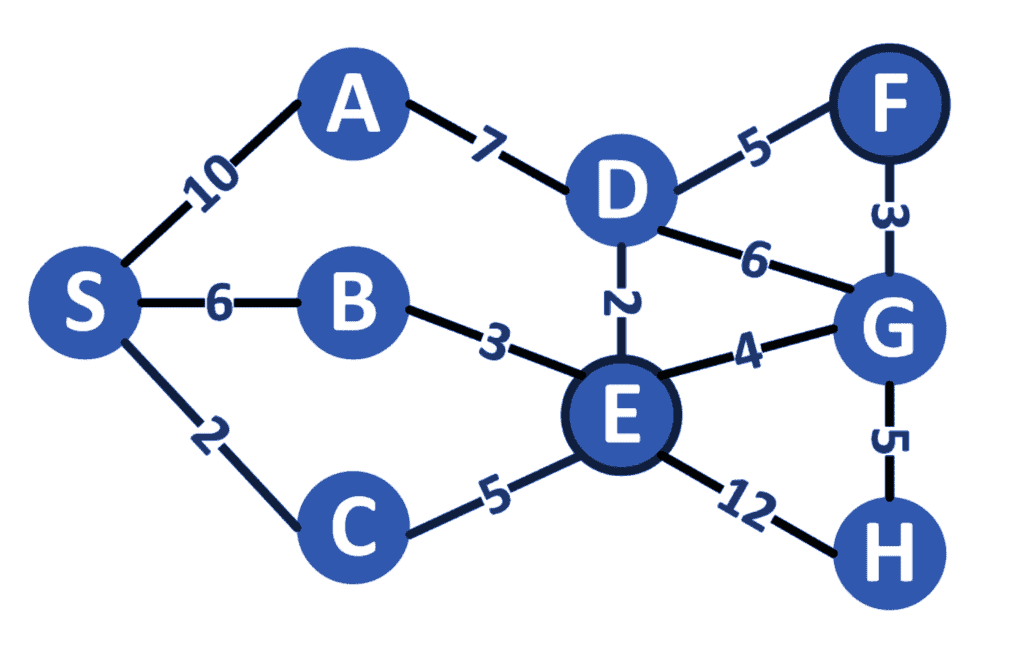
假设:
- 源节点为
S - 目标节点为
G - 必须访问的节点为
E和F
若不考虑必须访问的节点,最短路径是 S-C-E-G,总成本为 11。但若必须访问 E 和 F,则最优路径变为 S-C-E-D-F-G,总成本为 17。
⚠️ 注意:路径
S-B-E-D-F-G虽然也满足要求,但总成本为 19,不是最优解。
3. 二维 Dijkstra 解法
3.1 核心思想
传统的 Dijkstra 算法只记录从起点到每个节点的最短距离。但在本问题中,还需要知道已经访问了哪些 must-visit 节点。
因此,我们采用一个 二维距离数组:
- 第一维表示当前节点;
- 第二维表示一个 位掩码(bitmask),用于记录哪些 must-visit 节点已经被访问。
例如,若 must-visit 节点有 3 个,则位掩码长度为 3,每一位表示对应节点是否被访问。
最终结果存储在目标节点对应的所有状态中,取访问了所有 must-visit 节点的最小值即可。
3.2 算法实现
algorithm dijkstra2DSolution(source, goal, mustVisitNodes, m):
// 初始化一个二维距离数组,值为无穷大
distance <- initialize a matrix with infinity values
Q <- initialize an empty queue
// 将起点加入队列,初始访问状态为 0(即未访问任何 must-visit 节点)
Q <- push the tuple (source node, empty visited set, zero cost) onto Q
distance[source, 0] <- 0
while Q is not empty:
u <- get from Q the node with the lowest cost
if u.cost != distance[u.node, u.visited_set]:
continue
for v in neighbors(u.node):
new_visited_set <- u.visited_set
if v in mustVisitNodes:
vid <- the ID of the must visit node
new_visited_set |= (1 << vid) // 设置对应位为 1
newCost <- u.cost + edgeCost(u.node, v)
if newCost < distance[v, new_visited_set]:
distance[v, new_visited_set] <- newCost
Q <- push the tuple (v, new_visited_set, new cost)
// 找出目标节点中,访问了所有 must-visit 节点的最小路径
min_distance <- find the minimal distance and the visited set contains all required nodes
return min_distance
3.3 时间复杂度
- 时间复杂度:
O(2^m * (V + E * log(V * 2^m))) - 其中:
V是节点数;E是边数;m是 must-visit 节点数。
✅ 适用场景:当 must-visit 节点数 m 较小时(例如 ≤ 15),该算法效率较高。
4. 排列组合解法
4.1 核心思想
另一种思路是将问题转化为排列组合问题:
- 提取所有重要节点:包括源节点、目标节点和 must-visit 节点;
- 计算任意两个重要节点之间的最短路径;
- 枚举所有 must-visit 节点的排列顺序;
- 对每个排列计算路径总成本,取最小值。
4.2 最短路径计算方法
- Dijkstra 多次调用:适用于边数较少的情况(
E << V^2); - Floyd-Warshall 算法:适用于节点数较少的情况(
V小)。
4.3 算法实现
algorithm calculateShortestPathsPermutations(source, goal, mustVisitNodes, m):
permutations <- calculatePermutations(mustVisitNodes, m)
answer <- infinity
for permutation in permutations:
currentAnswer <- 0
prev <- source
for u in permutation:
currentAnswer <- currentAnswer + shortestPath(prev, u)
prev <- u
currentAnswer <- currentAnswer + shortestPath(prev, goal)
if currentAnswer < answer:
answer <- currentAnswer
return answer
4.4 时间复杂度
- 排列组合部分:
O(m * m!) - Dijkstra 部分:
O(m * (V + E * log V)) - Floyd-Warshall 部分:
O(V^3)
✅ 适用场景:
- 若
m很小(如 ≤ 10),使用 Dijkstra + 排列组合; - 若
V很小,使用 Floyd-Warshall + 排列组合。
5. 对比分析
| 算法 | 时间复杂度 | 适用场景 |
|---|---|---|
| 二维 Dijkstra | O(2^m * (V + E * log(V * 2^m))) |
m 较小(如 ≤ 15) |
| Dijkstra + 排列组合 | O((m * m!) + m * (V + E * log V)) |
E 较小 |
| Floyd-Warshall + 排列组合 | O((m * m!) + V^3) |
V 较小 |
6. 总结
本文介绍了在图中找出一条必须经过某些节点的最短路径的问题,并提供了两种主要解法:
- 二维 Dijkstra:适用于 must-visit 节点数较少的场景;
- 排列组合 + 最短路径算法:适用于 must-visit 节点顺序影响较大、节点数较小的场景。
选择哪种算法取决于图的规模和 must-visit 节点数量。在实际应用中,建议根据具体场景选择最优解。