1. 简介
跳表(Skip List)是一种基于概率的链表结构,它提供了对平衡树类似的时间复杂度,但实现更简单、更直观。跳表通过在链表中构建多层索引,使得查找、插入、删除等操作的平均时间复杂度为 O(log n)。
跳表的三个核心操作是:
✅ 插入
✅ 查找
✅ 删除
我们将通过图示和伪代码来说明这些操作是如何工作的。
2. 动机
想象一个有序单链表,如果我们想查找一个元素,最坏情况下需要遍历所有节点(O(n)):

如果我们给每隔一个节点添加一个“跳跃”指针,跳过两个节点,就可以减少查找时的访问次数:

进一步地,如果我们给每隔四个节点添加一个指针,访问次数会进一步减少。**如果每隔 2^k 个节点设一个跳跃指针,那么查找复杂度可以降到 O(log n)**。
跳表正是基于这个思想设计的。
3. 跳表作为概率结构
跳表的关键在于节点的层级是随机决定的,而不是固定分配。这样做的好处是:
✅ 插入和删除操作只需局部修改指针
✅ 不需要像平衡树那样频繁调整结构
3.1 层级的设置
我们可以使用如下伪代码随机决定一个节点的层级:
algorithm RandomLevel(p, maxLevel):
level <- 1
while (RANDOM() <= p) and (level < maxLevel):
level <- level + 1
return level
其中:
p是每次提升层级的概率(通常设为1/2)maxLevel是允许的最大层级(可以设为无限)
3.2 平均层级
节点层级减1服从几何分布,因此期望值为:
$$ \mathbb{E}[level] = \frac{1}{1 - p} $$
例如,当 p = 1/2 时,平均层级为 2。
3.3 指针数量分析
跳表中指针的总数期望为:
$$ n(1 + p) $$
由于 p 是常数,所以跳表的空间复杂度为 O(n),与普通链表相同。
3.4 节点与跳表结构定义
每个节点包含:
value:节点值successors[]:指向不同层级后继节点的数组
跳表结构包含:
maxLevel:当前跳表的最大层级heads[]:各层级头节点的指针数组
4. 插入操作
插入一个值为 v 的节点需要完成以下步骤:
- 查找插入位置
- 随机决定节点层级
- 更新各层级指针
4.1 伪代码
algorithm InsertIntoSkipList(head, v, maxLevel):
level <- RandomLevel(maxLevel)
if level > list.maxLevel:
for k <- list.maxLevel + 1 to level:
list.heads[k] <- make an empty node (NULL)
list.maxLevel <- level
update <- make an empty array with level reserved elements
y <- make a node whose value is v
for k <- list.maxLevel down to 1:
x <- list.heads[k]
if x is empty:
list.heads[k] <- y
else:
z <- x.successors[k]
while (z != NULL) and (v > z.value):
x <- z
z <- z.pointers[k]
x.successors[k] <- y
y.successors[k] <- z
4.2 示例
插入 17 后跳表的变化如下(新节点为红色):

4.3 时间复杂度
插入操作的时间复杂度主要由查找决定,因此是 O(log n)(期望值)。
5. 查找操作
查找操作与插入类似,但不修改指针。从顶层头节点开始,逐步向下查找直到找到目标值或确定不存在。
5.1 伪代码
algorithm Search(list, v):
x <- list.heads[list.maxLevel]
for k <- list.maxLevel to 1:
if x = NULL:
x <- list.heads[k]
while x.successors[k] != NULL and x.successors[k].value < v:
x <- x.successors[k]
if x.successors[1] != NULL and x.successors[1].value = v:
return x.successors[1]
else:
return failure
5.2 示例
查找 17 的过程如下:
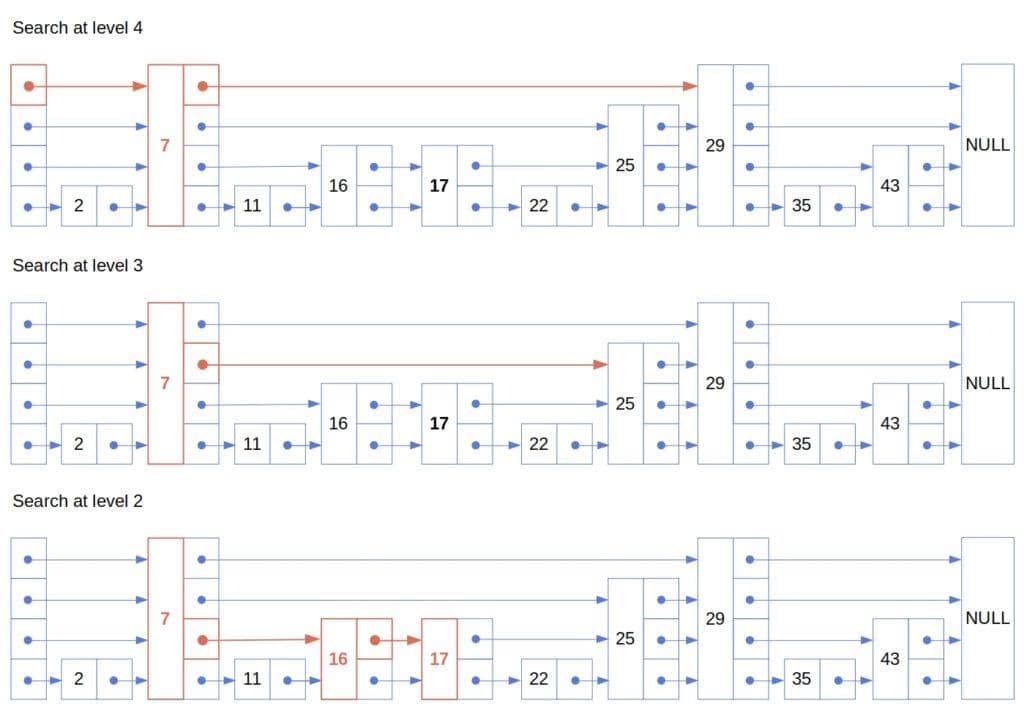
5.3 时间复杂度分析
跳表查找路径的期望长度为:
$$ O\left( \frac{\ell}{p} + p^{\ell}n \right) $$
若选择合适的 ℓ(如 log n),该复杂度可降为 O(log n)。
6. 删除操作
删除操作也类似插入和查找:
- 查找目标节点
- 记录指向它的节点
- 修改指针,跳过目标节点
- 若顶层节点为空,降低
maxLevel
6.1 伪代码
algorithm Delete(list, v):
update <- make an empty array with list.maxLevel NULL elements
for k <- list.maxLevel down to 1:
x <- list.heads[k]
y <- x.successors[k]
while y != NULL and v > y.value:
x <- y
y <- x.successors[k]
if y != NULL:
if y.value = v:
update[k] <- x
if y.value = v:
for k <- 1 to list.maxLevel:
if update[k] != NULL:
update[k].successors[k] <- y.successors[k]
while list.maxLevel > 1 and list.heads[list.maxLevel] = NULL:
list.maxLevel <- list.maxLevel - 1
6.2 时间复杂度
删除操作同样由查找主导,因此也为 O(log n)(期望值)。
7. 总结
跳表是一种基于概率的高效链表结构,具有以下优点:
✅ 实现简单
✅ 插入、查找、删除平均时间复杂度为 O(log n)
✅ 空间复杂度为 O(n)
❌ 最坏情况复杂度为 O(n),但概率极低
跳表在实际中广泛使用,例如 Java 中的 ConcurrentSkipListMap 和 Redis 的有序集合(ZSet)底层实现。
如果你追求性能与实现简洁的平衡,跳表是一个非常值得掌握的数据结构。