1. 概述
在本文中,我们将介绍一种用于 3D 重建的技术:空间雕刻(Space Carving)。
我们会先了解 3D 重建的基本概念,然后深入探讨空间雕刻的适用场景与前提假设,最后分析其局限性。
2. 3D 重建简介
在计算机视觉领域,一个非常有趣且应用广泛的问题是:如何从一组二维图像中重建出物体的三维表示。
人类可以轻松完成这个任务,哪怕只有一张图片,只要物体足够规则且我们熟悉它。例如,即使只从一个角度看一个杯子、球或书,我们也能直观地想象出它的完整 3D 形状。类似地,基于深度学习的方法也能从少量图像中生成 3D 表示,前提是训练过程中使用了类似对象的数据。
但这些方法通常依赖于对物体形状的先验知识。与之不同的是,空间雕刻不依赖于物体形状的任何先验假设,而是通过多视角图像拼接信息来完成重建。
3. 空间雕刻原理
通常情况下,3D 重建需要从尽可能多的角度拍摄物体的照片。这可以通过使用多个固定在不同位置的相机,或者用一个相机从多个角度拍摄同一物体来实现。
在这两种情况下,拍摄背景应尽量简单,以便仅通过颜色信息即可完成图像分割。
3.1 体素网格初始化
空间雕刻从一个体素网格(voxel grid)开始。它类似于图像中的像素表示,但扩展到了三维空间。我们假设目标物体完全包含在这个体素网格中。
3.2 逐步“雕刻”过程
通过第一张图像的信息,我们可以判断哪些体素不属于物体本身。
接着,我们以类似从大理石块中雕刻雕像的方式,逐步“切掉”不属于物体的区域。随着从不同视角拍摄的图像不断输入,我们可以从多个角度继续雕刻,最终在体素空间中得到一个较为准确的物体近似。
下图展示了一个从上往下看的空间雕刻过程:
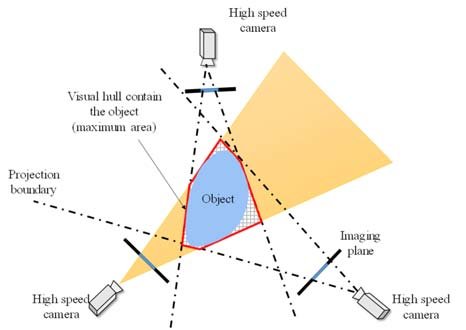
图中展示了 3 个不同位置的相机视角。每个相机都有自己的视野范围,并且随着距离变远而扩大。真实物体位于这 3 个视野的交集中。
显然,使用的相机越多,重建效果越好,因为可以从更多角度进行雕刻。
4. 局限性分析 ❌
尽管空间雕刻是一个强大且直观的方法,但它也有一些明显的限制:
- 无法重建物体内部空洞:如果使用的相机没有深度检测功能(如激光雷达),则无法重建物体内部的空洞区域。例如,一个杯子内部的空心部分将无法被识别。
- 不考虑光照与阴影信息:空间雕刻仅根据像素是否属于背景或物体进行判断,忽略了光照和阴影的影响。
这些限制意味着,空间雕刻更适合于表面重建,而不是完整的体积重建。
5. 总结 ✅
在本文中,我们介绍了空间雕刻这一 3D 重建技术的核心原理与应用场景。它是一种不依赖物体形状先验知识的通用方法,适用于从多视角图像中重建物体表面。
但该方法也存在明显局限,尤其是在处理遮挡和内部空洞时。若要突破这些限制,可以考虑引入带有深度信息的相机设备,如 RGB-D 相机或 LiDAR。
如需进一步提升重建精度,还可以结合深度学习方法进行后处理,这也是当前 3D 重建研究的热点方向之一。