1. 简介
在本教程中,我们将探讨特征缩放(Feature Scaling)对支持向量机(SVM)模型的影响。
我们会先回顾 SVM 的基本原理和特征缩放的概念,然后通过一个 Python 示例来展示特征缩放如何显著影响 SVM 的分类性能。最后通过比较缩放前后模型的准确率与 F1 分数,来验证特征缩放的必要性。
2. SVM 与特征缩放
SVM(Support Vector Machine)是一种用于分类和回归任务的监督学习算法。它在高维空间中表现良好,且在内存使用上较为高效。
训练 SVM 模型的核心在于寻找一个最优决策边界(Decision Boundary),该边界与最近的两类样本点之间的距离最大。因此,SVM 也被称为最大间隔分类器(Maximum Margin Classifier):
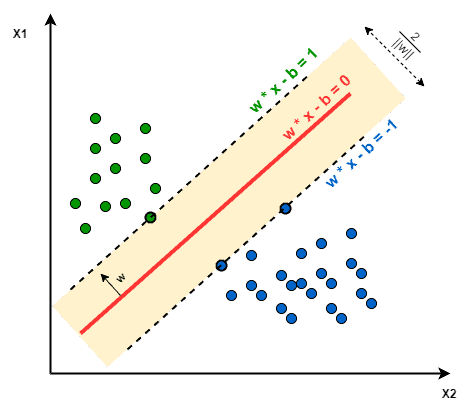
需要注意的是,SVM 本身不支持多分类,通常我们会使用 One-vs-One 或 One-vs-Rest 的方式来构建多分类模型。
特征缩放指的是将不同特征的取值范围统一到一个相对标准的区间内。这在某些依赖于样本间距离的算法中尤为重要,因为特征缩放会直接影响样本之间的距离计算。
由于 SVM 的决策边界是基于样本点之间的距离建立的,因此特征缩放与否会直接影响模型的构建结果。换句话说,使用未缩放和缩放后的数据训练出的 SVM 模型可能是完全不同的。
最常见的两种特征缩放方法是:
✅ 归一化(Normalization):将数据缩放到 [0, 1] 区间
$$ z = \frac{x - \min(x)}{\max(x) - \min(x)} $$✅ 标准化(Standardization):将数据转换为均值为 0,标准差为 1 的分布
$$ z = \frac{x - \mu}{\sigma} $$
标准化通常更适用于训练新数据,因为它对异常值的容忍度更高,因此在实际应用中我们更倾向于使用标准化方法。
3. 在 Python 中实现 SVM
为了展示特征缩放对 SVM 的影响,我们将使用 Wine 数据集进行实验。该数据集包含 13 个实数特征,分别对应三种葡萄酒的化学成分分析结果。
首先我们对原始数据进行可视化,使用箱线图展示各特征的分布情况:
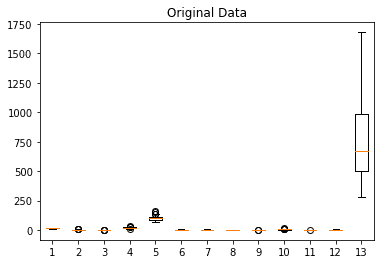
然后我们使用默认参数训练一个 SVM 分类器:
from sklearn import svm
from sklearn import metrics
clf = svm.SVC()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
print("F-1 Score:", metrics.f1_score(y_test, y_pred, average=None))
输出结果如下:
Accuracy: 0.7592592592592593
F-1 Score: [1. 0.74509804 0.31578947]
可以看到,使用原始数据训练的 SVM 模型在测试集上的准确率为 75.9%,而第三个类别的 F1 分数仅为 0.31,说明分类效果较差。
4. 在 Python 中进行特征缩放
接下来我们对数据进行标准化处理,使用 StandardScaler 对训练集进行拟合并对整个数据集进行转换:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().fit(X_train)
X_std = scaler.transform(X)
标准化后的特征分布如下图所示,可以看到各特征的均值接近 0,标准差接近 1:
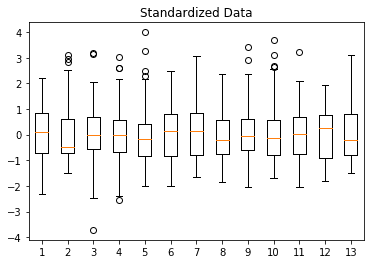
然后我们使用标准化后的数据重新训练 SVM 模型:
clf_std = svm.SVC()
clf_std.fit(X_std_train, y_train)
y_pred_std = clf_std.predict(X_std_test)
print("Accuracy:", metrics.accuracy_score(y_test, y_pred_std))
print("F-1 Score:", metrics.f1_score(y_test, y_pred_std, average=None))
输出结果如下:
Accuracy: 0.9814814814814815
F-1 Score: [1. 0.97674419 0.96296296]
可以看到,使用标准化后的数据训练的模型准确率提升到了 98.1%,三个类别的 F1 分数也都有显著提升,尤其是原本表现最差的第三类。
我们还可以通过 n_support_ 属性查看每个类别对应的支持向量数量:
print(clf.n_support_) # 原始模型
print(clf_std.n_support_) # 标准化模型
输出结果:
[15 34 34] # 原始模型
[15 27 18] # 标准化模型
可以看到,两个模型在第二、第三类的支持向量数量上有明显差异,进一步说明了特征缩放对模型结构的影响。
5. 总结
通过本篇文章,我们了解了:
- ✅ SVM 是一种基于样本间距离构建决策边界的分类器
- ✅ 特征缩放会显著影响 SVM 的分类效果
- ✅ 使用标准化方法可以显著提升模型性能
- ✅ 在实际训练中,务必对数据进行适当的预处理,避免因特征尺度差异导致模型“踩坑”
结论:特征缩放在 SVM 中至关重要,标准化处理能够显著提升模型的准确率与泛化能力。