1. Introduction
In this tutorial, we’ll talk about the Synthetic Minority Oversampling Technique (SMOTE) and its advantages and disadvantages.
We’ll provide helpful tips and share best practices.
2. Why Is SMOTE Required?
In machine learning, classification is a task that aims to assign a category or label to data points. This task can involve classifying emails as spam or non-spam or medical images as showing disease or not, and it revolves around making predictions (decisions) based on data characteristics.
Ideally, in a classification problem, the dataset is balanced. This means we have approximately the same number of data points in each class. Such proportional representation assists algorithms in learning and generalizing more effectively, as they have access to a similar number of examples for each category.
2.1. Imbalanced Data
However, in real-world scenarios, we usually have imbalanced data. One or more classes have significantly fewer instances/data points than others.
This class imbalance can occur for various reasons, such as one class representing rare events. For instance, that’s the case in medical diagnosis classification tasks. In such datasets:
- Class 0 represents patients without the rare disease.
- Class 1 represents patients with the rare disease.
The rare disease is infrequent in the population, so there are significantly fewer patients with it than those without it. This leads to a class imbalance issue.
2.2. Challenges With Imbalanced Data
Training classification algorithms on imbalanced data can lead to models biased toward the majority class because there are more such samples to learn from. This results in strong performance on the majority class but weak performance on the minority class.
Even a poorly performing model can achieve a high overall accuracy if the majority class dominates the dataset. However, this accuracy can be misleading, as the model’s performance on the minority class might be very poor.
In our medical example, 99% of the population may be without a medical condition. So, approximately 1% of patient records belong to class 1. A model that classifies all the patients to class 0 will have an accuracy of 99%, but it will fail to detect all class-1 patients.
In addressing imbalanced data, various techniques are available, with one approach being SMOTE (Synthetic Minority Oversampling Technique).
3. What Is SMOTE?
It’s a data augmentation that mitigates the effects of class imbalance by generating synthetic examples for the minority class. Ultimately, this enhances the performance and reliability of machine learning models.
Researchers commonly use SMOTE to preprocess data before training classification models, including logistic regression, decision trees, random forests, and support vector machines.
This technique holds particular value in applications such as fraud detection, medical diagnosis, and others where one class significantly outnumbers the other.
SMOTE has many variations and extensions: Borderline-SMOTE, ADASYN (Adaptive Synthetic Sampling), SMOTE-NC (SMOTE for Nominal and Continuous Features), and SVM-SMOTE.
3.1. Algorithm
Let’s check out the original formulation (as presented in a recent research paper):

SMOTE generates new data by interpolating between randomly selected minority-class instances and their randomly chosen nearest neighbors from the minority class.
3.2. Interpolation
The interpolation process is random. Once we select a real-data instance and one of its nearest neighbors, we draw a random number from [0, 1] to generate a point between them:
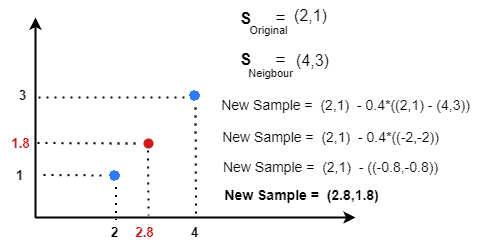
We can get a more balanced set by adding the desired number of synthetic data:
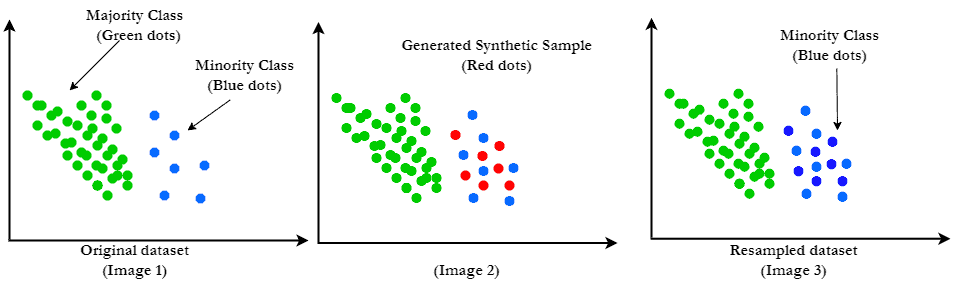
4. Advantages and Disadvantages
SMOTE has both advantages and disadvantages.
4.1. Advantages
A key benefit of SMOTE is its ability to improve the performance of machine-learning models. It achieves this by generating synthetic examples for the minority class, which aids in the more effective learning of underlying patterns and decision boundaries.
It helps reduce overfitting in imbalanced datasets where models excel in training data but struggle with unseen data. SMOTE helps create a more generalizable model by generating new data.
SMOTE supports many classifiers, including decision trees, support vector machines, nearest neighbors, and neural networks.
This flexible technique allows for adjustments in the level of oversampling and the characteristics of synthetic samples, making it suitable for various scenarios and dataset sizes.
Implementation is relatively straightforward and is available in various libraries and packages for different programming languages, such as Python and R.
4.2. Disadvantages
A drawback of SMOTE is that it doesn’t consider the majority class while creating synthetic samples.
Additionally, it can create synthetic samples between samples that represent noise. As a result, the augmented dataset will have more noise than the original one, which can hurt performance.
It’s less effective in high-dimensional feature spaces. Because SMOTE generates synthetic samples by interpolating between neighboring examples, it can fail to capture more complex patterns.
4.3. Summary
Here’s a quick summary of the advantages and disadvantages of SMOTE:
Advantages
Disadvantages
Improves performance.
Increases computational complexity.
Balances datasets.
Not suitable for all datasets.
It’s not limited to specific machine learning algorithms.
Incompatible with regression problems.
Easy implementation.
It can lose the subtleties of the original data.
5. Conclusion
In this article, we discussed SMOTE, a data augmentation technique in machine learning. Its primary goal is to mitigate the effects of class imbalance by generating synthetic instances for the minority class, thereby enhancing machine learning models’ learning and generalization capabilities.