1. 简介
在机器学习领域,有很多技术术语中都包含“learning”这个词,例如深度学习(deep learning)、强化学习(reinforcement learning)、监督学习(supervised learning)、无监督学习(unsupervised learning)、主动学习(active learning)、元学习(meta-learning)和迁移学习(transfer learning)等。虽然都叫“学习”,但它们之间差异很大,唯一的共同点是都属于机器学习的范畴。
对于刚接触这个领域的人来说,这些术语听起来可能很相似,容易混淆。本文将重点解释其中两个概念:迁移学习(Transfer Learning) 和 元学习(Meta-Learning),并通过示例帮助你更好地理解它们之间的区别。
2. 迁移学习(Transfer Learning)
迁移学习是一种在深度学习中非常常见的技术,其核心思想是利用已有的预训练模型来完成新的任务。
✅ 举个例子:你可以将一个已经训练好的图像分类模型(比如用于识别猫和狗的模型)稍作修改,用于识别新的类别(比如兔子),而不需要从头训练整个网络。
迁移学习通常的做法是:
- 保留模型的大部分结构和参数(尤其是前面的层)
- 替换或微调(fine-tune)最后几层,以适配新任务
2.1 为什么迁移学习有效?
神经网络在训练过程中会逐步学习不同层次的特征。比如在图像识别任务中:
- 前几层通常学习低级特征,如边缘、点、曲线等
- 后面的层则学习更高级、抽象的特征(如眼睛、耳朵等)
✅ 低级特征通常是通用的,适用于很多图像任务。因此,我们可以直接复用这部分网络结构和参数,只需根据新任务微调高级层。
迁移学习特别适用于:
- 数据量小的场景
- 计算资源有限的情况
- 任务之间有相似性的数据集
3. 元学习(Meta-Learning)
元学习(Meta-Learning)中的“meta”表示“更高一层”或“抽象的”,比如“元数据(metadata)”是描述数据的数据。类似地,元学习是“关于学习的学习”。
❌ 不同于传统的机器学习方法,元学习不是直接从原始数据中学习模型,而是从其他机器学习模型的输出中学习。
3.1 元学习的典型应用场景
一个最典型的元学习技术是 Stacking(堆叠),它是一种集成学习方法,通过组合多个模型的预测结果来提升整体性能。
工作流程如下:
- 使用训练集训练多个基础模型(如SVM、决策树、随机森林等)
- 将这些模型在验证集上的预测结果作为输入特征
- 训练一个“元模型”(meta-model)来学习如何最好地组合这些预测结果
举个图示:
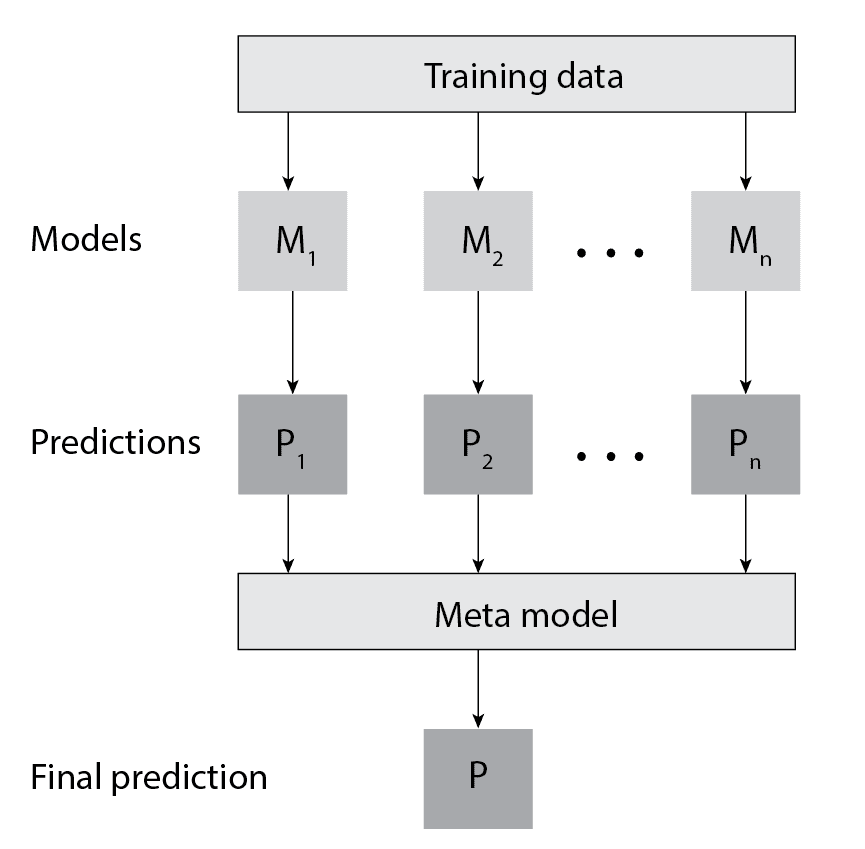
⚠️ 注意:为了防止过拟合,Stacking通常会使用交叉验证(cross-validation)来生成元特征。
3.2 其他元学习类型
- 元学习优化器(Meta-learning Optimizers):用于优化神经网络的学习过程,使其在新数据上更快适应。
- 度量元学习(Metric Meta-Learning):目标是学习一个特征空间,使得相似样本之间的距离更近,不相似的更远。
4. 总结
- ✅ 迁移学习 是复用已有模型的参数和结构,用于新任务,适用于任务之间有相似性的场景。
- ✅ 元学习 是在模型输出的基础上进行学习,用于提升模型组合效果或学习如何学习。
一句话总结:
迁移学习是“复用模型”,元学习是“学习模型的输出”或“学习如何学习”。