1. 简介
在本教程中,我们将探讨树编辑距离(Tree Edit Distance,TED)及其计算方法。与字符串编辑距离类似,TED 是用于衡量两个树结构之间差异的指标,常用于程序分析、XML文档比较、生物信息学等领域。
树编辑距离的核心思想是:通过一系列最小代价的操作将一棵树转换为另一棵树。常见的操作包括:
- 插入节点(Insert)
- 删除节点(Delete)
- 重命名节点(Relabel)
2. 树编辑距离(TED)定义
树编辑距离是将一棵树 $ T_1 $ 转换为另一棵树 $ T_2 $ 所需的最小操作代价总和。这些操作通常包括:
relabel(u, v):将节点 $ u $ 的标签改为 $ v $delete(u):删除节点 $ u $insert(u):插入节点 $ u $
每种操作可以设定不同的代价,最终 TED 是使 $ T_1 \rightarrow T_2 $ 的最小代价序列的总代价。
2.1 示例
考虑如下两棵树:
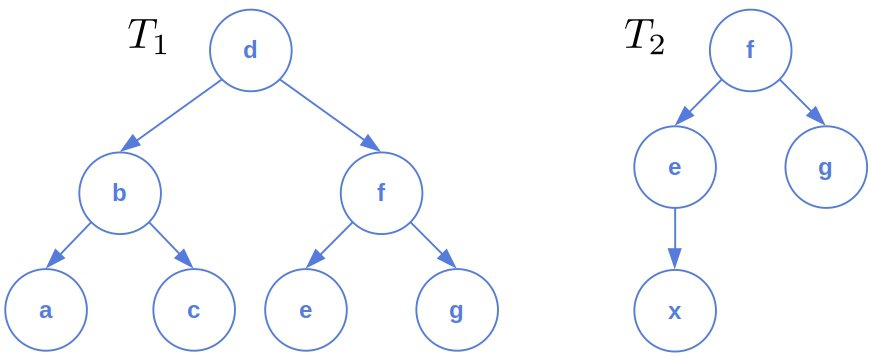
设定操作代价如下:
$$ \text{cost(relabel)} = 2,\quad \text{cost(delete)} = \text{cost(insert)} = 3 $$
最小代价操作序列为:
$$ \begin{aligned} \text{delete } & c, e, g \ \text{relabel } & f \rightarrow g, d \rightarrow f, b \rightarrow e, a \rightarrow x \ \end{aligned} $$
总代价为 17,因此:
$$ \text{TED}(T_1, T_2) = 17 $$
2.2 TED 的意义
TED 的值依赖于操作定义和代价设定。不同的代价模型会导致不同的 TED 值。因此,在具体应用中应根据业务场景合理定义操作和代价。
如果 TED 满足距离度量的四个公理(非负性、对称性、三角不等式、自反性),则它定义了一个树的度量空间,可用于树结构的数学分析。
3. 通用递归计算方法
我们可以用递归方式定义 TED:
$$ \text{TED}(T_1, T_2) = \begin{cases} 0, & T_1 = T_2 \ \min_{a \in \mathcal{A}(T_1)} \left{ \text{cost}(a) + \text{TED}(a(T_1), T_2) \right}, & \text{otherwise} \end{cases} $$
其中:
- $\mathcal{A}(T)$ 表示可对树 $ T $ 执行的操作集合
- $\text{cost}(a)$ 是操作 $ a $ 的代价
这个递归可能导致指数级复杂度,但在引入 记忆化(Memoization) 后可以优化。例如,将树结构哈希后缓存中间结果,避免重复计算。
4. 基于节点的 TED 算法
我们重点讨论一种基于节点操作的 TED 算法,操作包括:
delete(u):删除节点 $ u $,其子节点继承为父节点的子节点relabel(u, v):将节点 $ u $ 的标签更改为 $ v $insert(u, parent):插入节点 $ u $ 并指定其父节点
4.1 假设与说明
- 节点具有左右顺序
- 每个节点最多被插入、删除或重命名一次
- 操作代价为常数:$ c_{del}, c_{ins}, c_{rel} $
插入节点 $ u $ 到 $ T_1 $ 等价于从 $ T_2 $ 中删除该节点,因此我们只需考虑删除和重命名操作。
4.2 使用森林计算 TED
该算法在中间步骤中处理森林(多个子树)。通过后序遍历编号节点,定义子森林 $ T[i..j] $ 为编号从 $ i $ 到 $ j $ 的节点组成的森林。
例如:
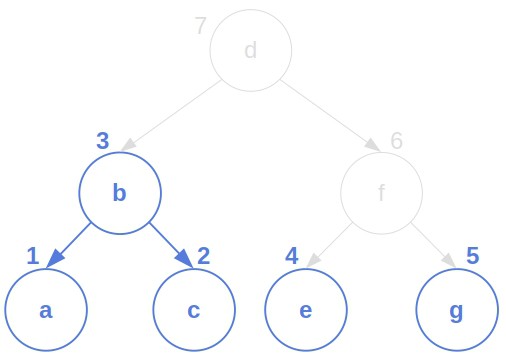
这样可以使用 动态规划 方法将问题分解为子问题。
4.3 递推公式
设 $ F_1 = T_1[i..j] $,$ r_1 $ 是其最右根节点,$ R_1 $ 是其最右子树。同理定义 $ F_2 $。
TED 的递推公式如下:
$$ \text{TED}(F_1, F_2) = \min \begin{cases} \text{TED}(F_1 - r_1, F_2) + c_{del} \ \text{TED}(F_1, F_2 - r_2) + c_{ins} \ \text{TED}(F_1 - R_1, F_2 - R_2) + c_{rel} + \text{TED}(R_1 - r_1, R_2 - r_2) \end{cases} $$
4.4 算法实现(使用记忆化)
我们使用一个哈希表缓存每个子问题的计算结果,键为四元组 $ (i_1, j_1, i_2, j_2) $,表示当前处理的两个子森林。
algorithm TEDMemoized(T1, T2, n, m):
// INPUT
// T1 = the tree to transform
// T2 = the tree to transform T1 into
// n = the number of nodes in T1
// m = the number of nodes in T2
// T1 and T2 have been preprocessed to determine the left boundaries ℓ(·) for all the nodes
// results = the storage for the results, initially empty
// OUTPUT
// The tree edit distance between T1 and T2
if results[T1, T2] is known:
return results[T1, T2]
if T1 is empty and T2 is empty:
return 0
if T1 is not empty and T2 is empty:
r1 <- find the rightmost root of T1
return cost_del + TED(T1 - r1, empty set)
if T1 is empty and T2 is not empty:
r2 <- find the rightmost root of T2
return cost_ins + TED(empty set, T2 - r2)
Determine r1, R1, r2, R2
ted_del <- TED(T1 - r1, T2) + cost_del
ted_ins <- TED(T1, T2 - r2) + cost_ins
ted_rel <- TED(T1 - R1, T2 - R2) + cost_rel + TED(R1 - r1, R2 - r2)
results[T1, T2] <- min{ted_del, ted_ins, ted_rel}
return results[T1, T2]
4.5 算法复杂度
该算法基于 Zhang-Shasha 的方法,其时间复杂度为:
$$ O(d_1 d_2 n m) $$
其中:
- $ d_1, d_2 $:树 $ T_1, T_2 $ 的 keyroot 深度
- $ n, m $:两棵树的节点数
若树是平衡的,则复杂度为:
$$ O(n \log n \cdot m \log m) $$
若树退化为链表(类似链表),则复杂度为:
$$ O(n^2 m^2) $$
4.6 回溯操作序列
在计算 TED 时,我们可以记录每一步选择的操作(删除、插入、重命名),从而在最终结果计算完成后回溯出完整的操作序列。
5. 小结 ✅
| 要点 | 说明 |
|---|---|
| TED 定义 | 最小代价将 $ T_1 $ 转换为 $ T_2 $ |
| 操作类型 | delete、insert、relabel |
| 复杂度 | $ O(d_1 d_2 n m) $,使用记忆化优化 |
| 适用场景 | XML 比较、程序分析、生物信息学等 |
| 注意事项 | 合理定义操作代价,注意节点顺序和唯一操作限制 |
树编辑距离是一个强大的结构相似度衡量工具,尤其适用于结构化数据的比较。虽然其计算复杂度较高,但通过合理的算法设计和优化(如记忆化、预处理)可以有效提升性能。