2. 项目初始化
在正式开发前,我们需要完成两项准备工作:创建Fauna数据库和搭建Spring应用基础框架。
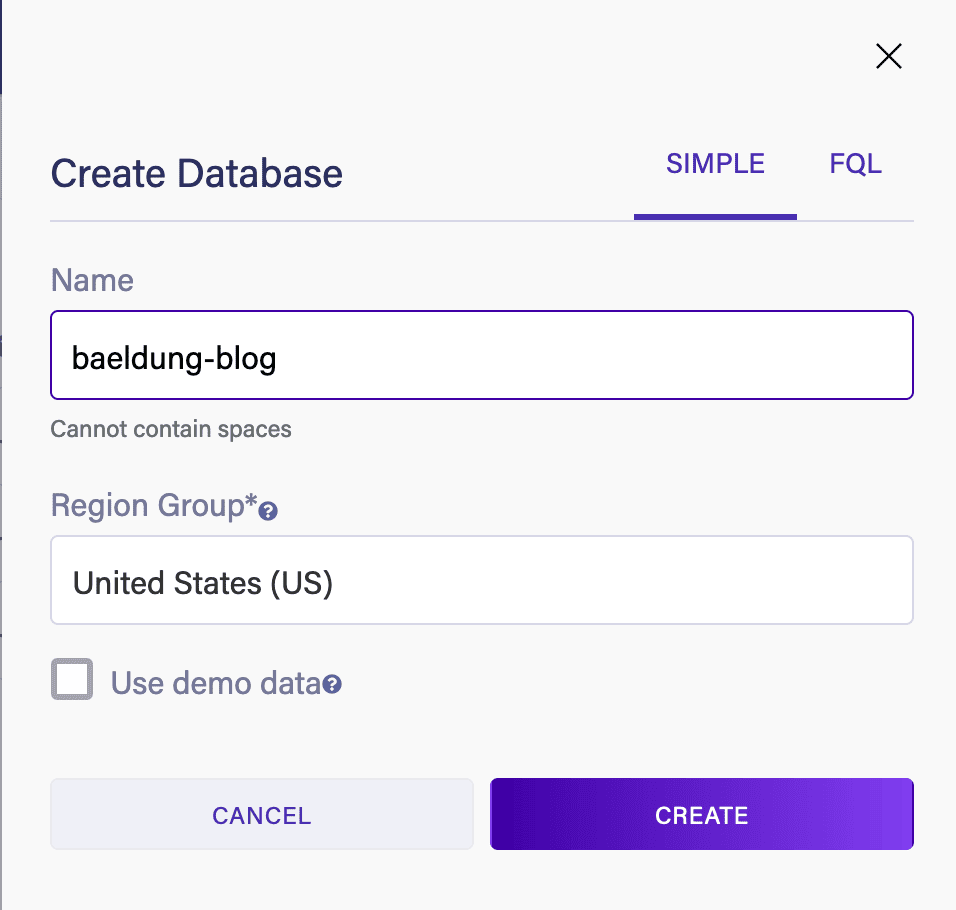
2.1. 创建Fauna数据库
首先需要准备一个Fauna数据库实例。如果没有账号,请先注册:Fauna控制台。
创建数据库的步骤:
- 给数据库命名并选择区域
- 取消勾选"包含演示数据"(我们自定义schema)
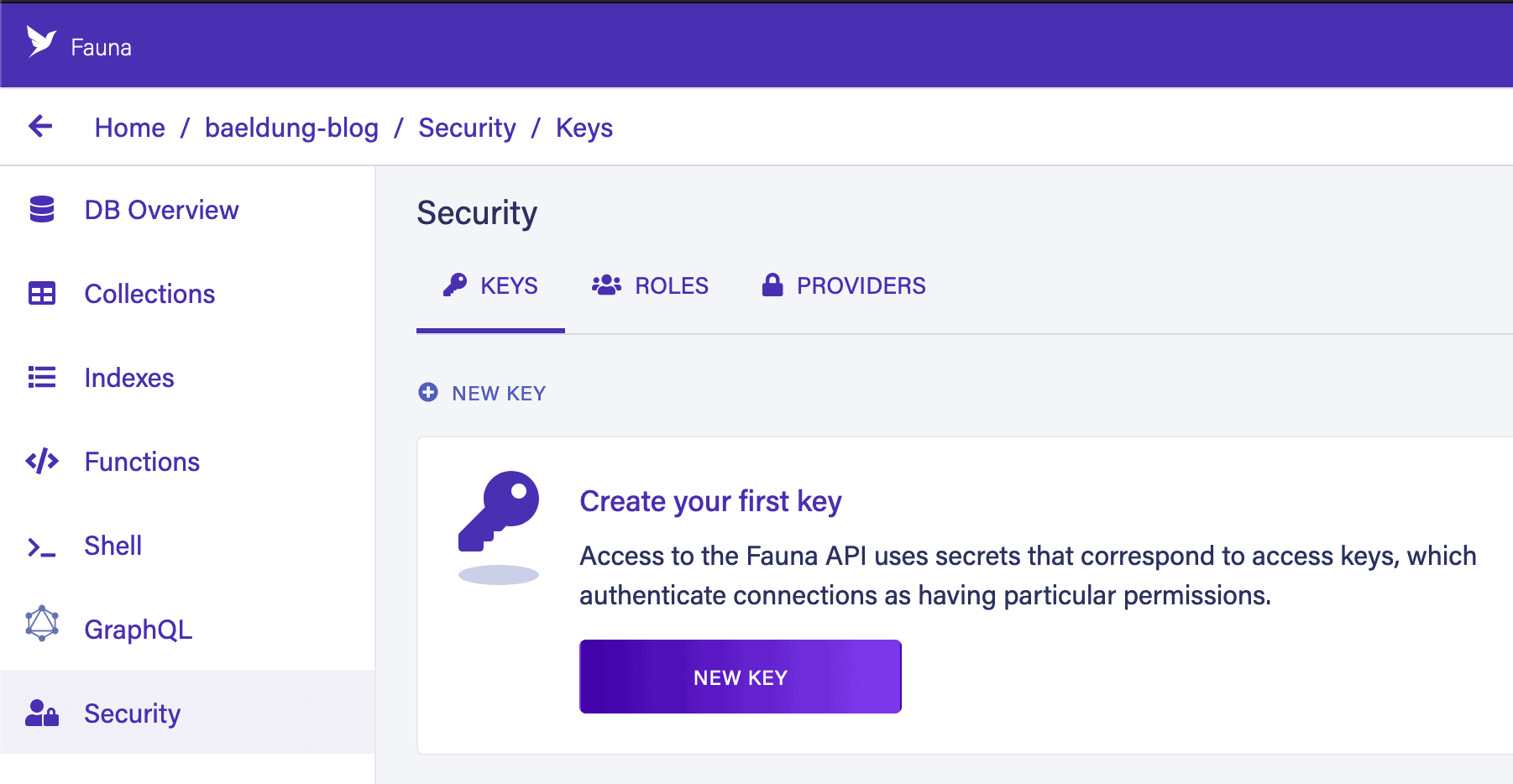
接下来需要创建安全密钥:
- 进入数据库的"Security"标签页
- 选择"Server"角色(可选填密钥名称)
- 点击"保存"后立即记录密钥(离开页面后将无法再次查看)
注意:Server角色密钥只能访问当前数据库,Admin角色可访问账户下所有数据库。
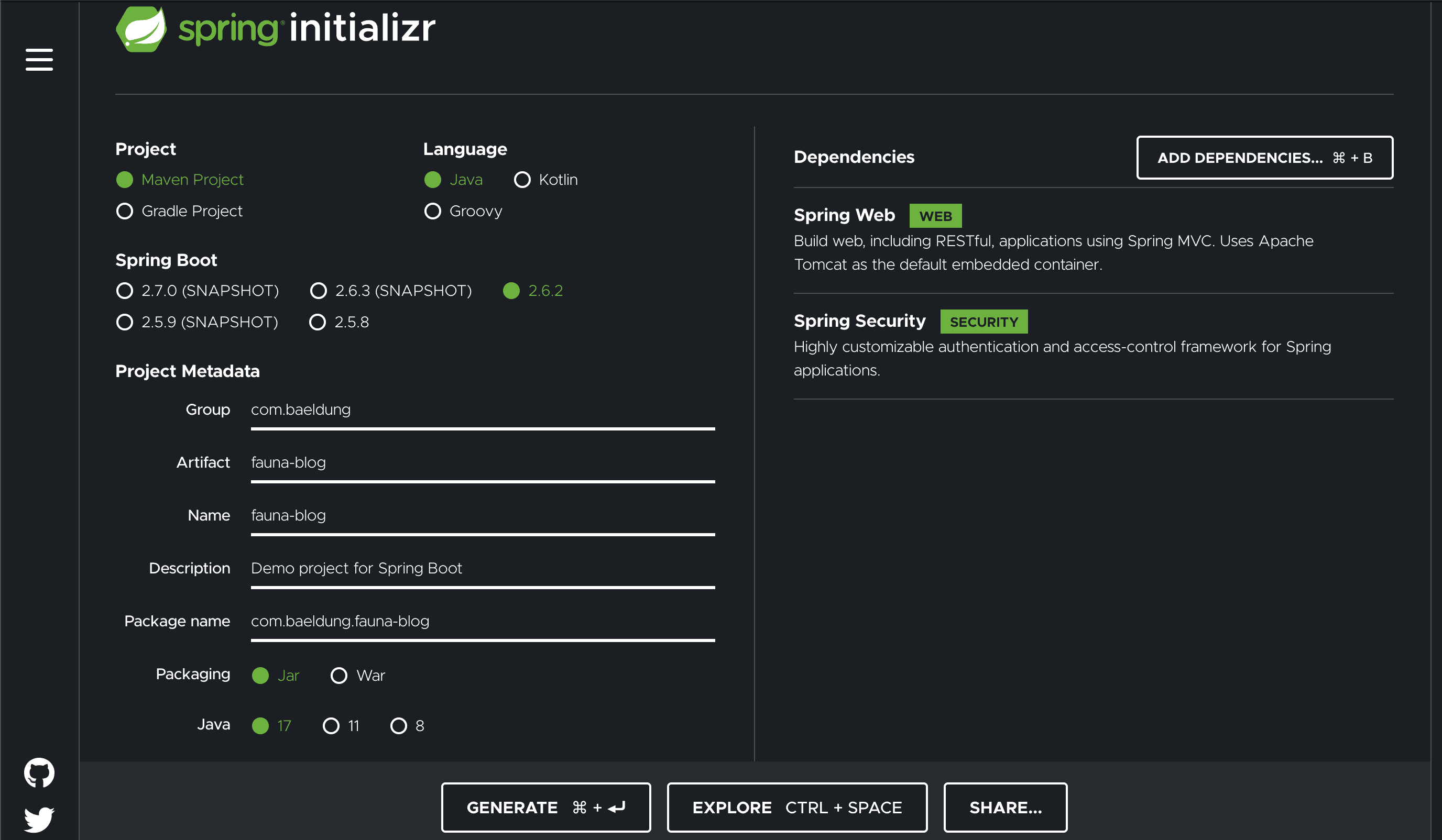
2.2. 创建Spring应用
使用Spring Initializr生成项目骨架:
- 选择Maven项目
- 使用最新Spring版本(示例为2.6.2)和Java LTS版本(示例为Java 17)
- 添加依赖:Spring Web、Spring Security
生成项目后,在pom.xml中添加Fauna驱动依赖:
<dependency>
<groupId>com.faunadb</groupId>
<artifactId>faunadb-java</artifactId>
<version>4.2.0</version>
<scope>compile</scope>
</dependency>
执行mvn install验证依赖下载成功。
2.3. 配置Fauna客户端
在application.properties中添加配置:
fauna.region=us
fauna.secret=fnA... # 替换为你的密钥
创建配置类初始化FaunaClient:
@Configuration
class FaunaConfiguration {
@Value("https://db.${fauna.region}.fauna.com/")
private String faunaUrl;
@Value("${fauna.secret}")
private String faunaSecret;
@Bean
FaunaClient getFaunaClient() throws MalformedURLException {
return FaunaClient.builder()
.withEndpoint(faunaUrl)
.withSecret(faunaSecret)
.build();
}
}
3. 用户模块开发
在实现博客功能前,需要先构建用户认证体系。
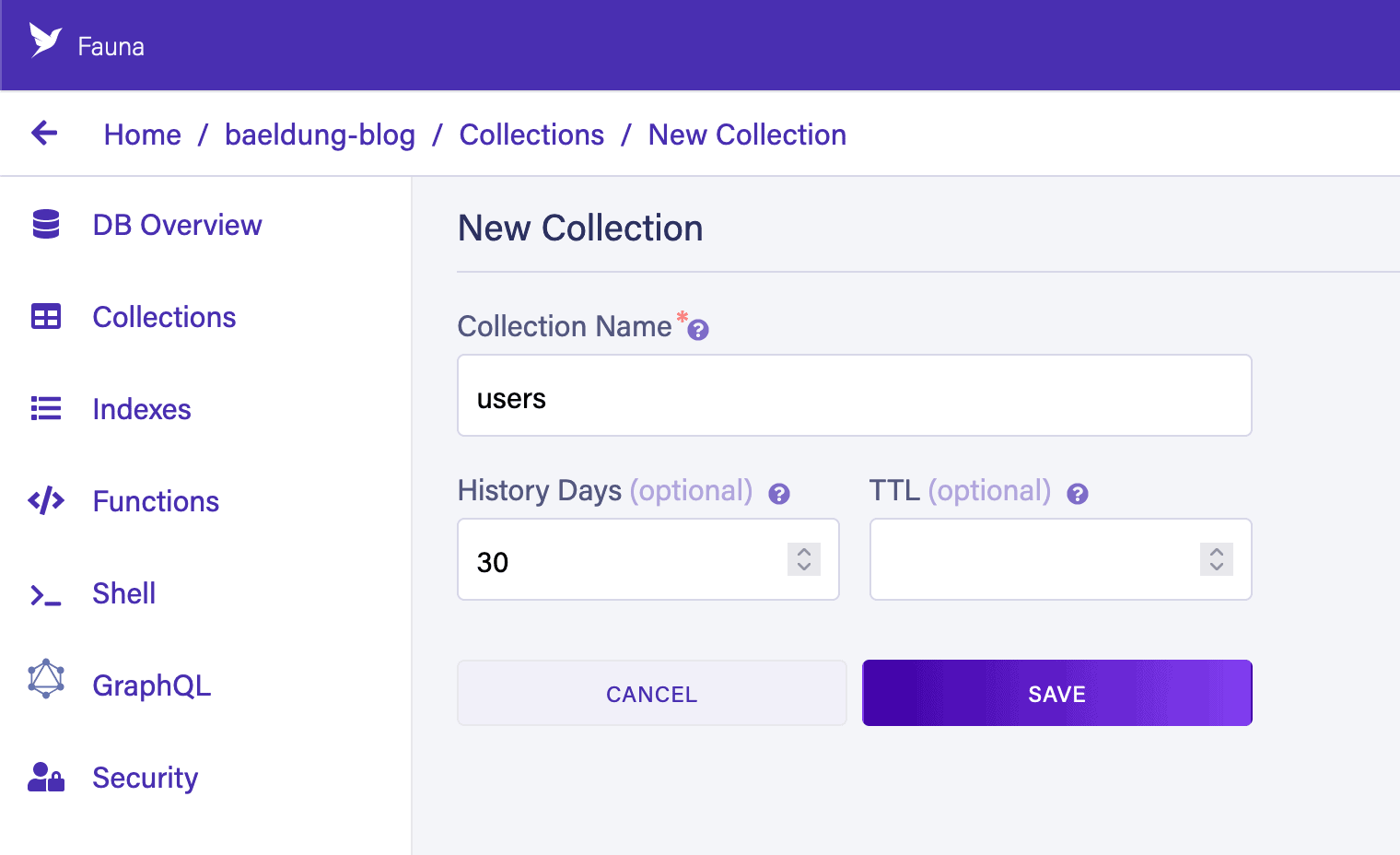
3.1. 创建用户集合
在Fauna控制台创建users集合:
- 进入"Collections"页面
- 点击"New Collection"
- 命名为
users(使用默认配置)
添加测试用户数据:
{
"username": "baeldung",
"password": "Pa55word",
"name": "Baeldung"
}
安全警告:示例中使用明文密码仅用于演示,生产环境必须加密存储!
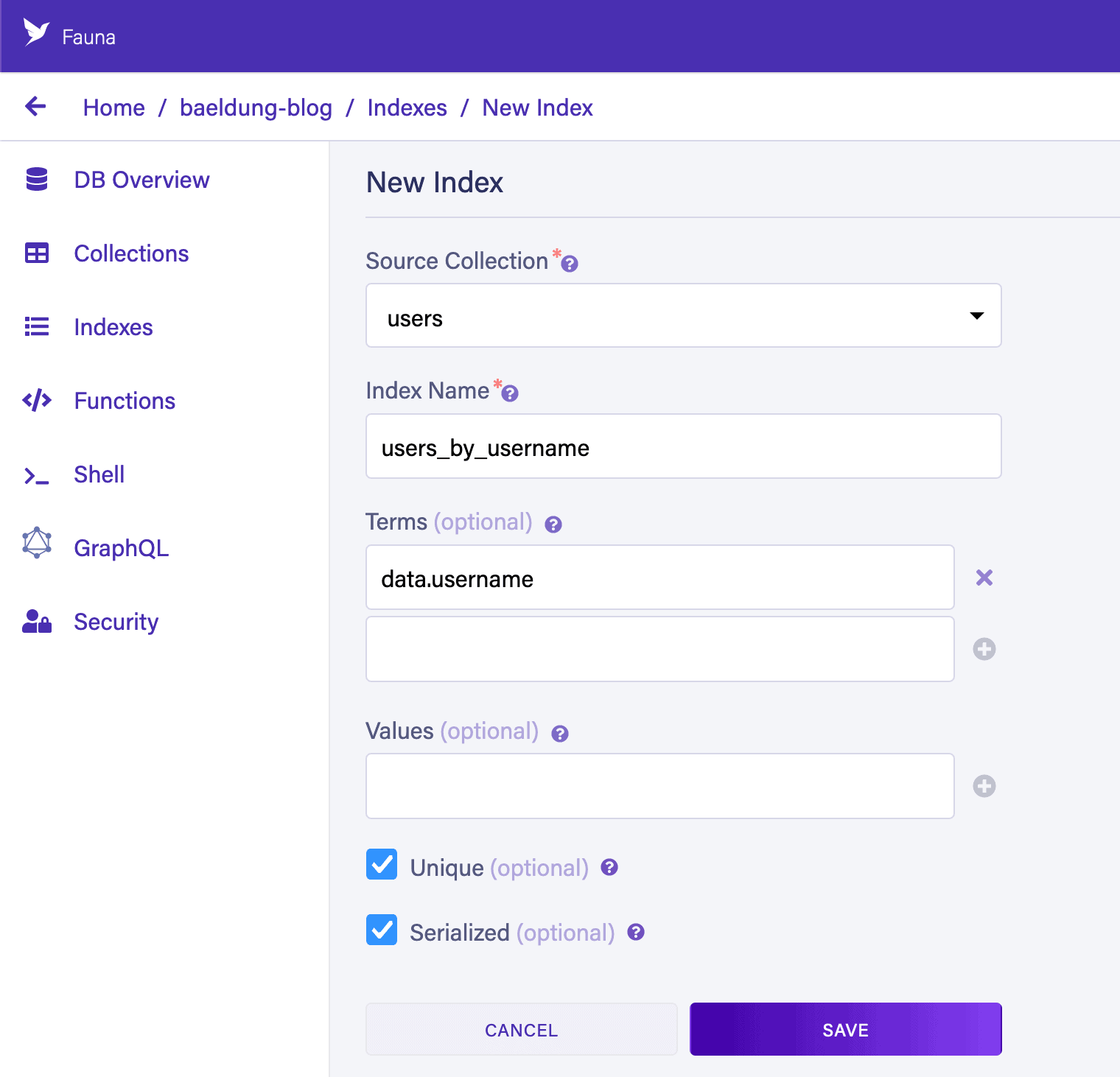
创建用户名索引users_by_username:
- 选择
users集合 - 在Terms字段添加
data.username
测试索引查询:
Map(
Paginate(Match(Index("users_by_username"), "baeldung")),
Lambda("user", Get(Var("user")))
)
3.2. 基于Fauna的认证
实现自定义UserDetailsService:
public class FaunaUserDetailsService implements UserDetailsService {
private final FaunaClient faunaClient;
// 构造器注入
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
try {
Value user = faunaClient.query(Map(
Paginate(Match(Index("users_by_username"), Value(username))),
Lambda(Value("user"), Get(Var("user")))))
.get();
Value userData = user.at("data").at(0).orNull();
if (userData == null) {
throw new UsernameNotFoundException("User not found");
}
return User.withDefaultPasswordEncoder()
.username(userData.at("data", "username").to(String.class).orNull())
.password(userData.at("data", "password").to(String.class).orNull())
.roles("USER")
.build();
} catch (ExecutionException | InterruptedException e) {
throw new RuntimeException(e);
}
}
}
配置Spring Security:
@Configuration
@EnableWebSecurity
@EnableGlobalMethodSecurity(prePostEnabled = true)
public class WebSecurityConfiguration {
@Autowired
private FaunaClient faunaClient;
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception {
http.csrf()
.disable();
http.authorizeRequests()
.antMatchers("/**")
.permitAll()
.and()
.httpBasic();
return http.build();
}
@Bean
public UserDetailsService userDetailsService() {
return new FaunaUserDetailsService(faunaClient);
}
}
现在可通过@PreAuthorize注解控制接口权限。
4. 博客文章功能
4.1. 创建文章集合
创建posts集合,包含字段:
title:文章标题content:正文内容created:创建时间authorRef:作者用户引用
创建两个索引:
posts_by_author:按作者查询- Terms:
data.authorRef
- Terms:
posts_sort_by_created_desc:按创建时间倒序- 需通过FQL创建(Web UI不支持):
CreateIndex({ name: "posts_sort_by_created_desc", source: Collection("posts"), terms: [ { field: ["ref"] } ], values: [ { field: ["data", "created"], reverse: true }, { field: ["ref"] } ] })
- 需通过FQL创建(Web UI不支持):
添加测试数据:
Create(
Collection("posts"),
{
data: {
title: "My First Post",
contents: "This is my first post",
created: Now(),
authorRef: Select("ref", Get(Match(Index("users_by_username"), "baeldung")))
}
}
)
4.2. 文章服务层
定义数据模型:
public record Author(String username, String name) {}
public record Post(String id, String title, String content, Author author, Instant created, Long version) {}
创建服务类:
@Component
public class PostsService {
@Autowired
private FaunaClient faunaClient;
}
4.3. 获取所有文章
实现分页查询(默认返回前64条):
List<Post> getAllPosts() throws Exception {
var postsResult = faunaClient.query(Map(
Paginate(
Join(
Documents(Collection("posts")),
Index("posts_sort_by_created_desc")
)
),
Lambda(
Arr(Value("extra"), Value("ref")),
Obj(
"post", Get(Var("ref")),
"author", Get(Select(Arr(Value("data"), Value("authorRef")), Get(Var("ref"))))
)
)
)).get();
var posts = postsResult.at("data").asCollectionOf(Value.class).get();
return posts.stream().map(this::parsePost).collect(Collectors.toList());
}
数据解析方法:
private Post parsePost(Value entry) {
var author = entry.at("author");
var post = entry.at("post");
return new Post(
post.at("ref").to(Value.RefV.class).get().getId(),
post.at("data", "title").to(String.class).get(),
post.at("data", "contents").to(String.class).get(),
new Author(
author.at("data", "username").to(String.class).get(),
author.at("data", "name").to(String.class).get()
),
post.at("data", "created").to(Instant.class).get(),
post.at("ts").to(Long.class).get() // 微秒级版本号
);
}
4.4. 获取作者文章
按用户名查询文章:
List<Post> getAuthorPosts(String author) throws Exception {
var postsResult = faunaClient.query(Map(
Paginate(
Join(
Match(Index("posts_by_author"), Select(Value("ref"), Get(Match(Index("users_by_username"), Value(author))))),
Index("posts_sort_by_created_desc")
)
),
Lambda(
Arr(Value("extra"), Value("ref")),
Obj(
"post", Get(Var("ref")),
"author", Get(Select(Arr(Value("data"), Value("authorRef")), Get(Var("ref"))))
)
)
)).get();
var posts = postsResult.at("data").asCollectionOf(Value.class).get();
return posts.stream().map(this::parsePost).collect(Collectors.toList());
}
4.5. 文章控制器
实现REST接口:
@RestController
@RequestMapping("/posts")
public class PostsController {
@Autowired
private PostsService postsService;
@GetMapping
public List<Post> listPosts(@RequestParam(value = "author", required = false) String author)
throws Exception {
return author == null
? postsService.getAllPosts()
: postsService.getAuthorPosts(author);
}
}
访问示例:
GET /posts:获取所有文章GET /posts?author=baeldung:获取指定作者文章
响应示例:
[
{
"author": {
"name": "Baeldung",
"username": "baeldung"
},
"content": "Introduction to FaunaDB with Spring",
"created": "2022-01-25T07:36:24.563534Z",
"id": "321742264960286786",
"title": "Introduction to FaunaDB with Spring",
"version": 1643096184600000
}
]
5. 文章创建与更新
5.1. 创建文章
服务层实现:
public void createPost(String author, String title, String contents) throws Exception {
faunaClient.query(
Create(Collection("posts"),
Obj(
"data", Obj(
"title", Value(title),
"contents", Value(contents),
"created", Now(),
"authorRef", Select(Value("ref"), Get(Match(Index("users_by_username"), Value(author))))
)
)
)
).get();
}
控制器实现:
@PostMapping
@ResponseStatus(HttpStatus.NO_CONTENT)
@PreAuthorize("isAuthenticated()")
public void createPost(@RequestBody UpdatedPost post) throws Exception {
String name = SecurityContextHolder.getContext().getAuthentication().getName();
postsService.createPost(name, post.title(), post.content());
}
请求体模型:
public record UpdatedPost(String title, String content) {}
5.2. 更新文章
服务层实现:
public void updatePost(String id, String title, String contents) throws Exception {
faunaClient.query(
Update(Ref(Collection("posts"), id),
Obj(
"data", Obj(
"title", Value(title),
"contents", Value(contents)
)
)
)
).get();
}
控制器实现:
@PutMapping("/{id}")
@ResponseStatus(HttpStatus.NO_CONTENT)
@PreAuthorize("isAuthenticated()")
public void updatePost(@PathVariable("id") String id, @RequestBody UpdatedPost post)
throws Exception {
postsService.updatePost(id, post.title(), post.content());
}
异常处理:
@ExceptionHandler(NotFoundException.class)
@ResponseStatus(HttpStatus.NOT_FOUND)
public void postNotFound() {}
6. 文章版本历史
利用Fauna的时间旅行功能获取历史版本:
Post getPost(String id, Long before) throws Exception {
var query = Get(Ref(Collection("posts"), id));
if (before != null) {
query = At(Value(before - 1), query); // 获取指定版本前1微秒的数据
}
var postResult = faunaClient.query(
Let(
"post", query
).in(
Obj(
"post", Var("post"),
"author", Get(Select(Arr(Value("data"), Value("authorRef")), Var("post")))
)
)
).get();
return parsePost(postResult);
}
控制器实现:
@GetMapping("/{id}")
public Post getPost(@PathVariable("id") String id, @RequestParam(value = "before", required = false) Long before)
throws Exception {
return postsService.getPost(id, before);
}
使用示例:
GET /posts/321742144715882562:获取最新版本GET /posts/321742144715882562?before=1643183487660000:获取指定版本的前一版本
7. 总结
本文展示了如何使用Spring和Java构建基于Fauna的博客服务后端,重点实现了:
- 用户认证体系
- 文章CRUD操作
- 版本历史查询
Fauna还提供了更多高级特性(如事务、流处理),建议在后续项目中深入探索。完整代码可在GitHub获取。