1. 概述
本文将介绍 Apache Fury——一个由 Apache 软件基金会孵化的项目。这个库承诺提供极速性能、强大能力和多语言支持。
我们将探讨该项目的基本特性,并将其性能与其他框架进行对比。
2. 使用 Apache Fury 进行序列化
序列化 是软件开发中的关键过程,它实现了系统间的高效数据交换。它允许应用程序通过共享状态进行通信。
Apache Fury 是一个旨在解决现有库和框架局限性的序列化库。它提供高性能、易用的跨语言序列化和反序列化能力,专为高效处理复杂数据结构和大数据量而设计。Apache Fury 的核心特性包括:
- 高性能:针对速度进行优化,确保序列化和反序列化过程的开销最小化
- 跨语言支持:支持多种编程语言(Java/Python/C++/Golang/JavaScript/Rust/Scala/TypeScript),适应不同开发环境
- 复杂数据结构:轻松处理复杂数据模型
- 紧凑序列化:生成紧凑的序列化数据,降低存储和传输成本
- GraalVM 原生镜像 支持:为 GraalVM 原生镜像提供 AOT 编译序列化,无需反射/序列化 JSON 配置
3. 代码示例
首先,我们需要在项目中添加必要的依赖:
<dependency>
<groupId>org.apache.fury</groupId>
<artifactId>fury-core</artifactId>
<version>0.5.0</version>
</dependency>
为了初次尝试 Fury,我们创建一个包含多种数据类型和至少一个嵌套对象的简单结构,模拟实际应用中的常见场景。为此,我们需要创建一个 UserEvent 类表示用户事件状态,后续将对其进行序列化:
public class UserEvent implements Serializable {
private final String userId;
private final String eventType;
private final long timestamp;
private final Address address;
// 构造方法和 getter
}
为增加事件对象的复杂性,我们使用名为 Address 的 Java POJO 定义地址的嵌套结构:
public class Address implements Serializable {
private final String street;
private final String city;
private final String zipCode;
// 构造方法和 getter
}
重要提示:Fury 不要求类实现 Serializable 接口。但后续我们将使用 Java 原生序列化器,它确实需要这个接口。接下来,我们需要初始化 Fury 上下文。
3.1. Fury 配置
现在我们来看看如何配置 Fury 以便开始使用:
class FurySerializationUnitTest {
@Test
void whenUsingFurySerialization_thenGenerateByteOutput() {
Fury fury = Fury.builder()
.withLanguage(Language.JAVA)
.withAsyncCompilation(true)
.build();
fury.register(UserEvent.class);
fury.register(Address.class);
// ...
}
**在这个代码片段中,我们创建了 Fury 对象并定义 Java 为使用协议,因为这对当前场景是最优的。但如前所述,Fury 支持跨语言序列化(例如使用 Language.XLANG)**。此外,我们将 withAsyncCompilation 选项设为 true,这允许在后台使用 JIT(即时编译器)编译序列化器,使应用程序可以继续处理其他任务而无需等待编译完成。它使用非阻塞编译实现此优化。
Fury 配置完成后,我们需要注册可能被序列化的类。这很重要,因为 Fury 可以使用预生成的模式或元数据来简化序列化和反序列化过程。这消除了运行时反射的需求,而反射通常缓慢且消耗资源。
注册类还能减少序列化和反序列化过程中动态确定类结构带来的开销,从而加快处理速度。最后,从安全角度看,这也很重要——我们创建了一个允许序列化和反序列化的类白名单。
Fury 的注册机制可以防止意外或恶意序列化未预期的类,从而避免反序列化攻击等安全漏洞。它还降低了利用序列化机制或类本身漏洞的风险。反序列化任意或未预期的类可能导致代码执行漏洞。
3.2. 使用 Fury
现在 Fury 已配置完成,我们可以使用这个对象执行多次序列化和反序列化操作。它提供了多种 API,提供对序列化过程细节的低级和高级访问,但在我们的场景中,只需调用以下方法:
@Test
void whenUsingFurySerialization_thenGenerateByteOutput() {
//... 配置代码
byte[] serializedData = fury.serialize(event);
UserEvent temp = (UserEvent) fury.deserialize(serializedData);
//...
}
我们只需使用这两个基本操作就能发挥库的巨大潜力。但如何将其与 Java 中其他知名序列化框架进行比较呢?接下来我们将运行一些实验进行对比。
4. Apache Fury 对比分析
首先需要说明,本文不打算对 Apache Fury 和其他框架进行全面的基准测试。尽管如此,为了说明该项目追求的性能水平,让我们看看不同库和框架在我们的示例用例中的表现。我们选择了 Java 原生序列化、Avro 序列化 和 Protocol Buffers 进行对比。
为比较各框架,我们的测试测量了它们序列化和反序列化 10 万个事件所需的时间:
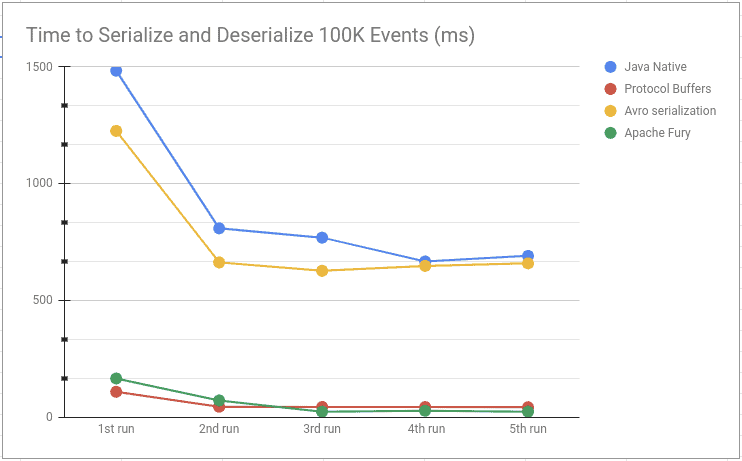
如图所示,Fury 和 Protobuf 在我们的实验中表现异常出色。初期 Protobuf 优于 Fury,但后期 Fury 表现更好,这很可能归因于 JIT 编译器的特性。不过两者都表现出色,正如我们观察到的。最后,我们来看看这些框架生成的输出大小: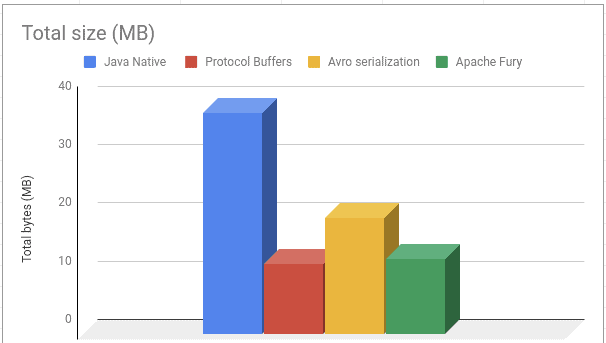
在序列化过程的输出方面,Protobuf 似乎略有优势,生成的输出更小。但 Fury 与它的差距很小,因此可以说它们的性能相当。
再次强调,这可能不适用于所有场景。这不是全面的基准测试,而是基于我们用例的对比。尽管如此,Apache Fury 提供了卓越的性能和易用的能力,这正是该项目的目标。
5. 总结
本教程介绍了 Fury——一个提供极速、跨语言、由 JIT(即时编译)和零拷贝技术驱动的序列化库。我们还看到了它与 Java 生态系统中其他知名序列化框架的性能对比。
无论哪个库/框架更快/更高效,Fury 处理复杂数据结构和提供跨语言支持的能力,使其成为需要高速数据处理的现代应用的绝佳选择。通过集成 Apache Fury,开发者可以确保应用程序以最小开销执行序列化和反序列化任务,从而提升整体效率和性能。
如常,本文中使用的所有代码示例可在 GitHub 上获取。