概述
本文将探讨如何使用Apache POI和iText库在Java中将Excel文件转换为PDF。Apache POI负责Excel文件的解析和数据提取,而iText则处理PDF文档的创建和格式化。通过利用它们的优势,我们可以高效地将Excel数据转换为PDF,同时保留原始格式和样式。
1. 引言
在本文中,我们将介绍如何在Java中使用Apache POI(处理Microsoft Excel)和iText(创建PDF文档)库将Excel文件转换为PDF。Apache POI负责Excel文件的读取和数据提取,而iText则负责PDF文档的生成和格式设置。通过结合这两个库的功能,我们可以有效地将Excel数据转换为PDF,并保持其原有的格式和样式。
2. 添加依赖项
在开始实现之前,我们需要在项目中添加Apache POI和iText库。在pom.xml文件中,添加以下依赖:
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
</dependency>
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
</dependency>
可以从Maven中央仓库下载最新版本的Apache POI和iText库。
3. 加载Excel文件
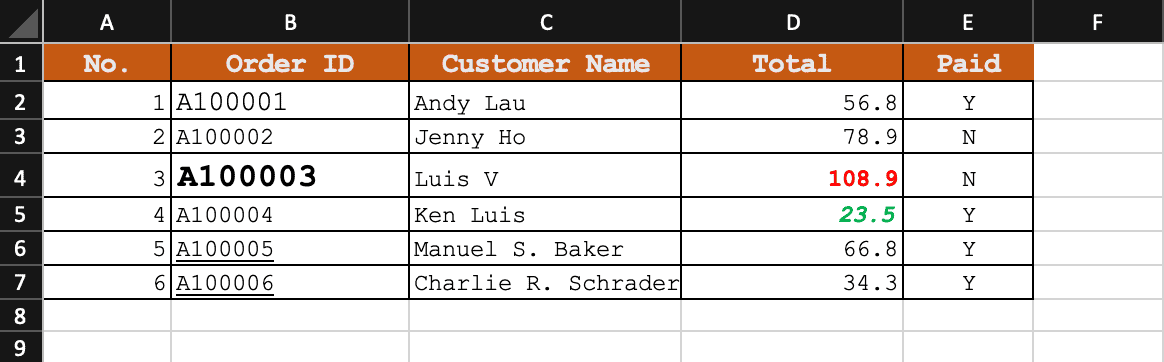
有了这些库,我们可以使用Apache POI加载目标Excel文件。首先,我们会通过FileInputStream打开Excel文件,并创建一个表示已加载工作簿的XSSFWorkbook对象:
FileInputStream inputStream = new FileInputStream(excelFilePath);
XSSFWorkbook workbook = new XSSFWorkbook(inputStream);
我们将使用这个对象访问单个工作表及其数据。
4. 创建PDF文档
接下来,我们将使用iText创建一个新的PDF文档:
Document document = new Document();
PdfWriter.getInstance(document, new FileOutputStream(pdfFilePath));
document.open();
这会创建一个Document对象,并与一个负责写入PDF内容的PDFWriter实例关联。最后,我们通过FileOutputStream指定PDF输出的位置。
5. 解析Excel数据
文档准备好后,我们将遍历工作表中的每一行以提取单元格值:
void addTableData(PdfPTable table) throws DocumentException, IOException {
XSSFSheet worksheet = workbook.getSheetAt(0);
Iterator<Row> rowIterator = worksheet.iterator();
while (rowIterator.hasNext()) {
Row row = rowIterator.next();
if (row.getRowNum() == 0) {
continue;
}
for (int i = 0; i < row.getPhysicalNumberOfCells(); i++) {
Cell cell = row.getCell(i);
String cellValue;
switch (cell.getCellType()) {
case STRING:
cellValue = cell.getStringCellValue();
break;
case NUMERIC:
cellValue = String.valueOf(BigDecimal.valueOf(cell.getNumericCellValue()));
break;
case BLANK:
default:
cellValue = "";
break;
}
PdfPCell cellPdf = new PdfPCell(new Phrase(cellValue));
table.addCell(cellPdf);
}
}
}
代码首先创建一个与工作表第一行列数匹配的PdfTable对象。然后,遍历工作表中的每一行,提取单元格值并将其融入到PDF表格中。请注意,当前不支持Excel公式,它们将返回空字符串。
对于每个提取的单元格值,我们使用包含提取数据的Phrase创建一个新的PdfPCell对象。Phrase是iText表示格式化文本字符串的元素。
6. 保留Excel样式
使用Apache POI和iText的一个关键优势是能够保留原始Excel文件的格式和样式。 这包括字体样式、颜色和对齐方式。
通过从Apache POI获取每个单元格关联的CellStyle对象的相关样式信息,我们可以将其应用到PDF文档中对应的元素上。然而,需要注意的是,尽管这种方法保留了格式和样式,但PDF的最终外观可能与直接从Excel导出或通过打印机驱动打印的PDF略有不同。对于更复杂的格式需求,可能需要进行额外调整。
6.1. 字体样式
我们将创建一个名为getCellStyle(Cell cell)的方法,用于从每个单元格关联的CellStyle对象中提取字体样式等信息:
Font getCellStyle(Cell cell) throws DocumentException, IOException {
Font font = new Font();
CellStyle cellStyle = cell.getCellStyle();
org.apache.poi.ss.usermodel.Font cellFont = cell.getSheet()
.getWorkbook()
.getFontAt(cellStyle.getFontIndexAsInt());
if (cellFont.getItalic()) {
font.setStyle(Font.ITALIC);
}
if (cellFont.getStrikeout()) {
font.setStyle(Font.STRIKETHRU);
}
if (cellFont.getUnderline() == 1) {
font.setStyle(Font.UNDERLINE);
}
short fontSize = cellFont.getFontHeightInPoints();
font.setSize(fontSize);
if (cellFont.getBold()) {
font.setStyle(Font.BOLD);
}
String fontName = cellFont.getFontName();
if (FontFactory.isRegistered(fontName)) {
font.setFamily(fontName);
} else {
logger.warn("Unsupported font type: {}", fontName);
font.setFamily("Helvetica");
}
return font;
}
Phrase构造函数接受一个值和一个Front对象作为参数,允许我们在PDF单元格中控制内容和格式。
6.2. 背景颜色样式
除了保留字体样式外,我们还需要确保Excel文件中单元格的背景颜色在生成的PDF中准确反映。为此,我们将创建一个名为setBackgroundColor()的新方法,从Excel单元格中提取背景颜色信息,并将其应用到相应的PDF单元格。
void setBackgroundColor(Cell cell, PdfPCell cellPdf) {
short bgColorIndex = cell.getCellStyle()
.getFillForegroundColor();
if (bgColorIndex != IndexedColors.AUTOMATIC.getIndex()) {
XSSFColor bgColor = (XSSFColor) cell.getCellStyle()
.getFillForegroundColorColor();
if (bgColor != null) {
byte[] rgb = bgColor.getRGB();
if (rgb != null && rgb.length == 3) {
cellPdf.setBackgroundColor(new BaseColor(rgb[0] & 0xFF, rgb[1] & 0xFF, rgb[2] & 0xFF));
}
}
}
}
6.3. 对齐方式样式
Apache POI的CellStyle对象提供了getAlignment()方法,返回一个表示对齐方式的常量值。一旦我们获得了对应iText对齐方式的常量,就可以使用setHorizontalAlignment()方法将其设置在PdfPCell对象上。
以下是如何整合对齐方式提取和应用的示例:
void setCellAlignment(Cell cell, PdfPCell cellPdf) {
CellStyle cellStyle = cell.getCellStyle();
HorizontalAlignment horizontalAlignment = cellStyle.getAlignment();
switch (horizontalAlignment) {
case LEFT:
cellPdf.setHorizontalAlignment(Element.ALIGN_LEFT);
break;
case CENTER:
cellPdf.setHorizontalAlignment(Element.ALIGN_CENTER);
break;
case JUSTIFY:
case FILL:
cellPdf.setVerticalAlignment(Element.ALIGN_JUSTIFIED);
break;
case RIGHT:
cellPdf.setHorizontalAlignment(Element.ALIGN_RIGHT);
break;
}
}
现在,让我们更新遍历单元格的现有代码,包括字体和背景颜色样式:
PdfPCell cellPdf = new PdfPCell(new Phrase(cellValue, getCellStyle(cell)));
setBackgroundColor(cell, cellPdf);
setCellAlignment(cell, cellPdf);
请注意,生成的Excel将不会看起来与直接从Excel导出或通过打印机驱动打印的PDF完全相同。
7. 保存PDF文档
最后,我们可以将生成的PDF文档保存到所需的目录。这涉及关闭PDF文档对象并确保所有资源正确释放:
document.add(table);
document.close();
workbook.close();
8. 总结
我们已经学会了如何在Java中使用Apache POI和iText将Excel文件转换为PDF。通过结合Apache POI处理Excel和iText生成PDF的能力,我们可以无缝地将Excel数据转换为PDF,并保持其原始格式和样式。
本文中的代码示例可以在基于Maven的项目GitHub中找到。