1. 概述
本教程将深入探讨 Cassandra 的批处理查询及其不同应用场景。我们将分析单分区和多分区表的批处理操作,并在 Cqlsh 和 Java 应用中实践。
2. Cassandra 批处理基础
与关系型数据库不同,Cassandra 这类分布式数据库不支持 ACID(原子性、一致性、隔离性、持久性)特性。但在某些场景下,我们仍需要多个数据修改操作具备原子性或隔离性。
批处理语句通过组合多个数据修改语言语句(如 INSERT、UPDATE 和 DELETE),在操作单分区时实现原子性和隔离性,在操作多分区时仅保证原子性。
批处理查询的语法如下:
BEGIN [ ( UNLOGGED | COUNTER ) ] BATCH
[ USING TIMESTAMP [ epoch_microseconds ] ]
dml_statement [ USING TIMESTAMP [ epoch_microseconds ] ] ;
[ dml_statement [ USING TIMESTAMP [ epoch_microseconds ] ] [ ; ... ] ]
APPLY BATCH;
通过示例解析上述语法:
BEGIN BATCH
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f3,'banana');
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f5,'banana');
APPLY BATCH;
首先使用 BEGIN BATCH 启动批处理(未使用可选参数如 UNLOGGED 或 USING TIMESTAMP),然后包含所有 DML 操作(即 product 表的插入语句)。最后通过 APPLY BATCH 执行批处理。
注意:批处理查询不支持回滚功能,执行后无法撤销。
2.1. 单分区操作
批处理语句在单分区内执行所有 DML 操作,确保原子性和隔离性。
设计良好的单分区批处理可减少客户端-服务器通信,通过单次行变更高效更新表。这是因为仅当批处理操作写入单分区时才会发生隔离。
单分区批处理也可涉及同一键空间中具有相同分区键的两个不同表。
单分区批处理默认为 UNLOGGED 模式,不会因日志记录产生性能损耗。
下图展示了协调节点 H 到分区节点 B 及其复制节点 C、D 的单分区批处理请求流程:
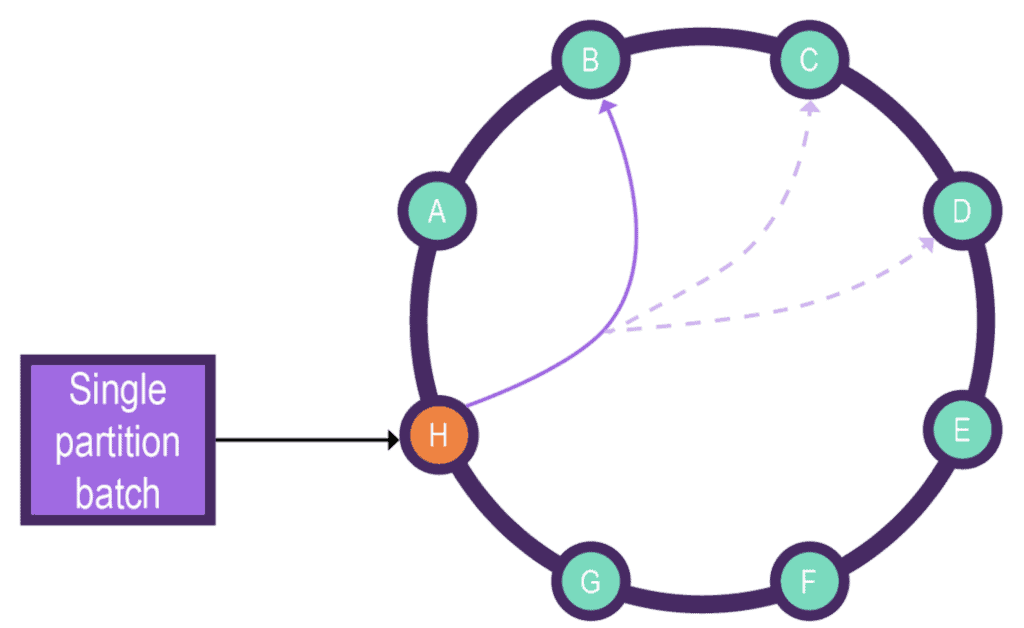
图片来源:Datastax
2.2. 多分区操作
多分区批处理需要精心设计,涉及多个节点间的协调。其最佳应用场景是将相同数据写入两个相关表(即具有不同分区键但列结构相同的表)。
多分区批处理使用 batchlog 机制确保原子性:协调节点向批处理日志节点发送日志请求,收到确认后执行批处理语句,然后删除节点上的 batchlog 并向客户端发送确认。
强烈建议避免使用多分区批处理——这类查询会给协调节点带来巨大压力,严重影响性能。
仅当没有其他可行方案时才使用多分区批处理。
下图展示了协调节点 H 到分区节点 B、E 及其复制节点 C、D、F、G 的多分区批处理请求流程:
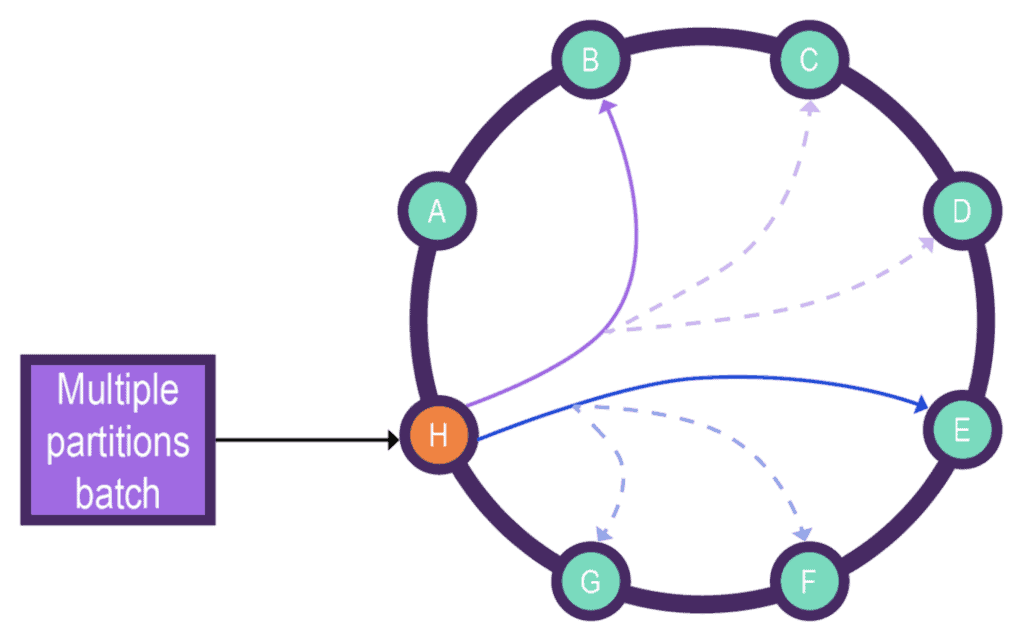
图片来源:Datastax
3. 在 Cqlsh 中执行批处理
首先创建 product 表用于演示:
CREATE TABLE product (
product_id UUID,
variant_id UUID,
product_name text,
description text,
price float,
PRIMARY KEY (product_id, variant_id)
);
3.1. 无时间戳的单分区批处理
执行针对 product 表单分区的批处理查询(不提供时间戳):
BEGIN BATCH
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f3,'banana') IF NOT EXISTS;
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f5,'banana') IF NOT EXISTS;
UPDATE product SET price = 7.12, description = 'banana v1'
WHERE product_id = 2c11bbcd-4587-4d15-bb57-4b23a546bd7f AND variant_id=0e9ef8f7-d32b-4926-9d37-27225933a5f3;
UPDATE product SET price = 11.90, description = 'banana v2'
WHERE product_id = 2c11bbcd-4587-4d15-bb57-4b23a546bd7f AND variant_id=0e9ef8f7-d32b-4926-9d37-27225933a5f5;
APPLY BATCH;
上述查询使用了 CAS(Compare-And-Set)逻辑(即 IF NOT EXISTS 子句),所有条件语句必须返回 true 才能执行批处理。若有任何语句返回 false,整个批处理将不会执行。
执行后返回成功确认:

验证批处理后数据的写入时间是否一致:
cqlsh:testkeyspace> select product_id, variant_id, product_name, description, price, writetime(product_name) from product;
@ Row 1
-------------------------+--------------------------------------
product_id | 3a043b68-20ee-4ece-8f4b-a07e704bc9f5
variant_id | b84b9366-9998-4b2d-9a96-7e9a59a94ae5
product_name | Banana
description | banana v1
price | 12
writetime(product_name) | 1639275574653000
@ Row 2
-------------------------+--------------------------------------
product_id | 3a043b68-20ee-4ece-8f4b-a07e704bc9f5
variant_id | facc3997-299d-419b-b133-a54b5d4dfc3b
product_name | Banana
description | banana v2
price | 12
writetime(product_name) | 1639275574653000
3.2. 带时间戳的单分区批处理
使用 USING TIMESTAMP 选项指定 epoch 时间格式(微秒)的时间戳:
BEGIN BATCH USING TIMESTAMP 1638810270
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f3,'banana');
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f5,'banana');
UPDATE product SET price = 7.12, description = 'banana v1'
WHERE product_id = 2c11bbcd-4587-4d15-bb57-4b23a546bd7f AND variant_id=0e9ef8f7-d32b-4926-9d37-27225933a5f3;
UPDATE product SET price = 11.90, description = 'banana v2'
WHERE product_id = 2c11bbcd-4587-4d15-bb57-4b23a546bd7f AND variant_id=0e9ef8f7-d32b-4926-9d37-27225933a5f5;
APPLY BATCH;
为单独的 DML 语句指定自定义时间戳:
BEGIN BATCH
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f3,'banana');
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f5,'banana') USING TIMESTAMP 1638810270;
UPDATE product SET price = 7.12, description = 'banana v1'
WHERE product_id = 2c11bbcd-4587-4d15-bb57-4b23a546bd7f AND variant_id=0e9ef8f7-d32b-4926-9d37-27225933a5f3 USING TIMESTAMP 1638810270;
UPDATE product SET price = 11.90, description = 'banana v2'
WHERE product_id = 2c11bbcd-4587-4d15-bb57-4b23a546bd7f AND variant_id=0e9ef8f7-d32b-4926-9d37-27225933a5f5;
APPLY BATCH;
踩坑案例:同时使用自定义时间戳和 CAS 逻辑(IF NOT EXISTS 子句)的无效批处理:
BEGIN BATCH USING TIMESTAMP 1638810270
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f3,'banana') IF NOT EXISTS;
INSERT INTO product (product_id, variant_id, product_name)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,0e9ef8f7-d32b-4926-9d37-27225933a5f5,'banana') IF NOT EXISTS;
UPDATE product SET price = 7.12, description = 'banana v1'
WHERE product_id = 2c11bbcd-4587-4d15-bb57-4b23a546bd7f AND variant_id=0e9ef8f7-d32b-4926-9d37-27225933a5f3;
UPDATE product SET price = 11.90, description = 'banana v2'
WHERE product_id = 2c11bbcd-4587-4d15-bb57-4b23a546bd7f AND variant_id=0e9ef8f7-d32b-4926-9d37-27225933a5f5;
APPLY BATCH;
执行报错:
InvalidRequest: Error from server: code=2200 [Invalid query]
message="Cannot provide custom timestamp for conditional BATCH"
错误原因:条件插入/更新操作禁止使用客户端时间戳。
3.3. 多分区批处理查询
多分区批处理的最佳场景:将相同数据写入两个相关表。
将相同数据插入 product_by_name 和 product_by_id 表(分区键不同):
BEGIN BATCH
INSERT INTO product_by_name (product_name, product_id, description, price)
VALUES ('banana',2c11bbcd-4587-4d15-bb57-4b23a546bd7f,'banana',12.00);
INSERT INTO product_by_id (product_id, product_name, description, price)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,'banana','banana',12.00);
APPLY BATCH;
启用 UNLOGGED 选项:
BEGIN UNLOGGED BATCH
INSERT INTO product_by_name (product_name, product_id, description, price)
VALUES ('banana',2c11bbcd-4587-4d15-bb57-4b23a546bd7f,'banana',12.00);
INSERT INTO product_by_id (product_id, product_name, description, price)
VALUES (2c11bbcd-4587-4d15-bb57-4b23a546bd7f,'banana','banana',12.00);
APPLY BATCH;
上述 UNLOGGED 批处理不保证原子性或隔离性,且不使用 batchlog 写入数据。
3.4. 计数器更新的批处理
对计数器列必须使用 COUNTER 选项,因为计数器更新操作不具备幂等性。
创建存储 sales_vol 为 Counter 类型的 product_by_sales 表:
CREATE TABLE product_by_sales (
product_id UUID,
sales_vol counter,
PRIMARY KEY (product_id)
);
以下计数器批处理将 sales_vol 增加 100 两次:
BEGIN COUNTER BATCH
UPDATE product_by_sales
SET sales_vol = sales_vol + 100
WHERE product_id = 6ab09bec-e68e-48d9-a5f8-97e6fb4c9b47;
UPDATE product_by_sales
SET sales_vol = sales_vol + 100
WHERE product_id = 6ab09bec-e68e-48d9-a5f8-97e6fb4c9b47;
APPLY BATCH
4. Java 中的批处理操作
通过示例展示如何在 Java 应用中构建和执行批处理查询。
4.1. Maven 依赖
添加 DataStax 相关 Maven 依赖:
<dependency>
<groupId>com.datastax.oss</groupId>
<artifactId>java-driver-core</artifactId>
<version>4.1.0</version>
</dependency>
<dependency>
<groupId>com.datastax.oss</groupId>
<artifactId>java-driver-query-builder</artifactId>
<version>4.1.0</version>
</dependency>
4.2. 单分区批处理
执行单分区批处理示例:
使用 BatchStatement 实例构建批处理查询。通过 DefaultBatchType 枚举和 BoundStatement 实例化 BatchStatement。
创建方法将 Product 属性绑定到 PreparedStatement 插入查询:
BoundStatement getProductVariantInsertStatement(Product product, UUID productId) {
String insertQuery = new StringBuilder("")
.append("INSERT INTO ")
.append(PRODUCT_TABLE_NAME)
.append("(product_id, variant_id, product_name, description, price) ")
.append("VALUES (")
.append(":product_id")
.append(", ")
.append(":variant_id")
.append(", ")
.append(":product_name")
.append(", ")
.append(":description")
.append(", ")
.append(":price")
.append(");")
.toString();
PreparedStatement preparedStatement = session.prepare(insertQuery);
return preparedStatement.bind(
productId,
UUID.randomUUID(),
product.getProductName(),
product.getDescription(),
product.getPrice());
}
使用相同 Product UUID 执行 BatchStatement:
UUID productId = UUID.randomUUID();
BoundStatement productBoundStatement1 = this.getProductVariantInsertStatement(productVariant1, productId);
BoundStatement productBoundStatement2 = this.getProductVariantInsertStatement(productVariant2, productId);
BatchStatement batch = BatchStatement.newInstance(DefaultBatchType.UNLOGGED,
productBoundStatement1, productBoundStatement2);
session.execute(batch);
上述代码通过 UNLOGGED 批处理在同一分区键插入两个产品变体。
4.3. 多分区批处理
将相同数据插入两个相关表(product_by_id 和 product_by_name):
创建可复用方法获取 PreparedStatement 的 BoundStatement 实例:
BoundStatement getProductInsertStatement(Product product, UUID productId, String productTableName) {
String cqlQuery1 = new StringBuilder("")
.append("INSERT INTO ")
.append(productTableName)
.append("(product_id, product_name, description, price) ")
.append("VALUES (")
.append(":product_id")
.append(", ")
.append(":product_name")
.append(", ")
.append(":description")
.append(", ")
.append(":price")
.append(");")
.toString();
PreparedStatement preparedStatement = session.prepare(cqlQuery1);
return preparedStatement.bind(
productId,
product.getProductName(),
product.getDescription(),
product.getPrice());
}
使用相同 Product UUID 执行 BatchStatement:
UUID productId = UUID.randomUUID();
BoundStatement productBoundStatement1 = this.getProductInsertStatement(product, productId, PRODUCT_BY_ID_TABLE_NAME);
BoundStatement productBoundStatement2 = this.getProductInsertStatement(product, productId, PRODUCT_BY_NAME_TABLE_NAME);
BatchStatement batch = BatchStatement.newInstance(DefaultBatchType.LOGGED,
productBoundStatement1,productBoundStatement2);
session.execute(batch);
通过 LOGGED 批处理将相同产品数据插入 product_by_id 和 product_by_name 表。
5. 总结
本文深入解析了 Cassandra 批处理查询,并展示了在 Cqlsh 和 Java 中通过 BatchStatement 实现批处理操作。
完整示例代码见 GitHub 仓库。