1. 概述
本教程将带你深入了解 Elasticsearch 及其配套工具。这个工具能轻松处理海量数据、自动扩展规模,并持续吸收新数据。
2. 定义
想象一下:我们堆积着成千上万份文档,需要快速高效地找到特定信息。这正是 Elasticsearch 的用武之地。
把它想象成一位超级智能的图书管理员,能娴熟地组织海量文档,让搜索过程变得异常轻松。 Elasticsearch 就是这样一款开源的搜索与分析引擎,擅长管理庞大数据量,精准返回我们所需的信息。
作为分布式系统且采用 NoSQL 架构,Elasticsearch 使用 JSON 文档存储数据,方便与各种编程语言和系统集成。
Elasticsearch 的数据处理能力尤为突出:即时存储、搜索和分析数据。它通过强大的搜索系统,将文档中的所有词汇整理成易于检索的索引,让我们能在海量数据中实现闪电般的查询速度。
2.1. 索引是什么?
Elasticsearch 的数据组织方式与传统关系型数据库(RDBMS)截然不同。在 RDBMS 中我们常说“数据库”,而 Elasticsearch 使用“索引”(indexes)——这更接近传统数据库中的“表”概念,只是术语不同。
此外,关系型数据库用表组织数据,Elasticsearch 则有类似的概念——索引模式(index patterns)。在旧版本中它们被称为类型(types)。
在数据库或索引内部,关系型数据库的表由行和列组成。在 Elasticsearch 中:
- 行 → 文档(documents)
- 列 → 字段(fields)
这与许多 NoSQL 数据源的结构如出一辙。对于熟悉 MySQL 或 Postgres 的开发者来说,理解这个面向文档的搜索引擎就像扩展现有知识。它帮助我们理清数据结构,就像将现有理解翻译到新系统中。
下表直观展示了差异:
3. 与 Elasticsearch 交互
有趣的是,与 Elasticsearch 的交互完全通过 RESTful API 实现。这意味着所有操作(管理索引或处理数据)都通过可编程访问的 URL 完成。
查询通常使用 Elasticsearch 的 Query DSL(领域特定语言)——一个灵活强大的 JSON 查询系统。它不仅支持简单匹配,还能处理布尔逻辑、通配符、范围查询等复杂操作。
Elasticsearch 的适用场景广泛:
- ✅ 收集日志、系统指标、应用追踪数据
- ✅ 将多源数据整合为 JSON 文档
- ✅ 实时搜索与检索信息
4. 解决现实世界中的挑战
4.1. 电商搜索
假设我们拥有大量产品评论文档。通过 Elasticsearch 可以:
- ⚡ 秒速检索评论中的关键词或短语
- 📊 按相关性对结果排序,优先展示重要信息
例如在大型商品目录中搜索“红色衬衫”:
curl -X GET "localhost:9200/products/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [
{ "match": { "color": "red" }},
{ "match": { "product_type": "shirt" }}
]
}
}
}'
4.2. 地理空间搜索
开发地图服务或位置应用时,常需:
- 🔍 搜索地点
- 📏 计算距离
- 📍 查找附近位置
Elasticsearch 原生支持地理空间数据,可轻松存储和查询位置信息。无论是找最近的咖啡店还是分析地理数据,其地理空间功能都让位置数据处理变得简单。
查找特定位置 1 公里内的咖啡店:
curl -X GET "localhost:9200/places/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": {
"match": {
"place_type": "coffee_shop"
}
},
"filter": {
"geo_distance": {
"distance": "1km",
"pin.location": {
"lat": 40.73,
"lon": -74.1
}
}
}
}
}
}'
4.3. 欺诈检测
信用卡欺诈、网络诈骗等行为对企业构成严重威胁。
Elasticsearch 通过分析海量交易数据辅助欺诈检测。它利用高级分析和机器学习算法识别模式、异常或可疑行为。
除搜索能力外,它还具备:
- 🚀 高扩展性和容错性
- 🔄 跨服务器分布式存储
- 💾 单点故障时数据仍可访问
这使其成为处理大规模应用或高数据量系统的可靠选择。
5. 生态系统
研究 Elasticsearch 时,你一定听过“Elastic Stack”(原 ELK Stack)。这个术语整合了三大开源工具:
- Elasticsearch
- Logstash
- Kibana
现在还包含 Beats(轻量级数据采集器)。它们共同提供完整的搜索、日志分析和数据可视化方案:
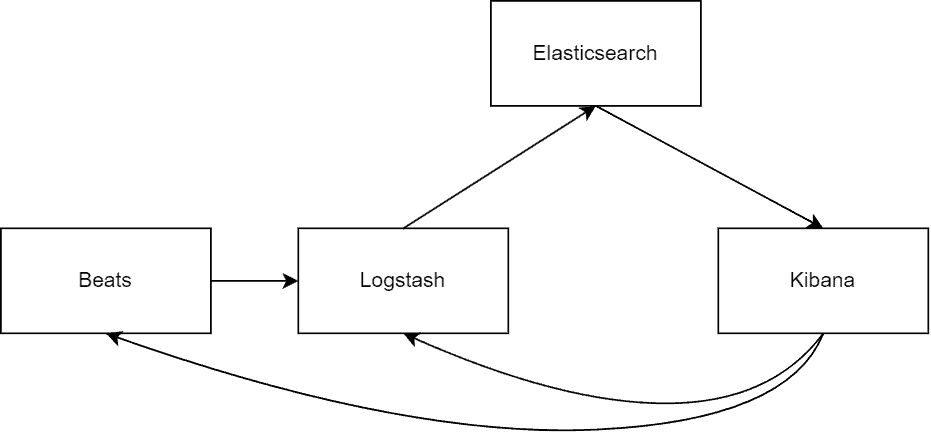
5.1. Kibana
把它想象成 Elasticsearch 的 Web 化操作面板。这是我们的数据指挥中心,可深入分析所有索引信息。
Kibana 的核心能力:
- 📈 创建实时更新的动态仪表盘
- 📊 生成图表和可视化
- 🔍 监控与探索流入数据
5.2. Logstash
Logstash 是开源的服务器端数据处理管道。核心职责三步走:
- 📥 接收数据
- 🔧 转换数据
- 📤 存储数据
配置要点:
- ✅ 支持多种数据源(SDK/系统集成)
- ✅ 处理 JSON/CSV 等格式
- ✅ 通过插件生态支持自定义格式
- ✅ 数据经转换后发送至 Elasticsearch 等目标
5.3. Beats
Beats 是轻量级数据采集器,可部署在不同服务器上收集特定类型数据:
- 🖥️ 服务器/容器监控
- 📄 文件日志采集
- 🪟 Windows 事件追踪
Beats 的杀手锏:能将数据直接发送给 Logstash 进行深度处理。它作为高效的数据收集器,与 Logstash 协同工作,确保数据无缝流入 Elasticsearch 环境。
6. 总结
本文探索了 Elasticsearch 这款强大的搜索与分析引擎,它将彻底改变我们处理和理解数据的方式。
你可以在 GitHub 项目 中找到更多实践用例。