1. Introduction
In this article, we’re going to explore the Failsafe library and see how it can be incorporated into our code to make it more resilient to failure cases.
2. What Is Fault Tolerance?
No matter how well we build our applications, there will always be ways in which things can go wrong. Often, these are outside our control — for example, calling a remote service that isn’t available. As such, we must build our applications to tolerate these failures and give our users the best experience.
We can react to these failures in many different ways, depending on precisely what we’re doing and what went wrong. For example, if we’re calling a remote service that we know has intermittent outages, we could try again and hope the call works. Or we could try calling a different service that provides the same functionality.
There are also ways to structure our code to avoid these situations. For example, limiting the number of concurrent calls to the same remote service will reduce its load.
3. Dependencies
Before we can use Failsafe, we need to include the latest version in our build, which is 3.3.2 at the time of writing.
If we’re using Maven, we can include it in pom.xml:
<dependency>
<groupId>dev.failsafe</groupId>
<artifactId>failsafe</artifactId>
<version>3.3.2</version>
</dependency>
Or if we’re using Gradle, we can include it in build.gradle:
implementation("dev.failsafe:failsafe:3.3.2")
At this point, we’re ready to start using it in our application.
4. Executing Actions With Failsafe
Failsafe works with the concept of policies. Each policy determines whether it considers the action a failure and how it will react to this.
4.1. Determining Failure
By default, a policy will consider an action a failure if it throws any Exception. However, we can configure the policy only to handle the exact set of exceptions that interest us, either by type or by providing a lambda that checks them:
policy
.handle(IOException.class)
.handleIf(e -> e instanceof IOException)
We can also configure them to treat particular results from our action as a failure, either as an exact value or by providing a lambda to check it for us:
policy
.handleResult(null)
.handleResultIf(result -> result < 0)
By default, policies always treat all exceptions as failures. If we add handling for exceptions, this will replace that behavior, but adding handling for particular results will be in addition to a policy’s exception handling. Further, all of our handle checks are additive – we can add as many as we want, and if any checks pass, the policy will consider the action failed.
4.2. Composing Policies
Once we’ve got our policies, we can build an executor from them. This is our means to execute functionality and get results out – either the actual result of our action or modified by our policies. We can either do this by passing all of our policies into Failsafe.with(), or we can extend this by using the compose() method:
Failsafe.with(defaultFallback, npeFallback, ioFallback)
.compose(timeout)
.compose(retry);
We can add as many policies as we need in whatever order. The policies are always executed in the order they’re added, each wrapping the next. So, the above will be:
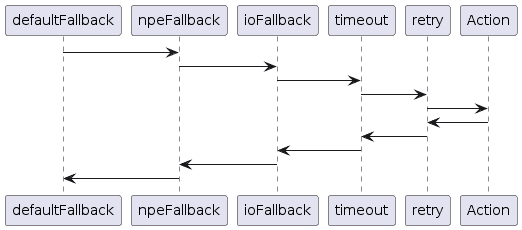
Each of these will react appropriately to the exception or return value from the policy or action that it’s wrapping. This allows us to act as we need to. For example, the above applies the timeout across all of the retries. We could instead swap that to apply the timeout to each attempted retry individually.
4.3. Executing Actions
Once we’ve composed our policies, Failsafe returns a FailsafeExecutor instance to us. This instance then has a set of methods that we can use to execute our actions, depending on precisely what we want to execute and how we want it returned.
The most straightforward ways of executing an action are T get
The difference between these is that get() will return the result of the action, whereas run() will return void – and the action must also return void:
Failsafe.with(policy).run(this::runSomething);
var result = Failsafe.with(policy).get(this::doSomething);
In addition, we have various methods that can run our actions asynchronously, returning a CompletableFuture for our result. However, these are outside the scope of this article.
5. Failsafe Policies
Now that we know how to build a FailsafeExecutor to execute our actions, we need to construct the policies to use it. Failsafe provides several standard policies. Each uses the builder pattern to make constructing them easier.
5.1. Fallback Policy
The most straightforward policy that we can use is a Fallback. This policy will allow us to provide a new result for cases when the chained action fails.
The easiest way to use this is to simply return a static value:
Fallback<Integer> policy = Fallback.builder(0).build();
In this case, our policy will return a fixed value of “0” if the action fails for any reason.
In addition, we can use a CheckedRunnable or CheckedSupplier to generate our alternative value. Depending on our needs, this could be as simple as writing out log messages before returning a fixed value or as complicated as running an entirely different execution path:
Fallback<Result> backupService = Fallback.of(this::callBackupService)
.build();
Result result = Failsafe.with(backupService)
.get(this::callPrimaryService);
In this case, we’ll execute callPrimaryService(). If this fails, we’ll automatically execute callBackupService() and attempt to get a result that way.
Finally, we can use Fallback.ofException() to throw a specific exception in the case of any failure. This allows us to collapse any of the configured failure reasons down to a single expected exception, which we can then handle as needed:
Fallback<Result> throwOnFailure = Fallback.ofException(e -> new OperationFailedException(e));
5.2. Retry Policies
The Fallback policy allows us to give an alternative result when our action fails. Instead of this, the Retry policy allows us to simply try the original action again.
With no configuration, this policy will call the action up to three times and either return the result of it on success or throw a FailsafeException if we never got a success:
RetryPolicy<Object> retryPolicy = RetryPolicy.builder().build();
This is already really useful since it means that if we have an occasionally faulty action, we can retry it a couple of times before giving up.
However, we can go further and configure this behavior. The first thing we can do is to adjust the number of times it will retry using the withMaxAttempts() call:
RetryPolicy<Object> retryPolicy = RetryPolicy.builder()
.withMaxAttempts(5)
.build();
This will now execute the action up to five times instead of the default.
We can also configure it to wait a fixed amount of time between each attempt. This can be useful in cases where a short-lived failure, such as a networking blip, doesn’t instantly fix itself:
RetryPolicy<Object> retryPolicy = RetryPolicy.builder()
.withDelay(Duration.ofMillis(250))
.build();
There are also more complex variations to this that we can use. For example, withBackoff() will allow us to configure an incrementing delay:
RetryPolicy<Object> retryPolicy = RetryPolicy.builder()
.withMaxAttempts(20)
.withBackoff(Duration.ofMillis(100), Duration.ofMillis(2000))
.build();
This will delay for 100 milliseconds after the first failure and 2,000 milliseconds after the 20th failure, gradually increasing the delay on intervening failures.
5.3. Timeout Policies
Where Fallback and Retry policies help us achieve a successful result from our actions, the Timeout policy does the opposite. We can use this to force a failure if the action we’re calling takes longer than we’d like. This can be invaluable if we need to fail when an action is taking too long.
When we construct our Timeout, we need to provide the target duration after which the action will fail:
Timeout<Object> timeout = Timeout.builder(Duration.ofMillis(100)).build();
By default, this will run the action to completion and then fail if it takes longer than the duration we provided.
Alternatively, we can configure it to interrupt the action when the timeout is reached instead of running to completeness. This is useful when we need to respond quickly rather than simply failing because it was too slow:
Timeout<Object> timeout = Timeout.builder(Duration.ofMillis(100))
.withInterrupt()
.build();
We can usefully compose Timeout policies with Retry policies as well. If we compose the timeout outside of the retry, then the timeout period spreads across all of the retries:
Timeout<Object> timeoutPolicy = Timeout.builder(Duration.ofSeconds(10))
.withInterrupt()
.build();
RetryPolicy<Object> retryPolicy = RetryPolicy.builder()
.withMaxAttempts(20)
.withBackoff(Duration.ofMillis(100), Duration.ofMillis(2000))
.build();
Failsafe.with(timeoutPolicy, retryPolicy).get(this::perform);
This will attempt our action up to 20 times, with an increasing delay between each attempt, but will give up if the entire attempt takes longer than 10 seconds to execute.
Conversely, we can compose the timeout inside of the retry so that each individual attempt will have a timeout configured:
Timeout<Object> timeoutPolicy = Timeout.builder(Duration.ofMillis(500))
.withInterrupt()
.build();
RetryPolicy<Object> retryPolicy = RetryPolicy.builder()
.withMaxAttempts(5)
.build();
Failsafe.with(retryPolicy, timeoutPolicy).get(this::perform);
This will attempt the action five times, and each attempt will be canceled if it takes longer than 500ms.
5.4. Bulkhead Policies
So far, all the policies we’ve seen have been about controlling how our application reacts to failures. However, there are also policies that we can use to reduce the chance of failures in the first place.
Bulkhead policies exist to restrict the number of concurrent times an action is being performed. This can reduce the load on external services and, therefore, help to reduce the chance that they’ll fail.
When we construct a Bulkhead, we need to configure the maximum number of concurrent executions that it supports:
Bulkhead<Object> bulkhead = Bulkhead.builder(10).build();
By default, this will immediately fail any actions when the bulkhead is already at capacity.
We can also configure the bulkhead to wait when new actions come in, and if capacity opens up, then it’ll execute the waiting task:
Bulkhead<Object> bulkhead = Bulkhead.builder(10)
.withMaxWaitTime(Duration.ofMillis(1000))
.build();
Tasks will be allowed through the bulkhead in the order they’re executed as soon as capacity becomes available. Any task that has to wait longer than this configured wait time will fail as soon as the wait time expires. However, other tasks behind them may then get to execute successfully.
5.5. Rate Limiter Policies
Similar to bulkheads, rate limiters help restrict the number of executions of an action that can happen. However, unlike bulkheads, which only track the number of actions currently being executed, a rate limiter restricts the number of actions in a given period.
Failsafe gives us two rate limiters that we can use – bursty and smooth.
Bursty rate limiters work with a fixed time window and allow a maximum number of executions in this window:
RateLimiter<Object> rateLimiter = RateLimiter.burstyBuilder(100, Duration.ofSeconds(1))
.withMaxWaitTime(Duration.ofMillis(200))
.build();
In this case, we’re able to execute 100 actions every second. We’ve configured a wait time that actions can block until they’re executed or failed. These are called bursty because the counts drop back to zero at the end of the window, so we can suddenly allow executions to start again.
In particular, with our wait time, all executions blocking that wait time will suddenly be able to execute at the end of the rate limiter window.
Smooth rate limiters work instead by spreading the executions over the time window:
RateLimiter<Object> rateLimiter = RateLimiter.smoothBuilder(100, Duration.ofSeconds(1))
.withMaxWaitTime(Duration.ofMillis(200))
.build();
This looks very similar to before. However, in this case, the executions will be smoothed out over the window. This means instead of allowing 100 executions within a one-second window, we allow one execution every 1/100 seconds. Any executions faster than this will hit our wait time or else fail.
5.6. Circuit Breaker Policies
Unlike most other policies, we can use circuit breakers so our application can fail fast if the action is perceived to be already failing. For example, if we’re making calls to a remote service and know it’s not responding, then there’s no point in trying – we can immediately fail without spending the time and resources first.
Circuit breakers work in a three-state system. The default state is Closed, which means that all actions are attempted as if the circuit breaker weren’t present. However, if enough of those actions fail, the circuit breaker will move to Open.
The Open state means no actions are attempted, and all calls will immediately fail. The circuit breaker will remain like this for some time before moving to Half-Open.
The Half-Open state means that actions are attempted, but we have a different failure threshold to determine whether we move to Closed or Open.
For example:
CircuitBreaker<Object> circuitBreaker = CircuitBreaker.builder()
.withFailureThreshold(7, 10)
.withDelay(Duration.ofMillis(500))
.withSuccessThreshold(4, 5)
.build();
This setup will move from Closed to Open if we have 7 failures out of the last 10 requests, from Open to Half-Open after 500ms, from Half-Open to Closed if we have 4 successes out of the last 10 requests, or back to Open if we get 2 failures out of the last 5 requests.
We can also configure our failure threshold to be time-based. For example, let’s open the circuit if we have five failures in the last 30 seconds:
CircuitBreaker<Object> circuitBreaker = CircuitBreaker.builder()
.withFailureThreshold(5, Duration.ofSeconds(30))
.build();
We can additionally configure it to be a percentage of requests instead of a fixed number. For example, let’s open the circuit if we have a 20% failure rate in any 5-minute period that has at least 100 requests:
CircuitBreaker<Object> circuitBreaker = CircuitBreaker.builder()
.withFailureRateThreshold(20, 100, Duration.ofMinutes(5))
.build();
Doing this allows us to adjust to load much more quickly. If we have a very low load, we might not want to check for failures at all, but if we have a very high load, the chance of failures increases, so we want to react only if it gets over our threshold.
6. Summary
In this article, we’ve given a broad introduction to Failsafe. This library can do much more, so why not try it out and see?
All of the examples are available over on GitHub.