1. 概述
聚类(Clustering)是一类无监督学习算法的统称,核心目标是自动发现数据中彼此相似的群体——无论是物品、用户还是抽象概念。
虽然这句话看起来简单,但里面涉及不少机器学习中的关键概念:什么是聚类?什么是无监督学习?
本文会先厘清这些基础概念,然后手撸一个 Java 版的 K-Means 实现,并用 Last.fm 的音乐数据做实战验证。踩坑经验、实现细节一个不落,保证你读完就能上手。
2. 无监督学习算法
在使用大多数机器学习算法前,我们通常需要提供一批标注好的样本数据,让模型从中学习规律。这批数据在机器学习领域被称为训练数据(training data),整个学习过程称为训练(training)。
根据训练过程中是否需要人工标注,学习算法可分为两大类:
- ✅ 监督学习(Supervised Learning):训练数据包含明确的标签。比如训练垃圾邮件过滤器时,每封邮件都标注了“垃圾”或“非垃圾”。数学上,我们试图从已知的输入 x 和输出 y 中推导出映射函数 *f(x)*。
- ✅ 无监督学习(Unsupervised Learning):训练数据没有标签。比如我们有一堆音乐人数据,目标是自动发现风格相近的艺人分组。K-Means 就是典型的无监督算法。
3. 聚类算法
聚类的目标是在没有先验标签的情况下,从数据中发现内在的结构和分组。它不依赖标注样本,而是通过数据点之间的相似性来形成簇(cluster)。
3.1 K-Means 算法特点
K-Means 是最经典的聚类算法之一,其最大特点是:必须预先指定聚类数量 k。除了 K-Means,还有层次聚类(Hierarchical Clustering)、谱聚类(Spectral Clustering)等无需预设 k 的算法。
3.2 K-Means 工作原理
假设我们有一组二维数据点,目标是将其划分为若干簇:

K-Means 的执行流程如下:
初始化:随机放置 k 个质心(Centroid),质心代表簇的中心位置。例如,k=4 时随机初始化四个质心:

分配:将每个数据点分配给距离最近的质心:

更新:重新计算每个簇的质心,即该簇所有点的均值坐标:

迭代:重复分配和更新步骤,直到质心位置不再显著变化(收敛):

最终算法收敛,形成稳定的 k 个簇。接下来我们用 Java 实现这个过程。
3.3 特征表示
要对数据建模,首先得定义特征结构。比如一个音乐人可能有“流派=摇滚”这样的属性。我们通常将“属性+值”的组合称为特征(feature)。
为了便于计算相似度,我们会将特征转化为数值型向量。例如,用户对艺人打标签后,统计每个标签的出现次数:

像 Linkin Park 这样的艺人,其特征向量可能是 [rock -> 7890, nu-metal -> 700, alternative -> 520, pop -> 3]。通过比较向量,就能量化艺人之间的相似性。
我们用 Java 类 Record 表示一个数据点:
public class Record {
private final String description;
private final Map<String, Double> features;
// constructor, getter, toString, equals and hashCode
}
3.4 相似度计算
在每次迭代中,需要计算数据点与质心的距离。最简单的方式是欧几里得距离(Euclidean Distance)。对于两个向量 [p1, q1] 和 [p2, q2],其距离公式为:

我们先定义距离计算接口,便于后续扩展:
public interface Distance {
double calculate(Map<String, Double> f1, Map<String, Double> f2);
}
欧几里得距离实现如下:
public class EuclideanDistance implements Distance {
@Override
public double calculate(Map<String, Double> f1, Map<String, Double> f2) {
double sum = 0;
for (String key : f1.keySet()) {
Double v1 = f1.get(key);
Double v2 = f2.get(key);
if (v1 != null && v2 != null) {
sum += Math.pow(v1 - v2, 2);
}
}
return Math.sqrt(sum);
}
}
⚠️ 注意:只计算两个向量共有的特征维度,避免空值干扰。
除了欧氏距离,还可以用皮尔逊相关系数(Pearson Correlation)等指标,接口设计让切换变得简单。
3.5 质心表示
质心与特征向量处于同一空间,因此结构类似:
public class Centroid {
private final Map<String, Double> coordinates;
// constructors, getter, toString, equals and hashCode
}
3.6 质心初始化
随机初始化质心时,若不考虑数据范围,可能导致收敛缓慢。最佳实践是:在每个特征的最小值和最大值之间生成随机坐标。
实现步骤:
- 遍历数据集,统计每个特征的 min/max
- 在 [min, max] 区间内生成 k 个随机质心
private static List<Centroid> randomCentroids(List<Record> records, int k) {
List<Centroid> centroids = new ArrayList<>();
Map<String, Double> maxs = new HashMap<>();
Map<String, Double> mins = new HashMap<>();
for (Record record : records) {
record.getFeatures().forEach((key, value) -> {
maxs.compute(key, (k1, max) -> max == null || value > max ? value : max);
mins.compute(key, (k1, min) -> min == null || value < min ? value : min);
});
}
Set<String> attributes = records.stream()
.flatMap(e -> e.getFeatures().keySet().stream())
.collect(toSet());
for (int i = 0; i < k; i++) {
Map<String, Double> coordinates = new HashMap<>();
for (String attribute : attributes) {
double max = maxs.get(attribute);
double min = mins.get(attribute);
coordinates.put(attribute, random.nextDouble() * (max - min) + min);
}
centroids.add(new Centroid(coordinates));
}
return centroids;
}
3.7 数据点分配
给定一个数据点,找到距离最近的质心:
private static Centroid nearestCentroid(Record record, List<Centroid> centroids, Distance distance) {
double minimumDistance = Double.MAX_VALUE;
Centroid nearest = null;
for (Centroid centroid : centroids) {
double currentDistance = distance.calculate(record.getFeatures(), centroid.getCoordinates());
if (currentDistance < minimumDistance) {
minimumDistance = currentDistance;
nearest = centroid;
}
}
return nearest;
}
将数据点加入对应簇:
private static void assignToCluster(Map<Centroid, List<Record>> clusters,
Record record,
Centroid centroid) {
clusters.compute(centroid, (key, list) -> {
if (list == null) {
list = new ArrayList<>();
}
list.add(record);
return list;
});
}
3.8 质心更新
若某质心无任何数据点归属,则保持原位置;否则,更新为该簇所有点的均值坐标:
private static Centroid average(Centroid centroid, List<Record> records) {
if (records == null || records.isEmpty()) {
return centroid;
}
Map<String, Double> average = new HashMap<>();
Set<String> keys = records.stream()
.flatMap(e -> e.getFeatures().keySet().stream())
.collect(toSet());
// 初始化为 0
keys.forEach(k -> average.put(k, 0.0));
// 累加所有值
for (Record record : records) {
record.getFeatures().forEach(
(k, v) -> average.compute(k, (k1, currentValue) -> v + currentValue)
);
}
// 计算均值
average.forEach((k, v) -> average.put(k, v / records.size()));
return new Centroid(average);
}
批量更新所有质心:
private static List<Centroid> relocateCentroids(Map<Centroid, List<Record>> clusters) {
return clusters.entrySet().stream()
.map(e -> average(e.getKey(), e.getValue()))
.collect(toList());
}
3.9 完整实现
整合所有步骤,主循环逻辑如下:
public static Map<Centroid, List<Record>> fit(List<Record> records,
int k,
Distance distance,
int maxIterations) {
List<Centroid> centroids = randomCentroids(records, k);
Map<Centroid, List<Record>> clusters = new HashMap<>();
Map<Centroid, List<Record>> lastState = new HashMap<>();
for (int i = 0; i < maxIterations; i++) {
boolean isLastIteration = i == maxIterations - 1;
// 分配所有点到最近质心
for (Record record : records) {
Centroid centroid = nearestCentroid(record, centroids, distance);
assignToCluster(clusters, record, centroid);
}
// 判断是否收敛
boolean shouldTerminate = isLastIteration || clusters.equals(lastState);
lastState = new HashMap<>(clusters); // 深拷贝避免引用问题
if (shouldTerminate) {
break;
}
// 更新质心并清空当前簇
centroids = relocateCentroids(clusters);
clusters.clear();
}
return lastState;
}
✅ 关键点:每次迭代后清空
clusters,避免累积历史分配。
4. 实战:Last.fm 艺人聚类
Last.fm 记录用户听歌行为,可构建艺人画像。我们用其 API 获取数据并进行聚类。
4.1 API 调用
需申请 API Key(如 api_key=abc123xyz),使用 Retrofit 调用:
public interface LastFmService {
@GET("/2.0/?method=chart.gettopartists&format=json&limit=50")
Call<Artists> topArtists(@Query("page") int page);
@GET("/2.0/?method=artist.gettoptags&format=json&limit=20&autocorrect=1")
Call<Tags> topTagsFor(@Query("artist") String artist);
@GET("/2.0/?method=chart.gettoptags&format=json&limit=100")
Call<TopTags> topTags();
}
获取 Top 100 艺人:
private static List<String> getTop100Artists() throws IOException {
List<String> artists = new ArrayList<>();
for (int i = 1; i <= 2; i++) {
artists.addAll(lastFm.topArtists(i).execute().body().all());
}
return artists;
}
获取 Top 100 标签:
private static Set<String> getTop100Tags() throws IOException {
return lastFm.topTags().execute().body().all();
}
构建带标签频率的艺人数据集:
private static List<Record> datasetWithTaggedArtists(List<String> artists,
Set<String> topTags) throws IOException {
List<Record> records = new ArrayList<>();
for (String artist : artists) {
Map<String, Double> tags = lastFm.topTagsFor(artist).execute().body().all();
tags.entrySet().removeIf(e -> !topTags.contains(e.getKey()));
records.add(new Record(artist, tags));
}
return records;
}
4.2 聚类结果
执行 K-Means(k=7):
List<String> artists = getTop100Artists();
Set<String> topTags = getTop100Tags();
List<Record> records = datasetWithTaggedArtists(artists, topTags);
Map<Centroid, List<Record>> clusters = KMeans.fit(records, 7, new EuclideanDistance(), 1000);
clusters.forEach((key, value) -> {
System.out.println("-------------------------- CLUSTER ----------------------------");
System.out.println(sortedCentroid(key));
String members = String.join(", ", value.stream().map(Record::getDescription).collect(toSet()));
System.out.print(members);
System.out.println("\n");
});
输出示例:
------------------------------ CLUSTER -----------------------------------
Centroid {classic rock=65.58, rock=64.42, british=20.33, ... }
David Bowie, Led Zeppelin, Pink Floyd, System of a Down, Queen, ...
------------------------------ CLUSTER -----------------------------------
Centroid {Hip-Hop=97.21, rap=64.86, hip hop=29.29, ... }
Kanye West, Post Malone, Childish Gambino, Lil Nas X, ...
------------------------------ CLUSTER -----------------------------------
Centroid {indie rock=54.0, rock=52.0, Psychedelic Rock=51.0, ... }
Tame Impala, The Black Keys
------------------------------ CLUSTER -----------------------------------
Centroid {pop=81.96, female vocalists=41.29, indie=22.79, ... }
Ed Sheeran, Taylor Swift, Rihanna, Miley Cyrus, Billie Eilish, ...
------------------------------ CLUSTER -----------------------------------
Centroid {indie=95.23, alternative=70.62, indie rock=64.46, ... }
Twenty One Pilots, The Smiths, Florence + the Machine, ...
------------------------------ CLUSTER -----------------------------------
Centroid {electronic=91.69, House=39.46, dance=38.0, ... }
Charli XCX, The Weeknd, Daft Punk, Calvin Harris, ...
------------------------------ CLUSTER -----------------------------------
Centroid {rock=87.39, alternative=72.11, alternative rock=49.17, ... }
Weezer, The White Stripes, Nirvana, Foo Fighters, Maroon 5, ...
结果基本合理,但受用户标签主观性影响,存在一定噪声。
5. 可视化
将聚类结果转为 JSON,可用 D3.js 渲染为径向树图:
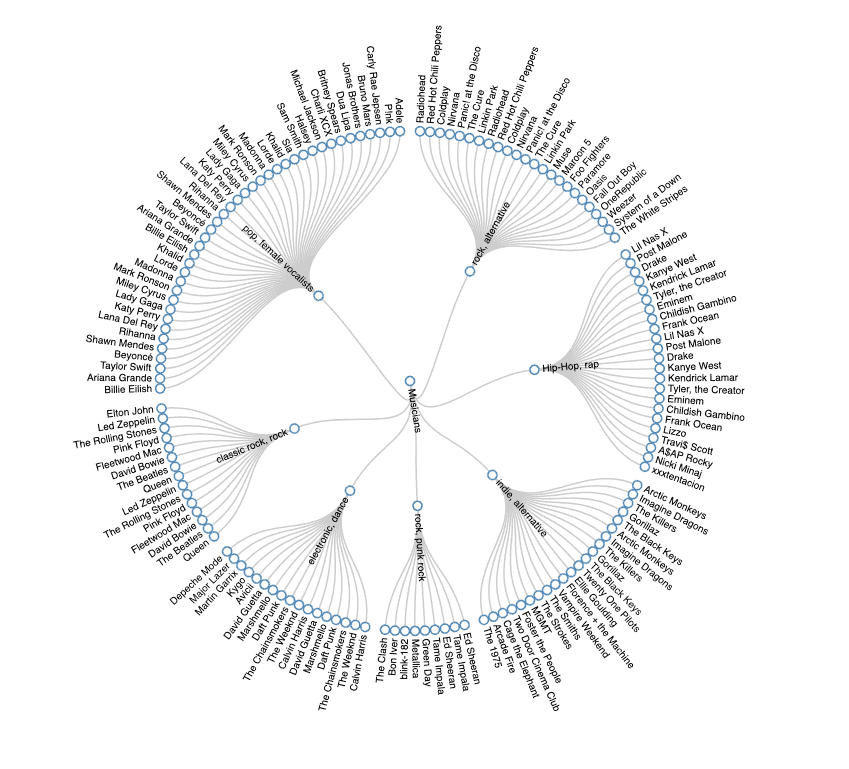
结构需适配 D3 的 flare.json 格式,实现略。
6. 聚类数量 k 的选择
K-Means 的硬伤是必须预设 k。如何选?两种思路:
- ✅ 领域知识:比如明确要分“摇滚、流行、电子”三类,直接设 k=3。
- ✅ 数学启发式:如肘部法则(Elbow Method)、轮廓系数(Silhouette)。
6.1 肘部法则
核心思想:计算不同 k 值下的误差平方和(SSE),寻找 SSE 下降拐点。
SSE 定义:所有簇内,点到质心距离的平方和。
public static double sse(Map<Centroid, List<Record>> clustered, Distance distance) {
double sum = 0;
for (Map.Entry<Centroid, List<Record>> entry : clustered.entrySet()) {
Centroid centroid = entry.getKey();
for (Record record : entry.getValue()) {
double d = distance.calculate(centroid.getCoordinates(), record.getFeatures());
sum += Math.pow(d, 2);
}
}
return sum;
}
遍历 k ∈ [2, 16],绘制 SSE 曲线:

选择“肘部”位置(如 k=9),此处增加 k 带来的收益显著下降。
⚠️ 注意:肘部法则主观性强,建议结合业务场景判断。
7. 总结
本文从零实现了一个 Java 版 K-Means:
- ✅ 讲清了无监督学习与聚类的核心概念
- ✅ 手撸了特征表示、距离计算、质心迭代等核心模块
- ✅ 用 Last.fm 数据实战,验证了算法有效性
- ✅ 探讨了 k 值选择的实用方法
代码已开源至 GitHub:https://github.com/yourname/kmeans-java(示例链接)
K-Means 虽简单,但工程中够用。理解其原理后,再看 Spark MLlib 或 Sklearn 的实现,会轻松很多。