1. 引言
本教程将深入解析 LangChain 框架——一个用于开发大语言模型驱动应用的工具集。首先我们会梳理语言模型的基础概念,为后续内容铺垫。
虽然 LangChain 主要提供 Python 和 JavaScript/TypeScript 版本,但 Java 开发者也有可用方案。我们将剖析 LangChain 的核心模块,并通过 Java 实践演示其用法。
2. 背景知识
在探讨为何需要语言模型开发框架前,必须先理解语言模型本身及其常见复杂性。
2.1 大语言模型
语言模型是自然语言的概率模型,能预测单词序列的出现概率。而大语言模型(LLM)则以其庞大参数规模(可能达数十亿)为特征,通常基于人工神经网络构建。
LLM 通常在海量无标注数据上预训练,采用自监督和半监督学习技术。随后通过微调和提示工程等手段适配特定任务:
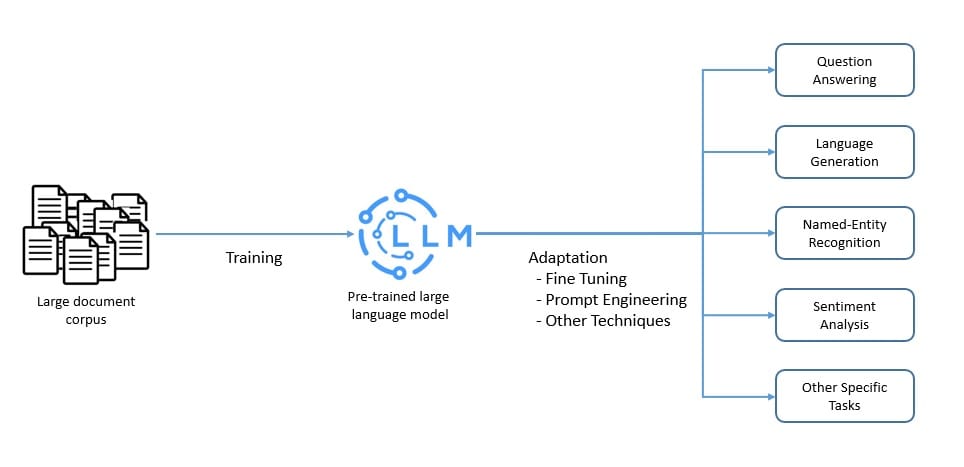
这些模型擅长自然语言处理任务(如翻译、摘要),也具备内容生成能力,因此在问答类应用中极具价值。目前主流云服务商均已集成大语言模型,例如:
- Microsoft Azure 提供 Llama 2 和 OpenAI GPT-4
- Amazon Bedrock 支持 AI21 Labs、Anthropic 等模型
2.2 提示工程
LLM 作为基础模型虽能捕捉人类语言语法语义,但必须通过适配才能执行特定任务。
提示工程是构建 LLM 可理解文本结构的过程。我们用自然语言描述任务需求:
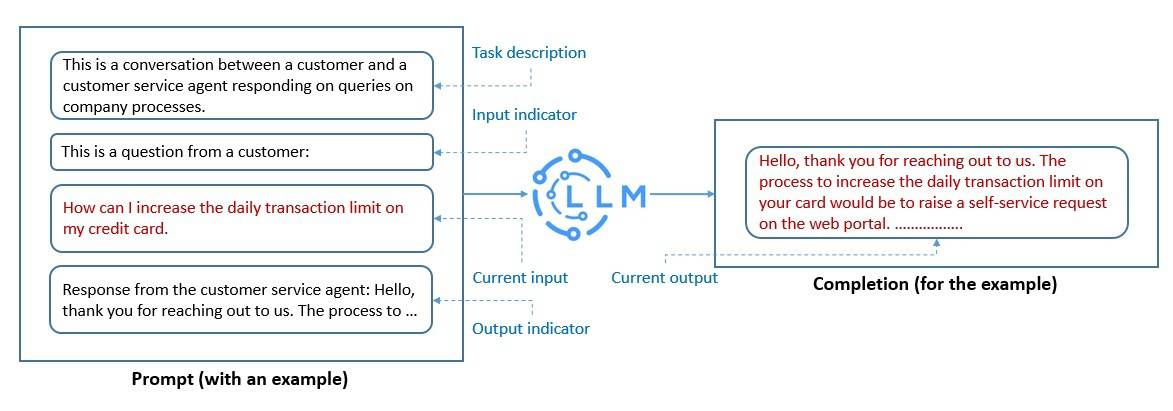
精心设计的提示能帮助 LLM 实现临时性的上下文学习。通过提示工程可:
✅ 促进 LLM 安全使用
✅ 增强领域知识
✅ 集成外部工具
当前热门技术如**思维链提示** 要求 LLM 通过中间步骤推导最终答案。
2.3 词嵌入
为提升 LLM 处理自然语言的效率,需将文本转换为词嵌入——能编码词义的实值向量。
常用生成算法包括:
- Tomáš Mikolov 的 Word2vec
- 斯坦福大学的 GloVe(基于全局词共现统计的无监督算法)
在提示工程中,词嵌入可:
- 增强模型对提示的理解
- 丰富上下文信息
- 支持语义搜索(如将用户输入与向量数据库匹配)
3. 基于 LangChain 的 LLM 技术栈
有效提示设计是发挥 LLM 潜力的关键,这需要:
- 创建提示模板
- 调用语言模型
- 整合多源用户数据
LangChain 作为框架简化了这些任务,并支持:
- 多模型链式调用
- 历史交互记忆
- 推理引擎构建
- 日志/监控/流式处理
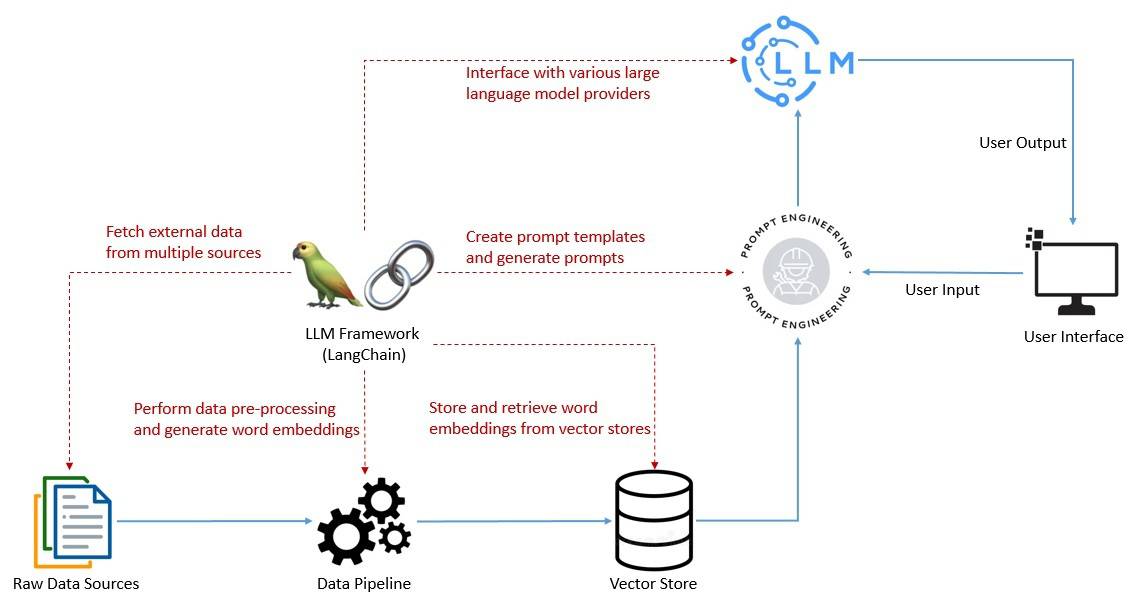
尽管 LLM 技术栈快速演进,LangChain 已成为其中的核心组件。
4. Java 版 LangChain
LangChain 作为2022 年开源项目迅速崛起,最初由 Harrison Chase 用 Python 开发。2023 年初推出的 JavaScript/TypeScript 版本同样火爆,支持 Node.js、浏览器等多种环境。
⚠️ Java 开发者注意:目前无官方 Java 版本,但社区提供了 LangChain4j:
- 兼容 Java 8+
- 支持 Spring Boot 2/3
- Maven Central 提供依赖
核心依赖示例:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.23.0</version>
</dependency>
根据功能需求,可能还需添加:
LangChain4j 提供了简洁的抽象层和丰富实现,已支持 OpenAI、Pinecone 等主流服务。但需注意:
- 功能迭代速度较快
- 部分特性可能落后于 Python/JS 版本
- 核心概念和结构保持一致
5. LangChain 核心模块
LangChain 通过模块化组件提供价值,下面用 Java 演示关键模块。
5.1 模型 I/O
与语言模型交互需要:
- 提示模板化
- 动态输入管理
- 输出解析
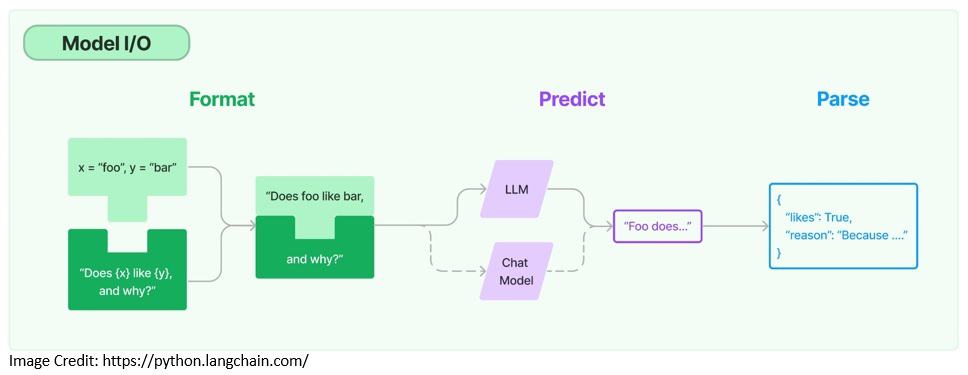
提示模板示例:
PromptTemplate promptTemplate = PromptTemplate
.from("Tell me a {{adjective}} joke about {{content}}..");
Map<String, Object> variables = new HashMap<>();
variables.put("adjective", "funny");
variables.put("content", "computers");
Prompt prompt = promptTemplate.apply(variables);
模型调用示例(支持语言模型和聊天模型):
ChatLanguageModel model = OpenAiChatModel.builder()
.apiKey("sk-xxxxxxxxxxxxxxxxxxxxxxxx") // 替换为真实 API Key
.modelName(GPT_3_5_TURBO)
.temperature(0.3)
.build();
String response = model.generate(prompt.text());
输出解析可将非结构化响应转为 Java POJO,提升数据可用性。
5.2 记忆模块
对话类应用需引用历史交互信息,记忆模块提供此能力:
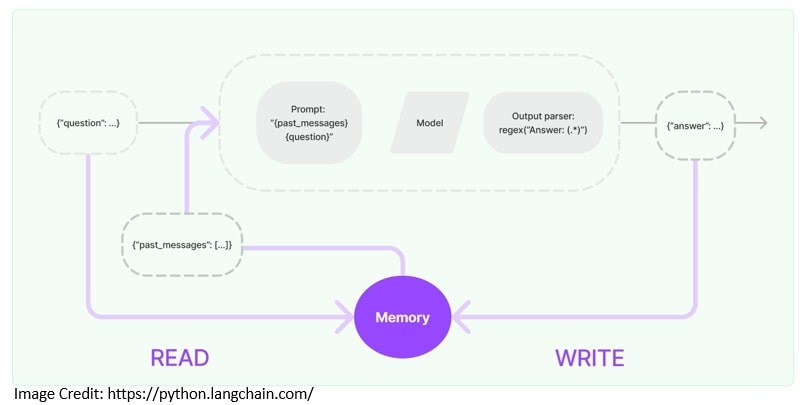
固定窗口记忆实现:
ChatMemory chatMemory = TokenWindowChatMemory
.withMaxTokens(300, new OpenAiTokenizer(GPT_3_5_TURBO));
chatMemory.add(userMessage("Hello, my name is Kumar"));
AiMessage answer = model.generate(chatMemory.messages()).content();
System.out.println(answer.text()); // Hello Kumar! How can I assist you today?
chatMemory.add(answer);
chatMemory.add(userMessage("What is my name?"));
AiMessage answerWithName = model.generate(chatMemory.messages()).content();
System.out.println(answer.text()); // Your name is Kumar.
chatMemory.add(answerWithName);
高级记忆策略包括:
- 消息摘要
- 相关性过滤
- 动态窗口调整
5.3 检索增强
LLM 在通用任务上表现优异,但领域特定任务需外部数据增强。检索增强生成(RAG)流程:
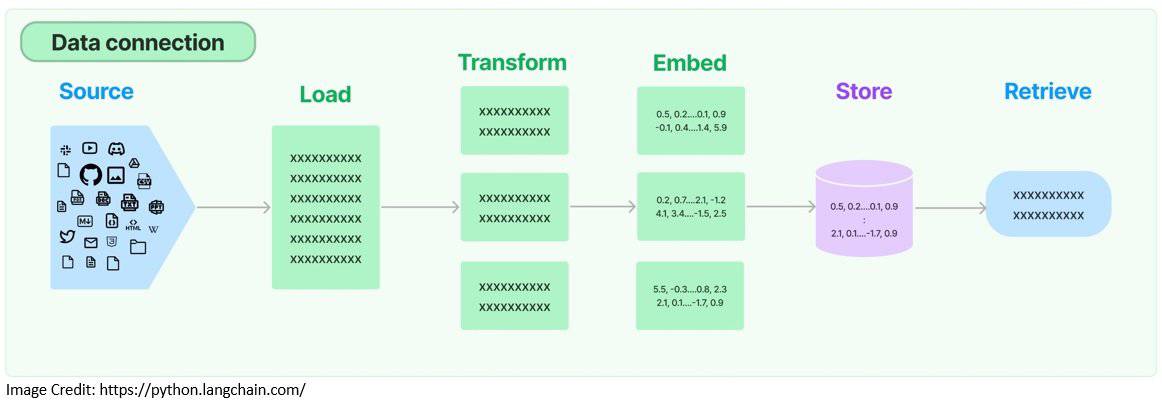
文档加载与分块:
Document document = FileSystemDocumentLoader.loadDocument("simpson's_adventures.txt");
DocumentSplitter splitter = DocumentSplitters.recursive(100, 0,
new OpenAiTokenizer(GPT_3_5_TURBO));
List<TextSegment> segments = splitter.split(document);
词嵌入与存储:
EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel();
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
embeddingStore.addAll(embeddings, segments);
语义检索:
String question = "Who is Simpson?";
Embedding questionEmbedding = embeddingModel.embed(question).content();
int maxResults = 3;
double minScore = 0.7;
List<EmbeddingMatch<TextSegment>> relevantEmbeddings = embeddingStore
.findRelevant(questionEmbedding, maxResults, minScore);
检索结果可作为上下文注入提示,提升回答准确性。
6. LangChain 高级应用
6.1 链式调用
复杂应用需按序组合多个组件,链(Chains)简化了此过程:

对话检索链构建:
ConversationalRetrievalChain chain = ConversationalRetrievalChain.builder()
.chatLanguageModel(chatModel)
.retriever(EmbeddingStoreRetriever.from(embeddingStore, embeddingModel))
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.promptTemplate(PromptTemplate
.from("Answer the following question to the best of your ability: {{question}}\n\nBase your answer on the following information:\n{{information}}"))
.build();
执行查询:
String answer = chain.execute("Who is Simpson?");
链式调用优势:
✅ 模块化实现
✅ 便于调试维护
✅ 支持链组合(如多模型协作)
6.2 代理机制
代理(Agents)将 LLM 作为推理引擎,动态决策操作序列:

LangChain4j 通过 AI Services 实现代理。以计算器工具为例:
工具定义:
public class AIServiceWithCalculator {
static class Calculator {
@Tool("Calculates the length of a string")
int stringLength(String s) {
return s.length();
}
@Tool("Calculates the sum of two numbers")
int add(int a, int b) {
return a + b;
}
}
}
服务接口:
interface Assistant {
String chat(String userMessage);
}
代理构建:
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(OpenAiChatModel.withApiKey("sk-xxxxxxxxxxxxxxxx")) // 替换为真实 Key
.tools(new Calculator())
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.build();
计算任务测试:
String question = "What is the sum of the numbers of letters in the words \"language\" and \"model\"?";
String answer = assistant.chat(question);
System.out.println(answer); // The sum of the numbers of letters in the words "language" and "model" is 13.
⚠️ 踩坑提示:LLM 在时空感知和复杂计算上存在局限,需通过工具扩展能力。
7. 总结
本教程系统梳理了大语言模型应用开发的核心要素,并论证了 LangChain 在技术栈中的价值。通过 LangChain4j 的 Java 实践,我们验证了:
- 模块化设计提升开发效率
- 记忆与检索增强上下文理解
- 链与代理支持复杂应用构建
尽管相关库仍在快速迭代,但已显著提升了语言模型应用开发的成熟度与体验。未来可关注:
- 更多模型提供商集成
- 性能优化方案
- 企业级功能增强
本文代码示例基于 LangChain4j 0.23.0,实际使用时请参考最新文档。