1. 简介
本文将探讨在 Java 中生成给定集合的幂集(Power Set)的方法。
简单回顾一下:对于一个大小为 n 的集合,其幂集的大小为 2^n。我们将学习如何通过多种技术实现这一目标。
2. 幂集的定义
集合 S 的幂集,是指 S 的所有子集构成的集合,包括 S 本身和空集。
例如,给定集合:
{"APPLE", "ORANGE", "MANGO"}
其幂集为:
{
{},
{"APPLE"},
{"ORANGE"},
{"APPLE", "ORANGE"},
{"MANGO"},
{"APPLE", "MANGO"},
{"ORANGE", "MANGO"},
{"APPLE", "ORANGE", "MANGO"}
}
由于幂集本身也是集合,其内部子集的顺序不重要,可以以任意顺序出现。如下也是合法表示:
{
{},
{"MANGO"},
{"ORANGE"},
{"ORANGE", "MANGO"},
{"APPLE"},
{"APPLE", "MANGO"},
{"APPLE", "ORANGE"},
{"APPLE", "ORANGE", "MANGO"}
}
3. 使用 Guava 库
Google 的 Guava 库 提供了强大的集合工具类,其中就包括生成幂集的功能。我们可以非常方便地使用它:
@Test
public void givenSet_WhenGuavaLibraryGeneratePowerSet_ThenItContainsAllSubsets() {
ImmutableSet<String> set = ImmutableSet.of("APPLE", "ORANGE", "MANGO");
Set<Set<String>> powerSet = Sets.powerSet(set);
Assertions.assertEquals((1 << set.size()), powerSet.size());
MatcherAssert.assertThat(powerSet, Matchers.containsInAnyOrder(
ImmutableSet.of(),
ImmutableSet.of("APPLE"),
ImmutableSet.of("ORANGE"),
ImmutableSet.of("APPLE", "ORANGE"),
ImmutableSet.of("MANGO"),
ImmutableSet.of("APPLE", "MANGO"),
ImmutableSet.of("ORANGE", "MANGO"),
ImmutableSet.of("APPLE", "ORANGE", "MANGO")
));
}
✅ 关键点:Guava 的 powerSet 内部基于 Iterator 实现,按需生成子集。也就是说,只有当调用 next() 时才会计算下一个子集,从而将空间复杂度从 O(2^n) 优化到 *O(n)*。
⚠️ 但 Guava 是怎么做到这一点的?我们接下来就揭开它的实现原理。
4. 幂集生成算法
4.1. 算法思路
我们来思考如何手动实现幂集生成。
- 基本情况:空集的幂集是
{ { } },只包含一个空集。 - 递归思路:对于非空集合 S,我们取出一个元素
element,然后递归计算剩余元素组成的集合subsetWithoutElement的幂集,记作powerSetSubsetWithoutElement。 - 然后,我们将
element添加到powerSetSubsetWithoutElement的每一个子集中,得到包含element的所有子集,记作powerSetSubsetWithElement。 - 最终的幂集就是
powerSetSubsetWithoutElement和powerSetSubsetWithElement的并集。

下图展示了集合 {"APPLE", "ORANGE", "MANGO"} 的递归调用栈(为简洁,使用缩写):
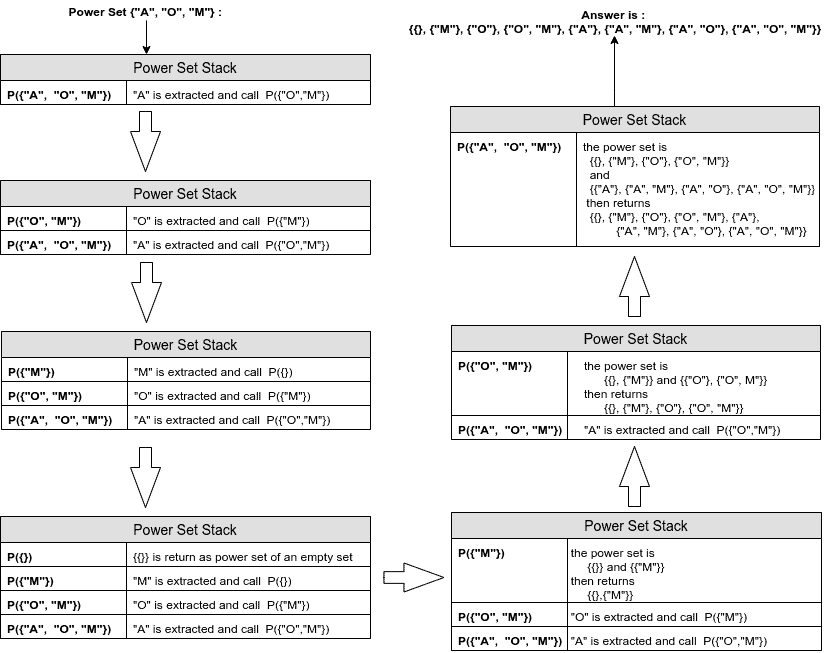
4.2. 递归实现
首先,提取一个元素并获取剩余集合:
T element = set.iterator().next();
Set<T> subsetWithoutElement = new HashSet<>();
for (T s : set) {
if (!s.equals(element)) {
subsetWithoutElement.add(s);
}
}
递归获取剩余集合的幂集:
Set<Set<T>> powerSetSubsetWithoutElement = recursivePowerSet(subsetWithoutElement);
为每个子集添加提取出的元素:
Set<Set<T>> powerSetSubsetWithElement = new HashSet<>();
for (Set<T> subset : powerSetSubsetWithoutElement) {
Set<T> subsetWithElement = new HashSet<>(subset);
subsetWithElement.add(element);
powerSetSubsetWithElement.add(subsetWithElement);
}
合并两个部分,得到最终结果:
Set<Set<T>> powerSet = new HashSet<>();
powerSet.addAll(powerSetSubsetWithoutElement);
powerSet.addAll(powerSetSubsetWithElement);
整合后的完整递归实现:
public Set<Set<T>> recursivePowerSet(Set<T> set) {
if (set.isEmpty()) {
Set<Set<T>> ret = new HashSet<>();
ret.add(set);
return ret;
}
T element = set.iterator().next();
Set<T> subSetWithoutElement = getSubSetWithoutElement(set, element);
Set<Set<T>> powerSetSubSetWithoutElement = recursivePowerSet(subSetWithoutElement);
Set<Set<T>> powerSetSubSetWithElement = addElementToAll(powerSetSubSetWithoutElement, element);
Set<Set<T>> powerSet = new HashSet<>();
powerSet.addAll(powerSetSubSetWithoutElement);
powerSet.addAll(powerSetSubSetWithElement);
return powerSet;
}
4.3. 单元测试要点
测试幂集生成函数时,需验证以下几点:
- ✅ 幂集大小应为
2^n - ✅ 每个原始元素应恰好出现在
2^(n-1)个子集中 - ✅ 每个子集唯一(
Set<Set>结构已保证无重复)
由于我们使用 Set<Set<T>>,重复问题已自动解决。因此只需验证大小和元素出现次数。
验证大小:
MatcherAssert.assertThat(powerSet, IsCollectionWithSize.hasSize((1 << set.size())));
验证元素出现次数:
Map<String, Integer> counter = new HashMap<>();
for (Set<String> subset : powerSet) {
for (String name : subset) {
int num = counter.getOrDefault(name, 0);
counter.put(name, num + 1);
}
}
counter.forEach((k, v) -> Assertions.assertEquals((1 << (set.size() - 1)), v.intValue()));
完整测试用例:
@Test
public void givenSet_WhenPowerSetIsCalculated_ThenItContainsAllSubsets() {
Set<String> set = RandomSetOfStringGenerator.generateRandomSet();
Set<Set<String>> powerSet = new PowerSet<String>().recursivePowerSet(set);
MatcherAssert.assertThat(powerSet, IsCollectionWithSize.hasSize((1 << set.size())));
Map<String, Integer> counter = new HashMap<>();
for (Set<String> subset : powerSet) {
for (String name : subset) {
int num = counter.getOrDefault(name, 0);
counter.put(name, num + 1);
}
}
counter.forEach((k, v) -> Assertions.assertEquals((1 << (set.size() - 1)), v.intValue()));
}
5. 性能优化
上一节的递归方法涉及大量集合操作,效率不高。本节我们通过数据结构优化,减少内存和时间开销。
5.1. 数据结构设计
核心思路:将集合元素映射为索引,用数字代替对象操作。
步骤:
- 将集合元素映射到
[0, n-1]的整数 - 用索引或二进制位表示子集
- 最后反向映射回原始对象
映射实现:
private Map<T, Integer> map = new HashMap<>();
private List<T> reverseMap = new ArrayList<>();
private void initializeMap(Collection<T> collection) {
int mapId = 0;
for (T c : collection) {
map.put(c, mapId++);
reverseMap.add(c);
}
}
5.2. 索引表示法
用索引集合表示子集,例如:
{} -> {}
[0] -> {"APPLE"}
[1] -> {"ORANGE"}
[0,1] -> {"APPLE", "ORANGE"}
...
反向映射代码:
private Set<Set<T>> unMapIndex(Set<Set<Integer>> sets) {
Set<Set<T>> ret = new HashSet<>();
for (Set<Integer> s : sets) {
HashSet<T> subset = new HashSet<>();
for (Integer i : s) {
subset.add(reverseMap.get(i));
}
ret.add(subset);
}
return ret;
}
5.3. 二进制表示法
用长度为 n 的二进制数组表示子集,1 表示包含,0 表示不包含:
[0,0,0] -> {}
[1,0,0] -> {"APPLE"}
[0,1,0] -> {"ORANGE"}
[1,1,0] -> {"APPLE", "ORANGE"}
...
反向映射代码:
private Set<Set<T>> unMapBinary(Collection<List<Boolean>> sets) {
Set<Set<T>> ret = new HashSet<>();
for (List<Boolean> s : sets) {
HashSet<T> subset = new HashSet<>();
for (int i = 0; i < s.size(); i++) {
if (s.get(i)) {
subset.add(reverseMap.get(i));
}
}
ret.add(subset);
}
return ret;
}
5.4. 递归实现(优化版)
使用索引表示法的递归实现:
public Set<Set<T>> recursivePowerSetIndexRepresentation(Collection<T> set) {
initializeMap(set);
Set<Set<Integer>> powerSetIndices = recursivePowerSetIndexRepresentation(0, set.size());
return unMapIndex(powerSetIndices);
}
private Set<Set<Integer>> recursivePowerSetIndexRepresentation(int idx, int n) {
if (idx == n) {
Set<Set<Integer>> empty = new HashSet<>();
empty.add(new HashSet<>());
return empty;
}
Set<Set<Integer>> powerSetSubset = recursivePowerSetIndexRepresentation(idx + 1, n);
Set<Set<Integer>> powerSet = new HashSet<>(powerSetSubset);
for (Set<Integer> s : powerSetSubset) {
HashSet<Integer> subSetIdxInclusive = new HashSet<>(s);
subSetIdxInclusive.add(idx);
powerSet.add(subSetIdxInclusive);
}
return powerSet;
}
使用二进制表示法的递归实现:
private Set<List<Boolean>> recursivePowerSetBinaryRepresentation(int idx, int n) {
if (idx == n) {
Set<List<Boolean>> powerSetOfEmptySet = new HashSet<>();
powerSetOfEmptySet.add(Arrays.asList(new Boolean[n]));
return powerSetOfEmptySet;
}
Set<List<Boolean>> powerSetSubset = recursivePowerSetBinaryRepresentation(idx + 1, n);
Set<List<Boolean>> powerSet = new HashSet<>();
for (List<Boolean> s : powerSetSubset) {
List<Boolean> subSetIdxExclusive = new ArrayList<>(s);
subSetIdxExclusive.set(idx, false);
powerSet.add(subSetIdxExclusive);
List<Boolean> subSetIdxInclusive = new ArrayList<>(s);
subSetIdxInclusive.set(idx, true);
powerSet.add(subSetIdxInclusive);
}
return powerSet;
}
5.5. 迭代法:遍历 [0, 2^n)
二进制表示法的进一步优化:遍历 0 到 2^n - 1,将每个数转为二进制,即为一个子集的掩码。
简单粗暴,效率高:
private List<List<Boolean>> iterativePowerSetByLoopOverNumbers(int n) {
List<List<Boolean>> powerSet = new ArrayList<>();
for (int i = 0; i < (1 << n); i++) {
List<Boolean> subset = new ArrayList<>(n);
for (int j = 0; j < n; j++)
subset.add(((1 << j) & i) > 0);
powerSet.add(subset);
}
return powerSet;
}
5.6. 格雷码优化:最小变化
格雷码(Gray Code)的特点是:相邻两个数的二进制表示只有一位不同。
这在某些场景下(如状态切换)非常有用,可以减少状态翻转次数。
实现:
private List<List<Boolean>> iterativePowerSetByLoopOverNumbersWithGrayCodeOrder(int n) {
List<List<Boolean>> powerSet = new ArrayList<>();
for (int i = 0; i < (1 << n); i++) {
List<Boolean> subset = new ArrayList<>(n);
for (int j = 0; j < n; j++) {
int grayEquivalent = i ^ (i >> 1);
subset.add(((1 << j) & grayEquivalent) > 0);
}
powerSet.add(subset);
}
return powerSet;
}
6. 惰性加载(Lazy Loading)
为解决幂集空间占用 O(2^n) 的问题,我们可以实现惰性加载,即通过 Iterator 按需生成子集。
6.1. ListIterator
自定义迭代器,避免一次性生成所有子集:
abstract class ListIterator<K> implements Iterator<K> {
protected int position = 0;
private int size;
public ListIterator(int size) {
this.size = size;
}
@Override
public boolean hasNext() {
return position < size;
}
}
next() 方法返回当前子集并递增位置:
@Override
public Set<E> next() {
return new Subset<>(map, reverseMap, position++);
}
6.2. Subset
Subset 类扩展 AbstractSet,实现惰性加载:
size():计算掩码中 1 的个数contains():检查对应位是否为 1
@Override
public int size() {
return Integer.bitCount(mask);
}
@Override
public boolean contains(@Nullable Object o) {
Integer index = map.get(o);
return index != null && (mask & (1 << index)) != 0;
}
内部迭代器通过 remainingSetBits 跟踪未遍历的元素:
@Override
public boolean hasNext() {
return remainingSetBits != 0;
}
@Override
public E next() {
int index = Integer.numberOfTrailingZeros(remainingSetBits);
if (index == 32) {
throw new NoSuchElementException();
}
remainingSetBits &= ~(1 << index);
return reverseMap.get(index);
}
6.3. PowerSet
PowerSet 类扩展 AbstractSet<Set<T>>,实现惰性生成:
@Override
public int size() {
return (1 << this.set.size());
}
@Override
public boolean contains(@Nullable Object obj) {
if (obj instanceof Set) {
Set<?> set = (Set<?>) obj;
return reverseMap.containsAll(set);
}
return false;
}
@Override
public Iterator<Set<E>> iterator() {
return new ListIterator<Set<E>>(this.size()) {
@Override
public Set<E> next() {
return new Subset<>(map, reverseMap, position++);
}
};
}
✅ 揭秘:Guava 的 Sets.powerSet() 正是基于这种惰性加载思想实现的。其内部的 PowerSet 和 Subset 类与上述实现高度相似。
🔗 源码参考:Guava Sets.java
此外,这种设计还便于并行处理——我们可以将不同的 position 值分发到线程池中并发生成子集。
7. 总结
本文系统地探讨了 Java 中生成幂集的多种方法:
- ✅ 快速上手:直接使用 Guava 的
Sets.powerSet(),简洁高效 - ✅ 理解原理:通过递归分治理解幂集的数学本质
- ✅ 性能优化:利用索引、二进制掩码和迭代法提升效率
- ✅ 空间优化:通过惰性加载将空间复杂度降至 O(n)
最终我们发现,Guava 的实现正是结合了二进制掩码和惰性迭代的最优解,既节省内存,又支持按需访问。