1. 概述
Elasticsearch 是一款强大的全文检索与分析引擎,也是该领域领先的开源项目之一。它基于 Apache Lucene 构建,天然具备分布式处理海量数据的能力。
本文将深入探讨 Elasticsearch 的水平扩展、容错和高可用机制。通过理解这些核心概念,你将能更高效地利用 Elasticsearch 的能力,并避开常见的配置陷阱。
2. 分片(Shards)
分片是 Elasticsearch 实现容错和扩展的关键机制。每个分片都是索引数据的子集,本质上是存储在节点中的 Lucene 索引实例。通过分片,数据被水平分布到集群的各个节点,避免单点故障。
Elasticsearch 索引实际是分布在集群中的数据集合。集群由多个可通信的 Elasticsearch 节点组成,可包含多个索引和分片。这种设计确保了即使某个节点宕机,也只有部分数据不可用,集群仍能继续服务。
分片带来的核心优势:
✅ 提升容错性:避免单节点故障导致整体服务中断
✅ 优化性能:分片并行处理请求,充分利用集群资源
✅ 加速查询:查询分散到不同分片并行执行,减少扫描数据量
⚠️ 但分片也有代价:跨节点协调会增加网络开销和资源消耗。
2.1. 分片配置规范
当前 Elasticsearch 8.7 版本中,创建索引时若未指定分片数,默认值为 1。需通过 settings.index.number_of_shards 参数显式设置。注意:此参数是静态的,创建后不可修改。
Elasticsearch 自动分配分片到节点,并为每个分片分配唯一 ID。这些分片称为主分片(Primary Shards),负责所有写操作。下图展示了一个典型的分片布局:

默认情况下,Elasticsearch 通过文档 ID 的哈希值路由请求到目标分片。这个路由算法是确定性的——相同 ID 的文档始终路由到同一分片,确保数据均衡分布。
3. 副本(Replicas)
主分片承载着核心数据和请求处理能力,一旦丢失后果严重。副本就是主分片的精确拷贝,部署在不同节点上,用于提升集群的可用性和容错能力。当主分片故障时,对应副本可立即晋升为主分片,保证服务不中断。
关键特性:
- 副本与主分片必须位于不同节点(否则失去容错意义)
- 副本可处理读请求,分担集群负载,提升整体吞吐量
- 副本仅接受来自主分片的写操作,确保数据一致性
3.1. 副本配置规范
在 Elasticsearch 8.7 中,创建索引时若未指定副本数,默认值为 1。通过 settings.index.number_of_replicas 参数设置。与分片数不同,副本数可在索引生命周期中动态调整。
Elasticsearch 会自动分配副本,确保与主分片不在同一节点:
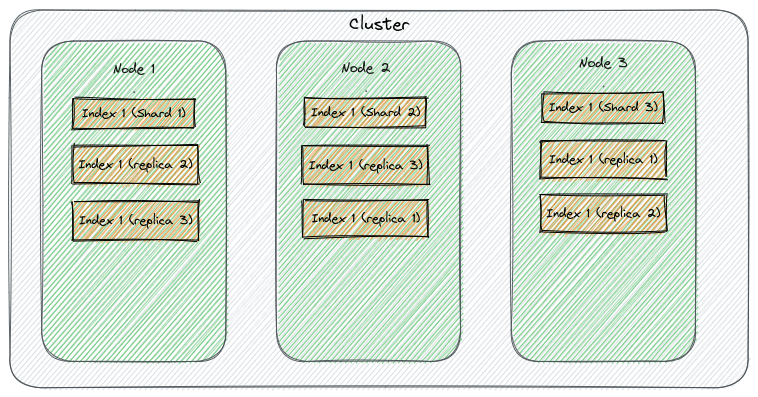
高级配置 settings.index.auto_expand_replicas 允许副本数随集群节点增加自动扩展。
索引健康状态通过三种颜色标识:
- 🟢 Green:所有主分片和副本均正常分配
- 🟡 Yellow:主分片正常,但部分副本缺失(通常因节点离线)
- 🔴 Red:存在主分片丢失(数据不可用,需立即处理)
4. 集群配置实战
配置集群时需平衡性能、成本与可靠性。以下是常见踩坑点及解决方案:
4.1. 副本配置失衡
❌ 过度复制:浪费存储和网络资源,增加管理开销
❌ 副本不足:存在数据丢失风险,容灾能力弱
✅ 建议:根据业务容忍度设置副本数(如关键业务≥2副本)
4.2. 分片分布不均
❌ 分片过多:导致资源浪费(每个分片消耗内存/文件句柄)
❌ 分片过少:引发热点问题(单个分片负载过高)
✅ 建议:单分片大小控制在 20-50GB,根据数据量和查询模式动态调整
4.3. 分片分配策略失误
❌ 分配集中:部分节点过载,其他节点闲置
❌ 未感知节点差异:未区分冷热节点或硬件规格
✅ 建议:使用分片分配感知(Awareness)属性,结合节点标签优化分配
4.4. 同步/刷新频率不当
关键参数:
index.refresh_interval:控制数据可见性(默认1s)index.translog.sync_interval:控制数据持久化频率- Flush API:强制刷盘
❌ 刷新过频:增加磁盘 I/O 和 CPU 压力
❌ 同步过慢:故障时可能丢失更多数据
✅ 建议:
- 日志类场景:增大刷新间隔(如30s)提升写入性能
- 关键业务:缩短同步间隔保障数据安全
5. 总结
Elasticsearch 的分片与副本机制是其分布式能力的核心。通过合理配置:
- 分片实现数据水平扩展与并行处理
- 副本提供容灾保障与读性能扩展
最佳实践原则:
- 根据数据规模和负载模式规划分片数
- 副本数≥1,关键业务≥2
- 监控集群状态(避免 Yellow/Red)
- 定期评估配置合理性(数据增长后需调整)
掌握这些机制,你就能构建出既高性能又高可用的 Elasticsearch 集群,避开那些让运维人员头秃的坑。