1. 概述
在这个教程中,我们将利用Java微基准测试框架(Java Microbenchmark Harness,JMH)探讨Collections.sort()方法的时间复杂性,并通过示例展示其效率。我们将分析在最佳、平均和最坏情况下,算法的性能表现。
2. 时间复杂性
理解算法的时间复杂性对于评估其效率至关重要。具体来说,Collections.sort()方法在最佳情况下的时间复杂度是**O(n),而在最坏和平均情况下是O(n log n)**,其中n是集合中的元素数量。
2.1. 最佳情况时间复杂性
在Java中,Collections.sort()使用了TimSort排序算法。例如,当TimSort遇到几乎有序的数组时,其时间复杂度为**O(n)**。它会利用现有的顺序,高效地对数据进行排序。在这种情况下,大约需要进行20-25次比较和交换操作。
下面的Java代码演示了使用Collections.sort()方法对已排序数组进行排序的时间复杂性:
public static void bestCaseTimeComplexity() {
Integer[] sortedArray = {19, 22, 19, 22, 24, 25, 17, 11, 22, 23, 28, 23, 0, 1, 12, 9, 13, 27, 15};
List<Integer> list = Arrays.asList(sortedArray);
long startTime = System.nanoTime();
Collections.sort(list);
long endTime = System.nanoTime();
System.out.println("Execution Time for O(n): " + (endTime - startTime) + " nanoseconds");
}
2.2. 平均和最坏情况时间复杂性
对于未排序的数组,TimSort在平均和最坏情况下的时间复杂度为**O(n log n)**,因为它需要更多的比较和交换操作来排序数组。
如下图所示:
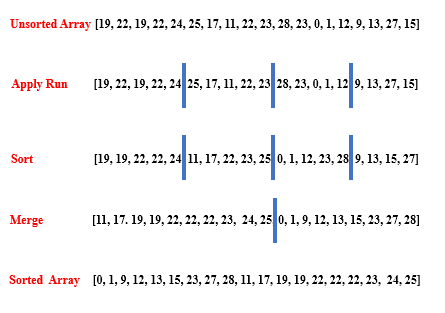
对于这个特定的数组,TimSort大约需要进行60-70次比较和交换。
运行以下代码将展示对无序列表进行排序的执行时间,显示Collections.sort()使用的排序算法在平均和最差情况下的性能:
public static void worstAndAverageCasesTimeComplexity() {
Integer[] sortedArray = {20, 21, 22, 23, 24, 25, 26, 17, 28, 29, 30, 31, 18, 19, 32, 33, 34, 27, 35};
List<Integer> list = Arrays.asList(sortedArray);
Collections.shuffle(list);
long startTime = System.nanoTime();
Collections.sort(list);
long endTime = System.nanoTime();
System.out.println("Execution Time for O(n log n): " + (endTime - startTime) + " nanoseconds");
}
3. JMH报告
在这一部分,我们将使用JMH来评估Collections.sort()的方法效率和性能特性。
以下配置对于在不太有利的情况下评估排序算法的效率至关重要,为我们提供了关于平均和最差情况行为的有价值见解:
@State(Scope.Benchmark)
public static class AverageWorstCaseBenchmarkState {
List<Integer> unsortedList;
@Setup(Level.Trial)
public void setUp() {
unsortedList = new ArrayList<>();
for (int i = 1000000; i > 0; i--) {
unsortedList.add(i);
}
}
}
@Benchmark
public void measureCollectionsSortAverageWorstCase(AverageWorstCaseBenchmarkState state) {
List<Integer> unsortedList = new ArrayList<>(state.unsortedList);
Collections.sort(unsortedList);
}
带有@Benchmark注解的方法measureCollectionsSortAverageWorstCase接受一个基准状态实例,并使用Collections.sort()方法评估算法在对大量无序列表排序时的性能。
现在,让我们看一个针对最佳情况的类似基准,即数组已经排序的情况:
@State(Scope.Benchmark)
public static class BestCaseBenchmarkState {
List<Integer> sortedList;
@Setup(Level.Trial)
public void setUp() {
sortedList = new ArrayList<>();
for (int i = 1; i <= 1000000; i++) {
sortedList.add(i);
}
}
}
@Benchmark
public void measureCollectionsSortBestCase(BestCaseBenchmarkState state) {
List<Integer> sortedList = new ArrayList<>(state.sortedList);
Collections.sort(sortedList);
}
提供的代码片段引入了一个名为BestCaseBenchmarkState的基准类,它被@State(Benchmark)注解。在这个类的@Setup(Level.Trial)方法中,初始化了一个从1到1,000,000的整数排序列表,创建了一个测试环境。
执行测试后,我们得到以下报告:
Benchmark Mode Cnt Score Error Units
Main.measureCollectionsSortAverageWorstCase avgt 5 36.810 ± 144.15 ms/op
Main.measureCollectionsSortBestCase avgt 5 8.190 ± 7.229 ms/op
基准报告显示,Collections.sort()算法在最佳情况下具有显著较低的平均执行时间,约为每操作8.19毫秒,而在平均和最坏情况下,平均时间为约36.81毫秒/操作,这证实了使用大O符号表示法(Big O notation)所展示的差异。
4. 总结
总的来说,通过Java Microbenchmark Harness(JMH)对Collections.sort()算法的时间复杂性进行考察,确认了它在最佳情况下的时间复杂度为**O(n),在平均和最坏情况下的时间复杂度为O(n log n)**。完整的代码示例可在GitHub上找到:点击这里。