1. 概述
监督学习是机器学习的一个子集,其核心思想是使用带有标签的数据来训练模型。换句话说,就是通过已有经验数据去“教会”模型如何做出预测。
在本教程中,我们将使用 Kotlin 来实践监督学习。我们会介绍两种算法:一个简单的(线性回归),一个复杂的(人工神经网络)。过程中还会讲解如何准备数据集,因为数据质量对模型性能影响巨大。
2. 算法
监督学习模型基于特定的机器学习算法构建。常见的算法有线性回归、支持向量机、决策树、朴素贝叶斯等。
我们先介绍数据集准备,再讲解两个具体算法。
2.1 数据集准备
一个理想的训练数据集应该是带标签的、特征相关性强、数据清洗完整的。但现实往往不理想,所以数据预处理是关键。
以 Wine Quality 数据集为例,原始数据如下:
| Type | Acidity | Dioxide | pH |
|---|---|---|---|
| red | 0.27 | 45 | 3 |
| white | 0.3 | 14 | 3.26 |
| 0.18 | 3.22 | ||
| red | 0.26 | 16 | 3.17 |
我们做了以下处理:
✅ 删除缺失“Type”字段的行(该字段重要)
✅ 数值缺失用该列均值填充(如 Dioxide 缺失填 31)
✅ 将“Type”字段转为数值(red=0, white=1)
✅ 对数值型特征进行 Min-Max 归一化(缩放到 [0,1])
处理后数据如下:
| Type | Acidity | Dioxide | pH |
|---|---|---|---|
| 0 | 0.75 | 0.94 | 0.07 |
| 1 | 1 | 0 | 1 |
| 1 | 0 | 0.52 | 0.86 |
| 0 | 0.67 | 0.06 | 0.68 |
2.2 模型
模型是将输入数据映射到输出结果的算法。模型训练过程中会调整参数(parameters)以优化输出。此外,还需要在训练前设置超参数(hyperparameters),如神经元数量、激活函数、损失函数等。
例如,人工神经网络模型结构如下图所示:
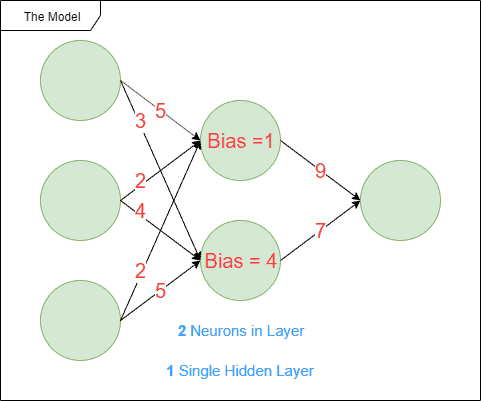
- 红色数字表示模型参数(训练过程中自动调整)
- 蓝色数字表示超参数(手动设置)
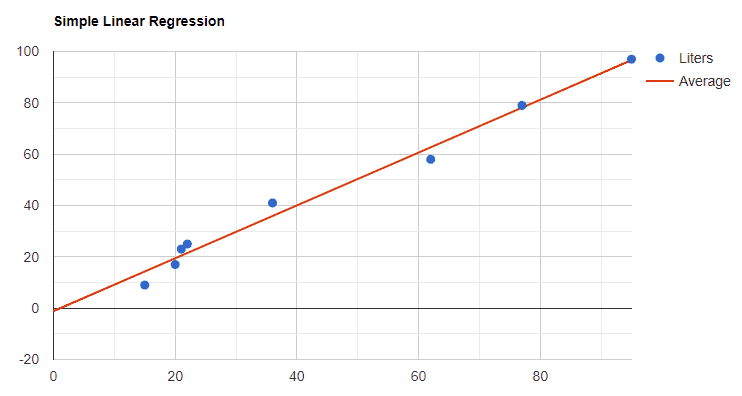
2.3 线性回归
线性回归是一种基础的监督学习算法,用于预测连续值输出。
常见变体:
- 简单线性回归:一个输入变量预测一个输出(如:用房屋面积预测房价)
- 多元线性回归:多个输入变量预测一个输出(如:面积、房间数、位置等预测房价)
- 多项式回归:输出随输入呈非线性变化(如:房价随面积呈指数增长)
- 广义线性模型:预测多个输出变量
示意图如下:
2.4 人工神经网络(ANN)
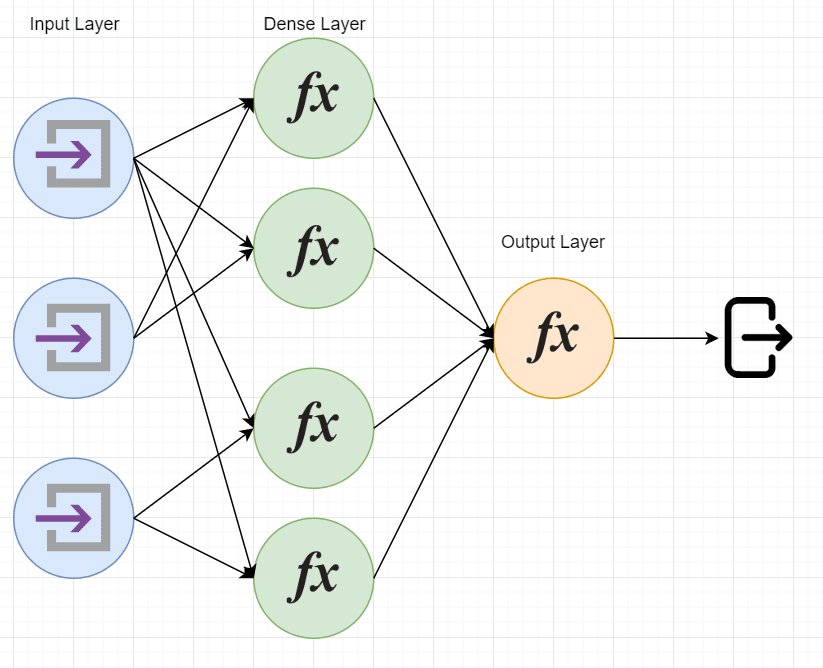
人工神经网络是一种更复杂的监督学习算法,适合解决图像识别、语音识别、自然语言处理等任务。
结构包括:
- 输入层
- 隐藏层(多个神经元组成)
- 输出层
神经元之间通过权重连接,训练过程中通过反向传播(backpropagation)调整这些权重以降低损失函数,提高模型精度。
结构示意图如下:
3. 使用 Kotlin 实现线性回归
我们以“工作经验与薪资”为例,实现一个简单的线性回归模型。
3.1 公式
线性回归公式如下:
# 方差
variance = sum((x - meanX)^2)
# 协方差
covariance = sum((x - meanX) * (y - meanY))
# 斜率
slope = covariance / variance
# 截距
yIntercept = meanY - slope * meanX
# 预测公式
dependentVariable = slope * independentVariable + yIntercept
3.2 Kotlin 实现
val xs = arrayListOf(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val ys = arrayListOf(25, 35, 49, 60, 75, 90, 115, 130, 150, 200)
val variance = xs.sumByDouble { x -> (x - xs.average()).pow(2) }
val covariance = xs.zip(ys) { x, y -> (x - xs.average()) * (y - ys.average()) }.sum()
val slope = covariance / variance
val yIntercept = ys.average() - slope * xs.average()
val simpleLinearRegression = { x: Int -> slope * x + yIntercept }
3.3 模型评估
我们使用 R² 评估模型效果:
# SST
sst = sum((y - meanY)^2)
# SSR
ssr = sum((y - prediction)^2)
# R²
r² = (sst - ssr) / sst
Kotlin 实现:
val sst = ys.sumByDouble { y -> (y - ys.average()).pow(2) }
val ssr = xs.zip(ys) { x, y -> (y - simpleLinearRegression(x).toDouble()).pow(2) }.sum()
val rsquared = (sst - ssr) / sst
最终 R² = 0.95,说明模型拟合效果非常好。
4. 使用 Deeplearning4j 实现图像分类
我们使用 Zalando MNIST 数据集(服装图片)训练一个卷积神经网络(CNN)进行分类。
4.1 Maven 依赖
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>1.0.0-beta5</version>
</dependency>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-native-platform</artifactId>
<version>1.0.0-beta5</version>
</dependency>
4.2 加载数据集
private const val OFFSET_SIZE = 4
private const val NUM_ITEMS_OFFSET = 4
private const val ITEMS_SIZE = 4
private const val ROWS = 28
private const val COLUMNS = 28
private const val IMAGE_OFFSET = 16
private const val IMAGE_SIZE = ROWS * COLUMNS
fun getDataSet(): MutableList<List<String>> {
val labelsFile = File("train-labels-idx1-ubyte")
val imagesFile = File("train-images-idx3-ubyte")
val labelBytes = labelsFile.readBytes()
val imageBytes = imagesFile.readBytes()
val byteLabelCount = Arrays.copyOfRange(labelBytes, NUM_ITEMS_OFFSET, NUM_ITEMS_OFFSET + ITEMS_SIZE)
val numberOfLabels = ByteBuffer.wrap(byteLabelCount).int
val list = mutableListOf<List<String>>()
for (i in 0 until numberOfLabels) {
val label = labelBytes[OFFSET_SIZE + ITEMS_SIZE + i]
val startBoundary = i * IMAGE_SIZE + IMAGE_OFFSET
val endBoundary = i * IMAGE_SIZE + IMAGE_OFFSET + IMAGE_SIZE
val imageData = Arrays.copyOfRange(imageBytes, startBoundary, endBoundary)
val imageDataList = imageData.map { it.toString() }.toMutableList()
imageDataList.add(label.toString())
list.add(imageDataList)
}
return list
}
4.3 构建 CNN 模型
private fun buildCNN(): MultiLayerNetwork {
val multiLayerNetwork = MultiLayerNetwork(NeuralNetConfiguration.Builder()
.seed(123)
.l2(0.0005)
.updater(Adam())
.weightInit(WeightInit.XAVIER)
.list()
.layer(0, buildInitialConvolutionLayer())
.layer(1, buildBatchNormalizationLayer())
.layer(2, buildPoolingLayer())
.layer(3, buildConvolutionLayer())
.layer(4, buildBatchNormalizationLayer())
.layer(5, buildPoolingLayer())
.layer(6, buildDenseLayer())
.layer(7, buildBatchNormalizationLayer())
.layer(8, buildDenseLayer())
.layer(9, buildOutputLayer())
.setInputType(InputType.convolutionalFlat(28, 28, 1))
.backprop(true)
.build())
multiLayerNetwork.init()
return multiLayerNetwork
}
4.4 训练模型
private fun learning(cnn: MultiLayerNetwork, trainSet: RecordReaderDataSetIterator) {
for (i in 0 until 10) {
cnn.fit(trainSet)
}
}
4.5 测试模型
private fun testing(cnn: MultiLayerNetwork, testSet: RecordReaderDataSetIterator) {
val evaluation = Evaluation(10)
while (testSet.hasNext()) {
val next = testSet.next()
val output = cnn.output(next.features)
evaluation.eval(next.labels, output)
}
println(evaluation.stats())
println(evaluation.confusionToString())
}
4.6 运行流程
val dataset = getDataSet()
dataset.shuffle()
val trainDatasetIterator = createDatasetIterator(dataset.subList(0, 50_000))
val testDatasetIterator = createDatasetIterator(dataset.subList(50_000, 60_000))
val cnn = buildCNN()
learning(cnn, trainDatasetIterator)
testing(cnn, testDatasetIterator)
4.7 测试结果
训练后模型表现如下:
==========================Scores========================================
# of classes: 10
Accuracy: 0.8609
Precision: 0.8604
Recall: 0.8623
F1 Score: 0.8608
========================================================================
Predicted: 0 1 2 3 4 5 6 7 8 9
Actual:
0 0 | 855 3 15 33 7 0 60 0 8 0
1 1 | 3 934 2 32 2 0 5 0 2 0
2 2 | 16 2 805 8 92 1 59 0 7 0
3 3 | 17 19 4 936 38 0 32 0 1 0
4 4 | 5 5 90 35 791 0 109 0 9 0
5 5 | 0 0 0 0 0 971 0 25 0 22
6 6 | 156 8 105 36 83 0 611 0 16 0
7 7 | 0 0 0 0 0 85 0 879 1 23
8 8 | 5 2 1 6 2 5 8 1 889 2
9 9 | 0 0 0 0 0 18 0 60 0 938
准确率 86%,说明模型在图像分类任务中表现良好。
5. 总结
本文介绍了如何在 Kotlin 中使用监督学习算法进行建模:
- 使用线性回归实现了简单预测模型
- 使用 Deeplearning4j 构建并训练了 CNN 图像分类器
- 展示了数据预处理、模型构建、训练和评估的完整流程
完整源码可在 GitHub 获取。