1. Overview
Non-ASCII characters are those that are not encoded in ASCII, such as Unicode, EBCDIC, etc. ASCII is limited to 128 characters and was initially developed for the English language.
In this tutorial, we’ll look at some tools to find and highlight non-ASCII characters within text files.
2. Setup
Let’s create a file sample.txt with multiple lines and non-ASCII characters in some lines:
$ cat >> sample.txt
This is an article on finding non-ASCII characters on Baeldung
日本人 中國的 ~=[]()%+{}@;’#!$_&- éè ;∞¥₤€
We hopè you find it inform@tiv€
Thank You!
We’ll use this as the sample file throughout the tutorial.
3. Using grep
grep stands for global regular expression print. It searches for particular patterns of characters in the input and outputs all lines that match.
The grep command has different variants. It is available on almost every Linux distribution system by default. Here, we’ll focus on the most widely used GNU grep.
We can use this command to find all non-ASCII characters:
$ grep --color='auto' -P -n "[\x80-\xFF]" sample.txt
Now, let’s understand this command by breaking it down:
- –color=’auto’: specifies when parts of the matched pattern should be colored. The ‘auto’ value highlights matching strings if the output is written directly to the terminal. Other options include ‘always’, ‘never’, ‘tty’, etc.
- -P: interprets patterns as Perl-compatible regular expressions
- -n: displays each matched line with a line number
- “[\x80-\xFF]”: regular expression that matches characters that are not within the ASCII range
Depending on our system settings, the above command may not work. It’ll only display some of the non-ASCII characters present. An alternative is to grep the inverse of this command, which works more effectively:
$ grep --color='auto' -P -n "[^\x00-\x7F]" sample.txt
Or, we can grep the inverse using character classes:
$ grep --color='auto' -n "[^[:ascii:]]" sample.txt
Here’s the response we get: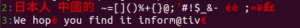
This command only displays lines containing non-ASCII characters. Additionally, it highlights non-ASCII characters in red.
We’ve used “[^\x00-\x7F]” and “[^[:ASCII:]]” as regular expressions. They match the inverse of all characters within the ASCII range.
4. Using pcregrep
pcregrep is a utility for performing file searches for specific character patterns. It utilizes the PCRE regular expressions library to support specific patterns compatible with Perl 5. We can install it through the package manager.
Let’s use this command to install on Debian, Ubuntu, or Kali distributions:
$ sudo apt install pcregrep
On the Red Hat distribution, we can use yum:
$ yum install pcregrep
Next, let’s use pcregrep to check for non-ASCII characters in our sample.txt file:
$ pcregrep --color='auto' -n "[\x80-\xFF]" sample.txt
Alternatively, we can use character classes:
$ pcregrep --color='auto' -n "[^[:ascii:]]" sample.txt
We get this output:
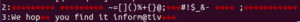
Here is a breakdown of the command:
- –color=”auto”: specifies when parts of the matched pattern should be colored
- -n: displays each matched line with a line number
- “[\x80-\xFF]”: regular expression that matches any character range outside ASCII format
We can see in the output that all non-ASCII characters have been replaced and highlighted with a red color.
5. Using perl
perl was originally built for scanning, extracting, and printing information in arbitrary text files.
It has grown into a general-purpose programming language widely used for many system management tasks.
perl is available by default on most Linux distributions. If it’s missing, we can install it:
$ sudo apt-get install perl
Next, let’s find non-ASCII characters using perl:
$ perl -ne 'print if /[^[:ascii:]]/' sample.txt
日本人 中國的 ~=[]()%+{}@;’#!$_&- éè ;∞¥₤€
We hopè you find it inform@tiv€
By default, the command above displays only lines that contain non-ASCII characters.
Let’s breakdown the command to understand it:
- -ne: two combined flags (-n and -e) that create a new line and execute the print command respectively
- ‘print if…’: a small program that prints all non-ASCII characters
- /[^[:ascii]]/: regular expression matching any non-ASCII character
6. Using tr
We can use the tr or translate command to translate or delete specific characters. It comes pre-installed in all the major Linux distributions.
tr allows us to perform text transformations such as uppercase to lowercase, deleting specific character patterns, etc.
Let’s use it to delete all the ASCII characters in our sample file:
$ tr -d '[:print:]' < sample.txt
日本人中國的’éè∞¥₤€
è€
We’ve used the -d flag to delete all ASCII characters. We also used [:print:]’ to match all printable ASCII characters.
The command above deletes all ASCII characters present. It only prints non-ASCII characters that weren’t deleted.
7. Using sed
sed is used to perform different functions like search, find and replace, etc. on files. It lets us edit files quickly from the command line without even opening them.
Let’s find all non-ASCII characters using sed:
$ LC_ALL=C sed -i 's/[^\x0-\xB1]//g' sample.txt
Now, let’s understand each part of the command:
- LC_ALL=C: environment variable that overrides all other localization settings. Here, we’ve set it to the simplest C setting.
- -i: used to edit the file in-place without opening it
- ‘s/[^\…’: regular expression that matches all non-ASCII characters
The command above edits our original input file. It is advisable to create a copy of the input file before running the command.
By default, the command above will not display any output. We can use the cat command to inspect the changes:
$ cat sample.txt
This is an article on finding non-ASCII characters on Baeldung
���� ����� ~=[]()%+{}@;��#!$_&- �� ;�������
We hop� you find it inform@tiv��
We can also use this sed command to highlight non-ASCII characters:
$ sed -n 'l' sample.txt
This is an article on finding non-ASCII characters on Baeldung$
\346\227\245\346\234\254\344\272\272 \344\270\255\345\234\213\347\232\
\204 ~=[]()%+{}@;\342\200\231#!$_&- \303\251\303\250 ;\342\210\236\
...truncated
This command replaces every occurrence of a non-ASCII character with its octal value.
8. Conclusion
In this article, we’ve learned about non-ASCII characters. We also discussed different tools that we can use to find non-ASCII characters within text files.