1. Overview
In this tutorial, we’ll learn a few advanced techniques for using sed to search and replace text that contains multiple lines.
2. Nested Reads
By default, when sed reads a line in the pattern space, it discards the terminating newline (\n) character. Nevertheless, we can handle multi-line strings by doing nested reads for every newline.
2.1. Pattern Space as Sliding Window
Before we explore the technique of nested reads, let’s visualize the pattern space as a sliding window:
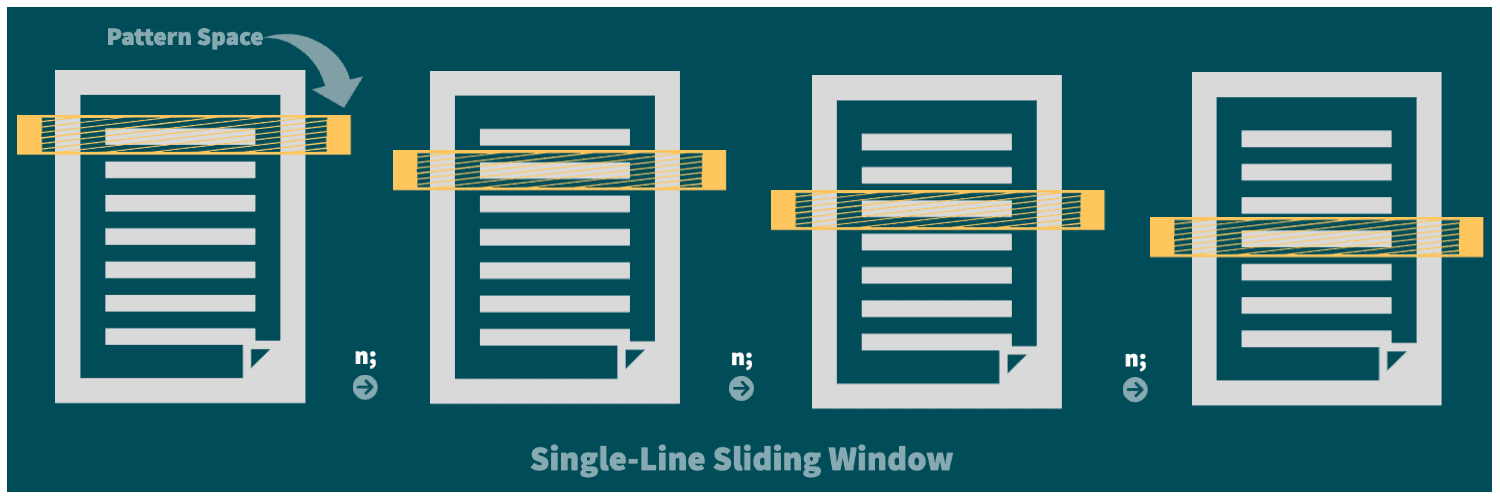
We can notice that with each explicit or implicit use of the n command, the pattern space window slides down by a single line.
2.2. Two-Level Nesting
Let’s imagine that we have an employee database, emp-db.txt, that contains the employees’ first name and department information:
$ cat emp-db.txt
Name: Alex
Department: Tech
Name: Richard
Department: Finance
Name: Alex
Department: Analytics
An employee named Alex has recently moved from the Tech team to the Product team. So, we need to change this detail in the employee database.
Now, as there can be multiple employees with the same first name, we need to match both the details before making any change. And, in sed, we can do this by doing a two-level nested read:
$ cat nested-read.sed
/Alex/ {
p;
n;
/Tech/ {
s/Tech/Product/;
p;
d;
}
}
p;
We achieve nesting by enclosing the commands within the curly braces {}. After matching the first name attribute, we slide the pattern space window by a single line. And then, we match the department name attribute before making the substitution.
Next, when a substitution is made, we can clear the pattern space and restart the read-cycle with the d command. By doing so, we’re able to avoid duplicate printing by the print (p) command on the last line.
So, let’s go ahead and verify that our nested-read.sed script is working as expected:
$ sed -n -f nested-read.sed emp-db.txt
Name: Alex
Department: Product
Name: Richard
Department: Finance
Name: Alex
Department: Analytics
We can see that our script works fine for this use case. However, the level of nesting depends on the number of lines in our search string. Therefore, our code will become less readable and more error-prone as the number of lines in the search pattern increases.
3. Multi-Line Fast Sliding Window
The limitations of nested-reads are best solved by using a set of more sophisticated multi-line compatible commands. With these techniques, we can fit more than one line in the pattern space, each separated by a newline. Let’s understand this by editing non-overlapping structured data in a file.
3.1. Non-Overlapping Records
Now, let’s take another version of the emp-db.txt employee database viewed as a collection of non-overlapping records, each having three attributes, namely Name, Department, and EmpId:
$ sed '' emp-db.txt
Name: Alex
Department: Tech
EmpId: 100
Name: George
Department: HR
EmpId: 500
This time, we’re required to change the Department attribute of an employee with EmpId=500 to Finance.
3.2. sed Script
If we were to write our sed script using the nested-read technique, that would require three levels of nesting. So, instead, we’ll use a relatively better method of a multi-line fast sliding window.
This technique is a read-edit cycle comprising three steps:
- Initialize a fixed-size multi-line pattern space window
- Make edits to the record
- Slide the window by lines equal to the size of the window
First, let’s start writing our emp.sed script by growing the pattern space window from the default single-line window to a three-line window:
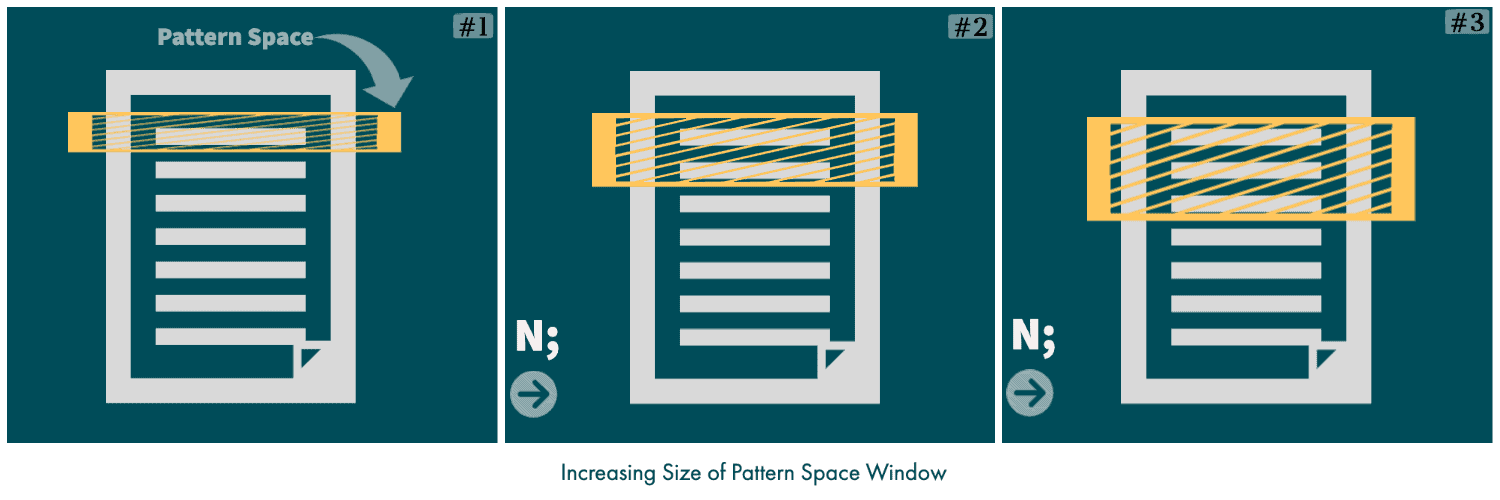
Also, we have to increase the window size by two lines, so we can invoke the N command twice:
$ sed -n '1,2p' emp.sed
N;
N;
Now, we have a complete employee record in the pattern space. So, we can search and replace using the substitution (s) command:

With new lines available in the pattern space, we can use the \n character as part of the regex. Moreover, we can use the \1, \2, and \3 to back-reference the substitution groups:
$ sed -n '3,4p' emp.sed
s/(.*\n)(.*: ).*(\n.*: 500)/\1\2Finance\3/;
p;
Finally, we can slide the pattern space window by using the d command at the end of the current read-cycle, followed by two invocations of the N command in the next read-cycle:
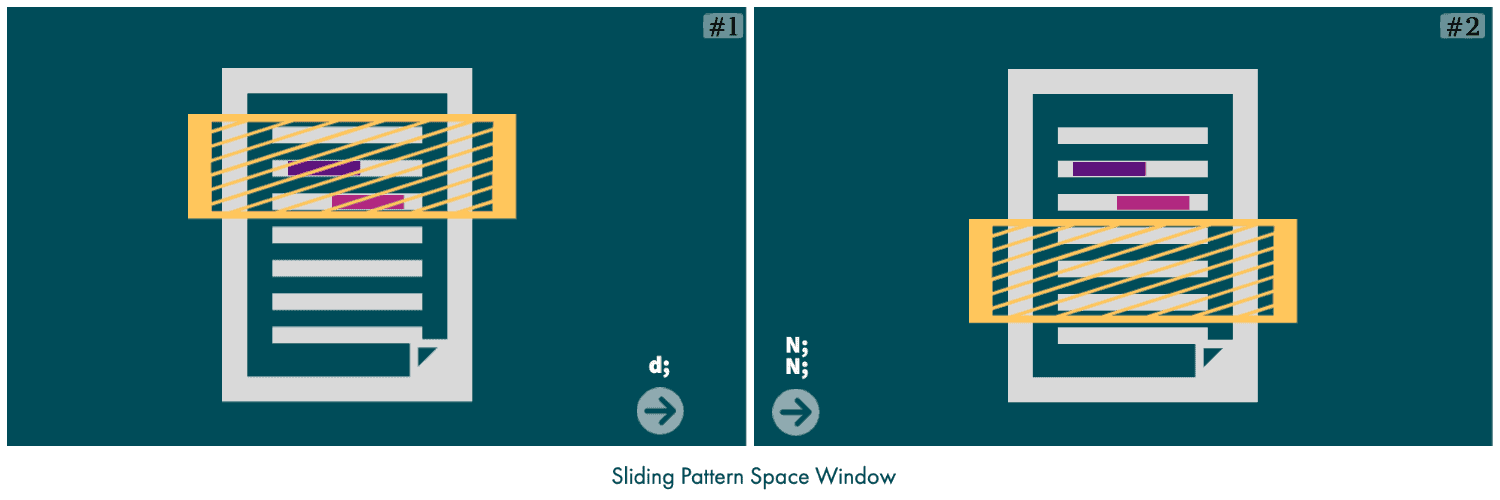
$ sed -n '$p' emp.sed
d;
This way, the read-cycles will continue until there are no more employee records to read.
3.3. Editing in Action
Before we execute our script, let’s see our emp.sed script in its entirety:
$ sed '' emp.sed
N;
N;
s/(.*\n)(.*: ).*(\n.*: 500)/\1\2Finance\3/;
p;
d;
Finally, let’s run this script:
$ sed -E -n -f emp.sed emp-db.txt
Name: Alex
Department: Tech
EmpId: 100
Name: George
Department: Finance
EmpId: 500
As expected, the Department attribute of the employee with EmpId as 500 is changed to Finance.
4. Multi-Line Slow Sliding Window
In this section, we’ll explore a variant of the multi-line pattern space window technique where the window slides by one line at a time.
4.1. Overlapping Records
Let’s say that we have to attend a two-day workshop. To evaluate the best time to attend the course, we’re interested in finding out all possible start days by processing the workshop’s calendar data:
$ sed '' workshop_calendar.txt
Day-1:0
Day-2:1
Day-3:1
Day-4:1
Day-5:0
Day-6:1
Day-7:1
As such, a day is marked as 0 or 1 in the workshop_calendar.txt file to indicate whether the workshop runs on that day or not. So, if we think about the problem, we need to get the first day out of each possible two-day running streak of the workshop.
With that perspective, each possible pair of two consecutive lines is a record that we need to process. Moreover, these records are overlapping in nature.
4.2. Sliding Window Using D and N
Like in the case of the fast sliding window, editing using this technique begins by initializing the pattern space with a size equal to that of the record:
$ sed -n '1p' workshop.sed
N;
For this case, we need to increase the size of the pattern space from the default single-line window to two lines. So, a single invocation of the N command will do the job.
However, when it comes to the second stage, where we perform the main editing operation, it gets a bit tricky. That’s because the records are overlapping, and if we change a record directly, our reads for the next window will be disturbed.
To solve this issue, we first hold a copy of the pattern space into the hold space, then make changes to the contents of the pattern space. After we print the edited version of pattern space, the original copy can be restored from the hold space, and the next cycle can continue from there:
$ sed -n -e '1! {$!p;}' workshop.sed
/.*:1\n.*:1/ {
h;
s/(.*):1(\n.*:1)/\1/p;
g;
}
We must note that 1! {$!p;} prints all lines of our script except the first and the last.
Next, we can slide the pattern space window by deleting the first line with the D command and appending the next line in the next read-cycle using the N command:
$ sed -n '$p' workshop.sed
D;
To get more clarity, let’s visualize the slow sliding of the pattern space window:
Our script is ready:
$ sed '' workshop.sed
N;
/.*:1\n.*:1/ {
h;
s/(.*):1(\n.*:1)/\1/p;
g;
}
D;
Finally, let’s execute it and get the desired data:
$ sed -E -n -f workshop.sed workshop_calendar.txt
Day-2
Day-3
Day-6
5. Gobbling
Theoretically speaking, there’s no upper bound on the window size of the pattern space. When the size of the file is small, we can practically afford to load the entire file into the pattern space to replace a multi-line string. So, let’s learn this technique of gobbling to solve a few use cases.
5.1. Reverse Order of Lines
Let’s imagine that we have an enumerated list of employees in the employees.txt file:
$ sed -n '' employees.txt
e9
e2
e3
e4
e8
e6
e7
e1
e5
Now, we’re required to reverse the order of lines in the file. For this, we can think of the entire content of the file as a single multi-line string, and we need to replace it by its reverse counterpart.
By using a combination of G and h commands, we can effectively simulate a stack-like first-in-first-out functionality for the hold space. And, at the end of each cycle, pattern space and hold space will have the same content:
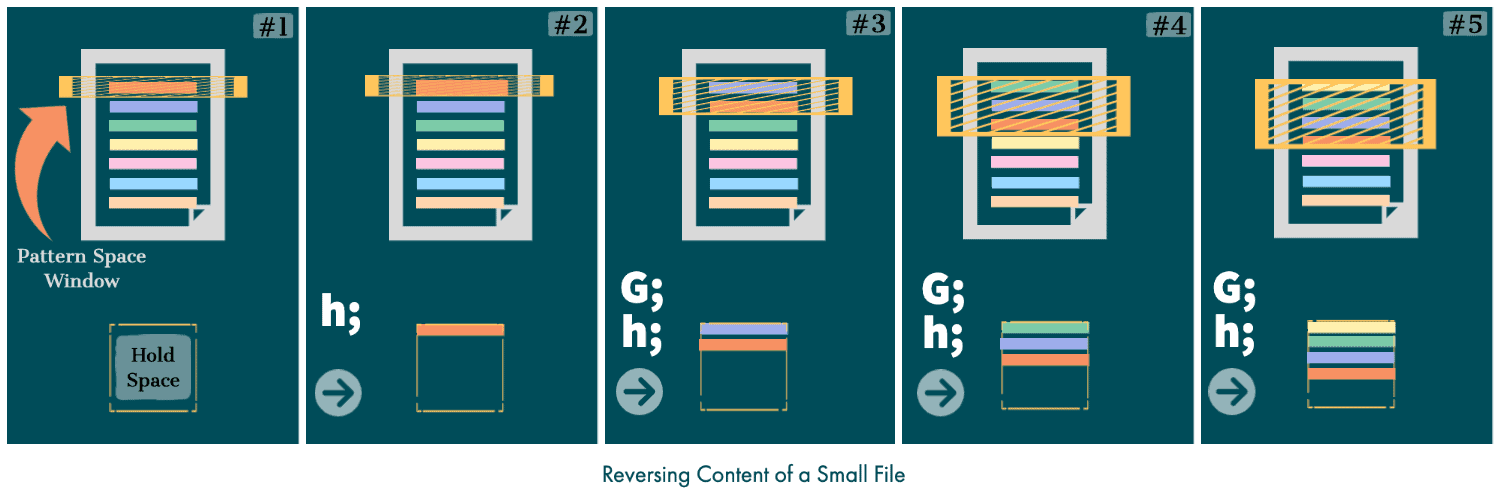
So, let’s translate this logic into our reverse.sed script:
$ sed '' reverse.sed
1 {
h;
};
2,$ {
G;
h;
}
$p;
We must note that as the hold space is initially empty, we don’t need to invoke the G command for the first read-cycle. And, towards the end of the last read-cycle, we can print the pattern space to give out the reversed order of lines.
With our script in place, let’s execute it to see it in action:
$ sed -n -f reverse.sed employees.txt
e5
e1
e7
e6
e8
e4
e3
e2
e9
Perfect! It’s exactly what we need.
6. Mapping Data Between Two Files
To replace multi-line text using data from two files, we can use a two-phase strategy that gobbles the smaller file and use a sliding window strategy for the bigger file. Let’s see this in practice.
6.1. Two-Phase Strategy
Let’s assume that we have a list of projects in the projects.txt file, and we’re required to assign each project to a team of three employees from the employees.txt file:
$ sed '' projects.txt
p1
p2
p3
To solve this use case, let’s make effective use of the hold space and the pattern space with a two-phase strategy:
- Gobble the smaller projects.txt file into the hold space
- Use fast sliding window strategy for replacing text in the employees.txt file
6.2. Gobble
In the first phase, let’s load the projects.txt file into the hold space:
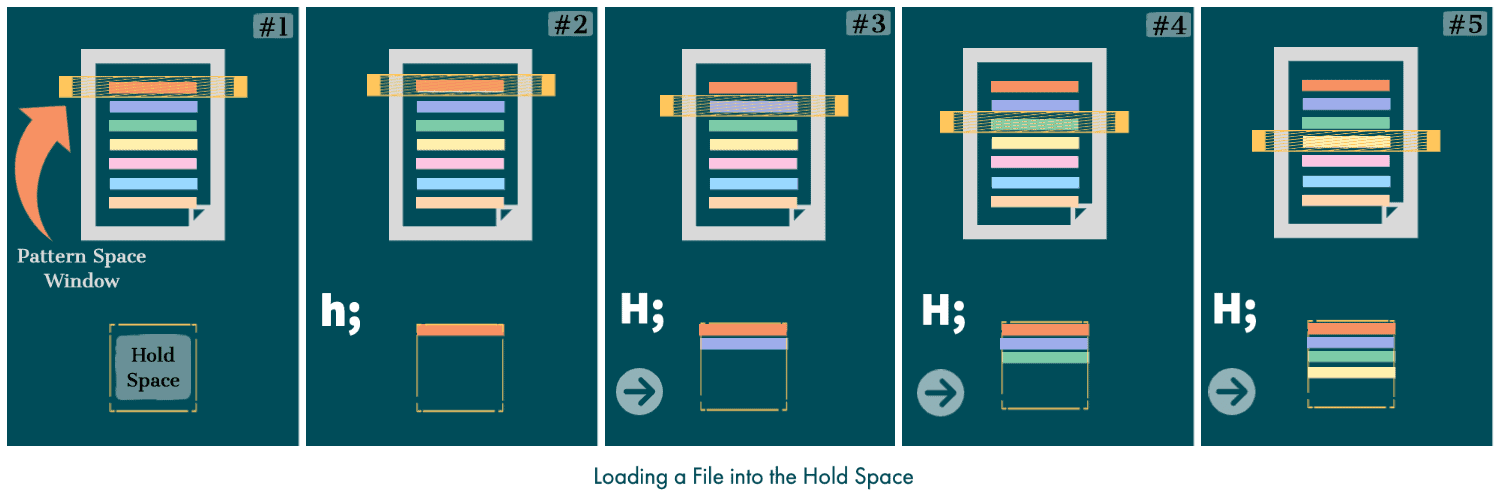
For the first read-cycle, we can use the h command, and after that, we can use the H command. Doing this will ensure that the newline character separates the individual lines in the hold space:
$ sed -n '1,5p' mapping.sed
/^p[0-9]+/ {
1h;
2,$H;
$d;
}
We must note the use of single-level nesting because we want these commands to execute only for content from the projects.txt file. And, towards the end of the last read-cycle, we clear the pattern space so that we can use it to read the second file.
6.3. Sliding Window
In the second phase, let’s use the fast sliding window approach for the employees.txt file. During each read-cycle, the pattern space window size will be three lines.
Let’s look at the snippet of our mapping.sed script that is primarily responsible for reading and editing the employees.txt file:
$ sed -n '7,18p' mapping.sed
/^e[0-9]+/ {
N;
N;
s/\n/,/g;
s/.*/(&)/;
P;
x;
P;
s/^[^\n]*\n//;
x;
D;
}
As the main editing logic in the sliding window technique lies in the middle, let’s break that down to understand it more clearly:
- The first substitution s/\n/,/g separates employee names in each group with a comma
- The second substitution s/.*/(&)/ encloses each group within parentheses
- Using the P command, we print the first line from the pattern space
- With the x command, we exchange contents between the pattern space and hold space
- The third substitution s/^[^\n]*\n// removes the first line from the pattern space within the same read-cycle
6.4. Mapping
Finally, let’s execute our mapping.sed script with projects.txt and employees.txt as the first and second input file, respectively:
$ sed -E -n -f mapping.sed projects.txt employees.txt
(e9,e2,e3)
p1
(e4,e8,e6)
p3
(e7,e1,e5)
p3
So, we can see that each group contains a set of three employees. And, the immediate line in the output shows the project assigned to that group.
7. Conclusion
In this tutorial, we developed a clear understanding of how we can use sed to search and replace multi-line strings. In the process, we explored a few sophisticated multi-line compatible sed commands such as N, H, G, D, and P for solving a few specific multi-line, text-editing use cases.
With this, we have a better grip on this topic, and more hands-on practice would further prepare us to formulate efficient and simplified editing techniques using sed.