1. 简介
本教程将学习如何使用Java MongoDB驱动API实现Atlas Search功能。通过学习,我们将掌握创建查询、分页结果和获取元信息的方法,同时涵盖结果过滤、评分调整和字段选择等高级技巧。
2. 场景与环境搭建
MongoDB Atlas提供永久免费集群用于测试所有功能。为展示Atlas Search功能,我们只需一个服务类,通过MongoTemplate连接集合。
2.1. 依赖配置
首先添加spring-boot-starter-data-mongodb依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
<version>3.1.2</version>
</dependency>
2.2. 示例数据集
本教程全程使用MongoDB Atlas的sample_mflix示例数据集中的movies集合简化示例。 该集合包含1900年代至今的电影数据,便于展示Atlas Search的过滤能力。
2.3. 创建动态映射索引
Atlas Search需要索引才能工作,分为静态和动态两种。静态索引适合精细调优,动态索引则是通用解决方案。 我们先创建动态索引。
创建搜索索引有多种方式(包括编程方式),这里使用Atlas UI。操作路径:Search → 选择集群 → Go to Atlas Search:
点击Create Search Index后选择JSON编辑器:
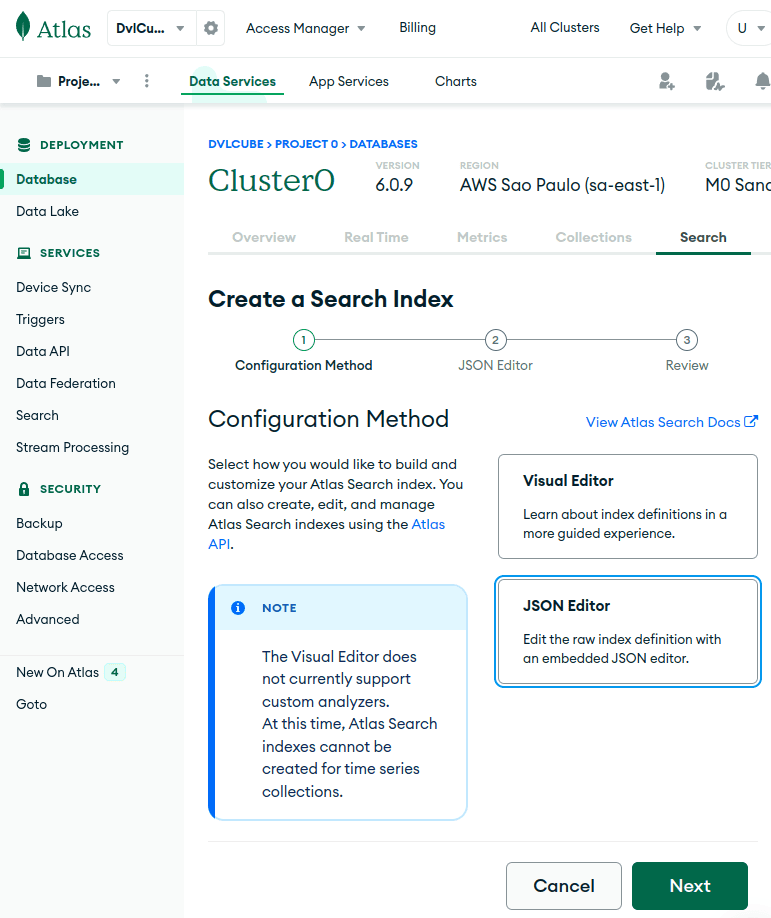
最后选择目标集合、索引名称并输入定义:
{
"mappings": {
"dynamic": true
}
}
本教程索引名称统一使用idx-queries。注意:若索引命名为default,查询时无需指定名称。 动态映射对频繁变更的schema特别友好。
设置mappings.dynamic为true后,Atlas Search会自动索引文档中所有动态索引和支持的字段类型。动态映射虽方便,但比静态索引消耗更多磁盘空间且效率较低。
2.4. 电影搜索服务
基于服务类构建示例,逐步实现复杂查询:
@Service
public class MovieAtlasSearchService {
private final MongoCollection<Document> collection;
public MovieAtlasSearchService(MongoTemplate mongoTemplate) {
MongoDatabase database = mongoTemplate.getDb();
this.collection = database.getCollection("movies");
}
// ...
}
只需保留集合引用供后续方法使用。
3. 构建查询
Atlas Search查询通过管道阶段表示为List
多种搜索操作符定义查询方式。*本例使用SearchOperator.text()通过标签搜索电影,执行全文搜索。* 用SearchPath.fieldPath()指定fullplot字段内容(省略静态导入):
public Collection<Document> moviesByKeywords(String keywords) {
List<Bson> pipeline = Arrays.asList(
search(
text(
fieldPath("fullplot"), keywords
),
searchOptions()
.index("idx-queries")
),
project(fields(
excludeId(),
include("title", "year", "fullplot", "imdb.rating")
))
);
return collection.aggregate(pipeline)
.into(new ArrayList<>());
}
管道第二阶段是Aggregates.project(),表示投影。未指定时返回所有字段,但可自定义返回字段。注意:包含字段会隐式排除其他字段(除_id*外),因此这里显式排除_id并指定所需字段。* 支持嵌套字段如imdb.rating。
调用集合的aggregate()执行管道,返回可迭代结果对象。为简化,调用into()将结果存入集合返回。**⚠️ 大数据集可能导致JVM内存耗尽,后续通过分页解决此问题。
管道阶段顺序至关重要,*将project()置于search()前会报错。*
调用*moviesByKeywords("space cowboy")*的前两条结果:
[
{
"title": "Battle Beyond the Stars",
"fullplot": "Shad, a young farmer, assembles a band of diverse mercenaries in outer space to defend his peaceful planet from the evil tyrant Sador and his armada of aggressors. Among the mercenaries are Space Cowboy, a spacegoing truck driver from Earth; Gelt, a wealthy but experienced assassin looking for a place to hide; and Saint-Exmin, a Valkyrie warrior looking to prove herself in battle.",
"year": 1980,
"imdb": {
"rating": 5.4
}
},
{
"title": "The Nickel Ride",
"fullplot": "Small-time criminal Cooper manages several warehouses in Los Angeles that the mob use to stash their stolen goods. Known as \"the key man\" for the key chain he always keeps on his person that can unlock all the warehouses. Cooper is assigned by the local syndicate to negotiate a deal for a new warehouse because the mob has run out of storage space. However, Cooper's superior Carl gets nervous and decides to have cocky cowboy button man Turner keep an eye on Cooper.",
"year": 1974,
"imdb": {
"rating": 6.7
}
},
(...)
]
3.1. 组合搜索操作符
通过SearchOperator.compound()组合操作符。本例使用must和should子句:*must*包含必须满足的条件,*should*包含优先匹配的条件。
这会调整评分,使满足优先条件的文档靠前:
public Collection<Document> late90sMovies(String keywords) {
List<Bson> pipeline = asList(
search(
compound()
.must(asList(
numberRange(
fieldPath("year"))
.gteLt(1995, 2000)
))
.should(asList(
text(
fieldPath("fullplot"), keywords
)
)),
searchOptions()
.index("idx-queries")
),
project(fields(
excludeId(),
include("title", "year", "fullplot", "imdb.rating")
))
);
return collection.aggregate(pipeline)
.into(new ArrayList<>());
}
保留首个查询的searchOptions()和投影字段,但将text()移至should子句(关键词作为优先条件而非必需)。新增must子句,用SearchOperator.numberRange()限制year字段值,仅返回1995-2000年(不含)的电影。
搜索"hacker assassin"的前两条结果:
[
{
"title": "Assassins",
"fullplot": "Robert Rath is a seasoned hitman who just wants out of the business with no back talk. But, as things go, it ain't so easy. A younger, peppier assassin named Bain is having a field day trying to kill said older assassin. Rath teams up with a computer hacker named Electra to defeat the obsessed Bain.",
"year": 1995,
"imdb": {
"rating": 6.3
}
},
{
"fullplot": "Thomas A. Anderson is a man living two lives. By day he is an average computer programmer and by night a hacker known as Neo. Neo has always questioned his reality, but the truth is far beyond his imagination. Neo finds himself targeted by the police when he is contacted by Morpheus, a legendary computer hacker branded a terrorist by the government. Morpheus awakens Neo to the real world, a ravaged wasteland where most of humanity have been captured by a race of machines that live off of the humans' body heat and electrochemical energy and who imprison their minds within an artificial reality known as the Matrix. As a rebel against the machines, Neo must return to the Matrix and confront the agents: super-powerful computer programs devoted to snuffing out Neo and the entire human rebellion.",
"imdb": {
"rating": 8.7
},
"year": 1999,
"title": "The Matrix"
},
(...)
]
4. 结果集评分
使用search()查询时,结果按计算评分从高到低排序。**修改late90sMovies()方法,接收SearchScore修饰符提升should子句中关键词的相关性:**
public Collection<Document> late90sMovies(String keywords, SearchScore modifier) {
List<Bson> pipeline = asList(
search(
compound()
.must(asList(
numberRange(
fieldPath("year"))
.gteLt(1995, 2000)
))
.should(asList(
text(
fieldPath("fullplot"), keywords
)
.score(modifier)
)),
searchOptions()
.index("idx-queries")
),
project(fields(
excludeId(),
include("title", "year", "fullplot", "imdb.rating"),
metaSearchScore("score")
))
);
return collection.aggregate(pipeline)
.into(new ArrayList<>());
}
在投影中添加metaSearchScore("score")显示每个文档的评分。例如,将"should"子句相关性乘以imdb.votes字段值:
late90sMovies(
"hacker assassin",
SearchScore.boost(fieldPath("imdb.votes"))
)
结果中《黑客帝国》因评分提升排在首位:
[
{
"fullplot": "Thomas A. Anderson is a man living two lives (...)",
"imdb": {
"rating": 8.7
},
"year": 1999,
"title": "The Matrix",
"score": 3967210.0
},
{
"fullplot": "(...) Bond also squares off against Xenia Onatopp, an assassin who uses pleasure as her ultimate weapon.",
"imdb": {
"rating": 7.2
},
"year": 1995,
"title": "GoldenEye",
"score": 462604.46875
},
(...)
]
4.1. 使用评分函数
通过函数实现更精细的评分控制。传递函数将year字段值加到原始评分上,使新电影评分更高:
late90sMovies(keywords, function(
addExpression(asList(
pathExpression(
fieldPath("year"))
.undefined(1),
relevanceExpression()
))
));
代码以SearchScore.function()开头,使用SearchScoreExpression.addExpression()执行加法。**通过SearchScoreExpression.pathExpression()指定year字段,并用undefined()设置缺失时的默认值。 最后调用relevanceExpression()获取文档相关性评分,与year值相加。
执行后《黑客帝国》仍居首位,但评分已更新:
[
{
"fullplot": "Thomas A. Anderson is a man living two lives (...)",
"imdb": {
"rating": 8.7
},
"year": 1999,
"title": "The Matrix",
"score": 2003.67138671875
},
{
"title": "Assassins",
"fullplot": "Robert Rath is a seasoned hitman (...)",
"year": 1995,
"imdb": {
"rating": 6.3
},
"score": 2003.476806640625
},
(...)
]
这对定义评分权重非常有用。
5. 从元数据获取总行数
使用Aggregates.searchMeta()替代search()获取元数据中的总结果数。**此方法不返回文档。 用于统计90年代后期包含关键词的电影数量。
为有效过滤,将keywords加入must子句:
public Document countLate90sMovies(String keywords) {
List<Bson> pipeline = asList(
searchMeta(
compound()
.must(asList(
numberRange(
fieldPath("year"))
.gteLt(1995, 2000),
text(
fieldPath("fullplot"), keywords
)
)),
searchOptions()
.index("idx-queries")
.count(total())
)
);
return collection.aggregate(pipeline)
.first();
}
searchOptions()中调用SearchOptions.count(SearchCount.total())确保获取精确总数(而非下限值)。**因预期返回单个对象,调用first()获取结果。
*countLate90sMovies("hacker assassin")*的返回结果:
{
"count": {
"total": 14
}
}
此方法可在不包含文档的情况下获取集合信息。
6. 结果分面分析
MongoDB Atlas Search的分面功能可获取搜索结果的聚合分类信息。帮助分析不同维度的数据分布。
支持将结果分组到不同类别,获取每类计数或附加信息。可回答"某类别有多少文档?"或"结果中某字段的最常见值是什么?"等问题。
6.1. 创建静态索引
示例将创建分面查询,分析1900年代至今的电影类型及其关系。 需要包含分面类型的索引,动态索引无法满足。
创建新搜索索引idx-facets,保持dynamic为true以支持未显式定义的字段:
{
"mappings": {
"dynamic": true,
"fields": {
"genres": [
{
"type": "stringFacet"
},
{
"type": "string"
}
],
"year": [
{
"type": "numberFacet"
},
{
"type": "number"
}
]
}
}
}
指定映射非完全动态后,为感兴趣的字段创建分面索引。因需在查询中使用过滤器,每个字段需同时指定标准类型(如string)和分面类型(如stringFacet)。
6.2. 执行分面查询
*创建分面查询需使用searchMeta(),通过SearchCollector.facet()定义分面和过滤操作符。* 定义分面时需选择名称,并使用与索引类型匹配的SearchFacet方法。本例定义*stringFacet()和numberFacet()*:
public Document genresThroughTheDecades(String genre) {
List pipeline = asList(
searchMeta(
facet(
text(
fieldPath("genres"), genre
),
asList(
stringFacet("genresFacet",
fieldPath("genres")
).numBuckets(5),
numberFacet("yearFacet",
fieldPath("year"),
asList(1900, 1930, 1960, 1990, 2020)
)
)
),
searchOptions()
.index("idx-facets")
)
);
return collection.aggregate(pipeline)
.first();
}
用text()操作符过滤特定类型电影。**因电影通常含多种类型,stringFacet()将显示按频率排序的5个相关类型(通过numBuckets()指定)。numberFacet()需设置聚合结果的边界值,至少两个且最后一个为开区间。
返回首个结果。按"horror"类型过滤的结果:
{
"count": {
"lowerBound": 1703
},
"facet": {
"genresFacet": {
"buckets": [
{
"_id": "Horror",
"count": 1703
},
{
"_id": "Thriller",
"count": 595
},
{
"_id": "Drama",
"count": 395
},
{
"_id": "Mystery",
"count": 315
},
{
"_id": "Comedy",
"count": 274
}
]
},
"yearFacet": {
"buckets": [
{
"_id": 1900,
"count": 5
},
{
"_id": 1930,
"count": 47
},
{
"_id": 1960,
"count": 409
},
{
"_id": 1990,
"count": 1242
}
]
}
}
}
未指定总数时返回下限计数,后跟分面名称及其分桶。
6.3. 添加分面阶段实现分页
修改late90sMovies()方法,在管道中添加$facet阶段。**用于分页和总行数统计,search()和project()阶段保持不变:
public Document late90sMovies(int skip, int limit, String keywords) {
List<Bson> pipeline = asList(
search(
// ...
),
project(fields(
// ...
)),
facet(
new Facet("rows",
skip(skip),
limit(limit)
),
new Facet("totalRows",
replaceWith("$$SEARCH_META"),
limit(1)
)
)
);
return collection.aggregate(pipeline)
.first();
}
调用Aggregates.facet()接收一个或多个分面。实例化Facet包含Aggregates类的skip()和limit()。*skip*定义偏移量,*limit*限制文档数。分面名称可自定义。**
调用replaceWith("$$SEARCH_META")获取元数据。**为避免元数据重复,添加limit(1)。* 含元数据的查询返回单个文档而非数组,故仅返回首个结果。
7. 结论
本文展示了MongoDB Atlas Search为开发者提供的多功能工具集。结合Java MongoDB驱动API可增强搜索功能、数据聚合和结果定制能力。通过实践示例深入理解其能力,无论是简单搜索还是复杂数据分析,Atlas Search都是MongoDB生态中的宝贵工具。
善用索引、分面和动态映射让数据发挥最大价值。完整源码见GitHub仓库。