概述
Java以其出色的垃圾收集算法而闻名。然而,并不意味着JVM应用中不会发生内存泄漏。获取并分析堆转储是找到应用程序潜在泄漏的第一步。
在本文中,我们将看到如何从运行在Kubernetes容器中的应用程序中获取Java堆转储。
首先,我们将研究什么是堆转储。然后,我们将创建一个小型测试应用程序,稍后将作为Kubernetes容器部署。最后,我们将看到如何从它获取堆转储。
1. 堆转储概览
堆转储是在给定时刻记录JVM应用程序内存中所有对象的快照。
通过查看堆并使用特殊工具进行分析,我们可以定位到对象的创建位置以及在源代码中对这些对象的引用。我们还可以看到随时间变化的内存分配图。
因此,堆转储有助于检测内存泄漏问题并优化JVM应用程序的内存使用。
2. 什么是堆转储
堆转储是在给定时刻记录JVM应用程序内存中所有对象的快照。
通过查看堆并使用特殊工具进行分析,我们可以定位到对象的创建位置以及在源代码中对这些对象的引用。我们还可以看到随时间变化的内存分配图。
因此,堆转储有助于检测内存泄漏问题并优化JVM应用程序的内存使用。
3. 创建测试应用程序
在捕获堆转储之前,我们需要一个在Kubernetes容器中运行的可工作的JVM应用程序。
3.1. 创建长运行应用程序
让我们创建一个简单的程序,用于在指定范围内搜索质数,我们称之为prime-number-finder。
我们的小型应用程序由一个*main()方法和一个isPrime()*方法组成,用于执行粗力质数检测:
public static void main(String[] args) {
List<Integer> primes = new ArrayList<>();
int maxNumber = Integer.MAX_VALUE; // set to huge to make it run a long time
for (int i = 2; i < maxNumber; i++) {
if (isPrime(i)) {
System.out.println(i);
primes.add(i);
}
}
}
private static boolean isPrime(int number) {
return IntStream.rangeClosed(2, (int) (Math.sqrt(number)))
.allMatch(n -> number % n != 0);
}
接下来的事情是将我们的代码编译成一个jar文件。它将被命名为prime-number-finder.jar并将位于target目录中。
3.2. 将应用程序容器化以供Kubernetes使用
为了能够将其部署到Kubernetes堆栈中,让我们创建一个dockerfile:
FROM adoptopenjdk:11-jre-hotspot
COPY target/prime-number-finder.jar application.jar
ENTRYPOINT ["java", "-jar", "application.jar"]
我们将构建的jar文件复制到容器中并使用标准的java -jar命令运行它。
下一步是我们需要一个名为prime-deploy.yaml的Kubernetes部署文件,该文件指定了如何将我们的应用程序部署到Kubernetes堆栈中:
apiVersion: v1
kind: Pod
metadata:
name: prime-number-finder-pod
spec:
containers:
- name: prime-number-finder
image: baeldung/prime-number:latest
最后我们需要做的事情是将它部署到Kubernetes:
$ kubectl apply -f prime-deploy.yaml
我们可以使用kubectl get pods命令来检查部署是否成功:
NAME READY STATUS RESTARTS AGE IP NODE
prime-number-finder-pod 1/1 Running 0 1m 172.17.0.3 minikube
4. 获取堆转储
首先我们需要做的事情是获取正在运行的容器的名称。我们可以在上一章的kubectl get pods命令中获取它。在我们的例子中,它是prime-number-finder-pod。
下一步是使用那个名称进入正在运行的容器。我们将使用Kubernetes的exec命令来完成这个任务:
$ kubectl exec -it prime-number-finder-pod bash
现在我们需要获取运行中的JVM应用程序的进程ID。我们可以使用内置在JDK中的jps命令。
下一步是创建堆转储。再次,我们将使用内置的JDK工具:
$ jmap -dump:live,format=b,file=prime_number_heap_dump.bin <process_id>
最后我们需要做的事情是将新创建的堆转储从容器复制到本地机器:
$ kubectl cp prime-number-finder-pod:prime_number_heap_dump.bin <our local destination directory>
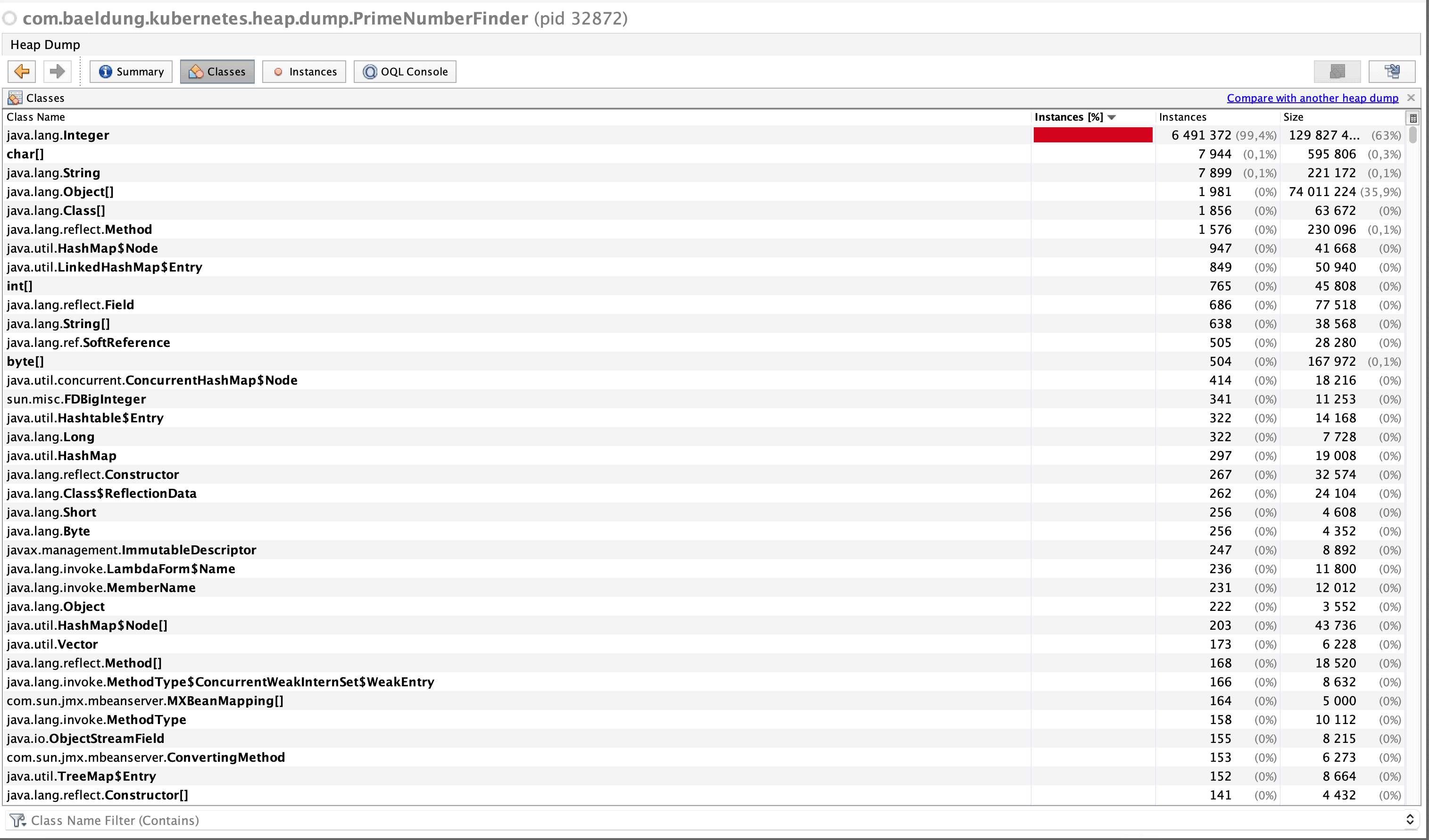
现在,我们可以使用任何内存分析工具,如JvisualVM(JDK提供的)或第三方应用程序(如JProfiler或JStack Review),来分析堆转储。
这是10分钟质数应用程序的堆转储在JvisualVM中的分析结果:
5. 结论
在这篇文章中,我们学习了如何从Kubernetes容器中获取Java堆转储。
首先,我们理解了堆转储的概念及其用途。然后,我们创建了一个简单的质数查找应用程序并将其部署到了Kubernetes。
最后,我们展示了如何登录到运行中的容器,创建堆转储并将其复制到本地机器。
正如往常一样,文章的完整源代码在GitHub上可用在此处查看。