1. Jenkins Pipeline 中的 Agent 与 Node:概念与区别
在使用 Jenkins 实现 CI/CD 流程时,Pipeline 是一个非常关键的组件。它以代码的形式定义整个构建、测试和部署流程。在 Pipeline 的配置中,我们经常会遇到两个术语:Agent 和 Node。
虽然这两个词在中文中都可能被翻译为“代理”或“节点”,但在 Jenkins 的上下文中,它们代表了不同的概念,理解它们的区别对于写出高效、可控的 Pipeline 非常重要。
2. Jenkins Pipeline 基础结构
Jenkins Pipeline 是一系列自动化的步骤,用于构建、测试和部署应用程序。它通常由以下几个核心组件构成:
- Stages:代表整个流程的不同阶段,如构建、测试、部署等。
- Steps:每个阶段中执行的具体操作。
- Agent:指定 Pipeline 或某个 Stage 应该在哪台机器上执行。
- Node:代表 Jenkins 架构中实际执行任务的机器(可以是物理机、虚拟机或容器)。
以下是一个典型的 Jenkins Pipeline 流程图,展示了从代码拉取到部署的全过程:
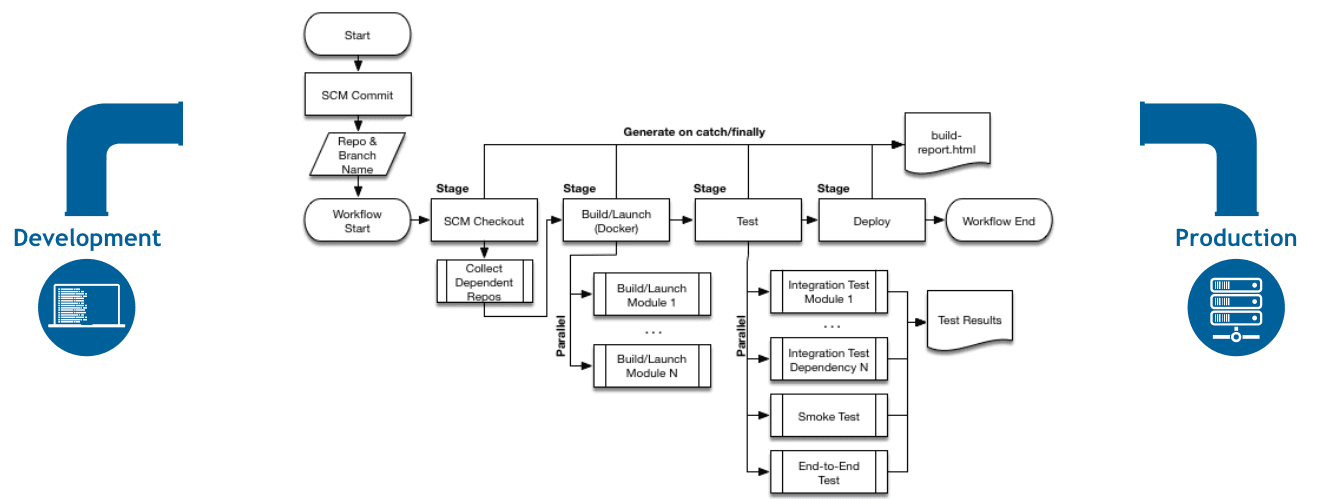
3. Agent 是什么?
Agent 用于指定整个 Pipeline 或其中某个 Stage 的执行环境。它可以是一个具体的机器、一个标签组,也可以是一个 Docker 容器。
Agent 的作用范围可以是全局(整个 Pipeline)或局部(某个 Stage)。
示例代码:
pipeline {
agent any
stages {
stage('Build') {
steps {
echo 'Building...'
}
}
stage('Test') {
agent {
label 'test-node'
}
steps {
echo 'Testing...'
}
}
}
}
在这个例子中:
agent any表示整个 Pipeline 可以运行在任何可用的节点上;Test阶段中的agent指定了必须运行在标签为test-node的节点上。
常见的 Agent 类型:
| 类型 | 含义 |
|---|---|
any |
可运行在任意可用节点上 |
label |
运行在指定标签的节点上 |
docker |
在指定的 Docker 容器中运行 |
none |
不指定全局 Agent,需在每个 Stage 中单独指定 |
4. Node 是什么?
Node 是 Jenkins 架构中实际执行任务的机器,它可以是 Jenkins Master 的 Slave,也可以是临时启动的 Docker 容器。
Node 的定义通常是通过 Agent 来实现的,但在某些场景下,我们也可以在 script 块中显式地使用 node 关键字来指定某个步骤的执行节点。
示例代码:
pipeline {
agent none
stages {
stage('Build') {
steps {
script {
node('build-node') {
echo 'Building on build-node...'
}
}
}
}
}
}
这个例子中没有全局 Agent(agent none),而是在 Build 阶段中显式地使用 node('build-node') 来指定执行节点。
Node 的关键属性:
| 属性 | 含义 |
|---|---|
| Labels | 标签,用于分类和筛选节点(如 Linux、Windows、docker) |
| Workspace | 节点上的工作目录,用于存放构建文件 |
| Executor | 该节点可同时执行的任务数 |
5. Agent 与 Node 的关键区别
| 特性 | Agent | Node |
|---|---|---|
| 抽象层级 | 更抽象,可以代表多个节点 | 更具体,代表实际执行任务的机器 |
| 使用方式 | 用于指定执行环境 | 在脚本中显式分配执行机器 |
| 控制粒度 | 高级控制(Pipeline/Stage 级别) | 细粒度控制(Script 块内) |
✅ 总结:
- Agent 是声明式语法中用于指定执行环境的关键字;
- Node 是脚本式语法中用于分配具体执行机器的关键字;
- 两者本质上都指向 Jenkins 架构中的“执行节点”,但使用场景不同。
6. 实战场景与配置策略
6.1 Agent 的典型使用场景
场景一:不同阶段运行在不同节点上
pipeline {
agent any
stages {
stage('Build') {
steps {
echo 'Building...'
}
}
stage('Test') {
agent {
label 'test-node'
}
steps {
echo 'Testing...'
}
}
}
}
这个配置中,Build 阶段可以在任意节点上运行,而 Test 阶段则必须运行在 test-node 标签的节点上。
场景二:使用 Docker 容器作为执行环境
pipeline {
agent {
docker {
image 'maven:3-alpine'
}
}
stages {
stage('Build') {
steps {
sh 'mvn clean install'
}
}
}
}
这种配置确保每次构建都在一个干净的 Maven 容器中运行,避免依赖污染,提升构建一致性。
6.2 Node 的典型使用场景
场景:动态分配节点执行任务
pipeline {
agent none
stages {
stage('Build') {
steps {
script {
node('build-node') {
echo 'Building on build-node...'
}
}
}
}
}
}
这个配置适用于需要在脚本中动态决定执行节点的场景,比如根据环境变量或构建参数选择不同节点。
⚠️ 踩坑提醒:如果你在 script 块中使用 node(),但没有关闭全局 agent,可能会导致节点冲突,建议统一使用 agent none 避免冲突。
7. 总结
Agent 和 Node 是 Jenkins Pipeline 中两个核心概念:
- Agent 是一种声明式语法,用于指定执行环境;
- Node 是脚本式语法中用于分配具体执行机器的关键字;
- 它们在功能上有所重叠,但适用场景不同。
通过合理使用 Agent 和 Node,你可以更灵活地控制 Pipeline 的执行流程,从而优化 CI/CD 的效率和稳定性。
✅ 建议:
- 简单流程优先使用 Agent;
- 复杂逻辑或动态分配时使用 Node;
- 混合使用时注意避免冲突。
合理规划你的 Jenkins Pipeline,才能真正发挥 CI/CD 的威力。