1. 概述
在本教程中,我们将展示如何确保部署在 OpenShift 中的应用保持健康状态。
2. 什么是健康的应用?
首先,我们来理解一下“应用健康”意味着什么。
部署在 Pod 中的应用经常会遇到一些问题。比如应用可能停止响应,或者响应内容错误。造成应用不健康的原因可能是临时性问题,例如配置错误、与数据库、存储或其他服务之间的连接问题。
构建弹性应用的第一步,就是在 Pod 上实现自动健康检查机制。 一旦发现问题,Pod 会被自动重启,而无需人工干预。
3. 使用探针进行健康检查
Kubernetes 提供了两种探针机制,OpenShift 也继承了这一特性:liveness probe(存活探针) 和 readiness probe(就绪探针)。
- ✅ Liveness Probe:用于判断容器是否还“活着”,如果探针失败,OpenShift 会重启容器。
- ✅ Readiness Probe:用于判断容器是否已经准备好接收流量。如果探针失败,该 Pod 会被从负载均衡池中剔除,但不会重启。
如果容器启动时间较长,比如需要初始化数据或连接其他服务,readiness probe 可以避免将请求路由到尚未准备好的 Pod。
我们可以通过以下两种方式配置 liveness probe:
- 修改 Deployment 配置文件(来自 Kubernetes 原生支持)
- 使用 OpenShift 图形界面(GUI)
本教程主要演示如何通过 OpenShift 的图形界面配置探针。
4. 配置 Liveness Probe
Liveness Probe 是在 Deployment 配置文件中为特定容器定义的,Pod 内的所有容器都会继承这个配置。
- ✅ 如果探针类型是 HTTP 或 TCP 检查,OpenShift 会在容器所在节点上执行探针。
- ✅ 如果是脚本探针,则会在容器内部执行。
下面我们演示如何通过 OpenShift 控制台添加 Liveness Probe:
- 选择应用所属的项目
- 点击左侧菜单 Applications -> Deployments
- 选择目标应用
- 在“Deployment Configuration”标签页中,点击 Add Health Checks 提示中的链接(仅当尚未配置健康检查时显示)
- 选择 Add Liveness Probe
- 按需配置探针参数:
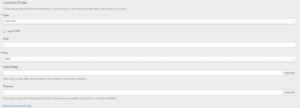
以下是 Liveness Probe 的配置项说明:
- Type:探针类型,支持 HTTP(S)、Exec(执行脚本)、TCP Socket
- Use HTTPS:若服务通过 HTTPS 暴露,则勾选
- Path:健康检查的路径(如
/health) - Port:用于探针检查的端口
- Initial Delay:容器启动后等待多少秒才开始执行探针,默认为 0
- Timeout:探针超时时间,默认为 1 秒
配置完成后,OpenShift 会自动创建新的 DeploymentConfig,其中包含配置的探针信息。
5. 配置 Readiness Probe
Readiness Probe 用于确保容器在准备好接收流量前不会被加入负载均衡池。与 liveness probe 不同的是,readiness probe 失败时容器不会被重启,只是被标记为不可用。
- ✅ Readiness Probe 是实现零停机部署的关键机制。
配置 readiness probe 的方式与 liveness probe 类似:
- 选择项目和应用
- 进入“Deployment Configuration”页面
- 点击右上角 Actions -> Edit Health Checks
- 选择 Add Readiness Probe
- 按需配置探针参数:
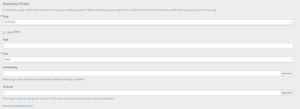
参数说明与 liveness probe 相同,不再赘述。
配置完成后,OpenShift 也会更新 DeploymentConfig,新增 readiness probe 配置。
6. 实战测试
为了验证健康检查是否生效,我们可以部署一个 Spring Boot 应用作为测试对象。
Spring Boot 应用可以使用 Spring Boot Actuator 提供的 /actuator/health 接口作为健康检查的 endpoint。
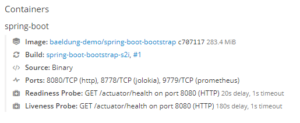
部署完成后,按上述步骤配置 liveness 和 readiness 探针。最终 Deployment 配置页面会显示探针信息:
6.1 测试 Readiness Probe
我们模拟一次新版本部署:
- OpenShift 创建新 Pod
- 旧 Pod 继续处理请求
- 新 Pod 通过 readiness probe 成功后,才开始接收流量
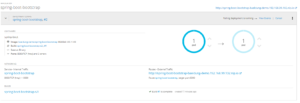
这样就能实现零停机部署,OpenShift 控制台可以看到如下状态:
6.2 测试 Liveness Probe
我们模拟 liveness probe 失败的场景:
- 健康检查返回失败状态
- OpenShift 会尝试重启 Pod,默认最多重启 3 次
- 如果重启后问题依旧,Pod 会被标记为 Failed
我们可以在 Pod 的事件页面中看到类似如下记录:
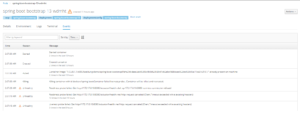
OpenShift 会记录健康检查失败,并尝试重启 Pod。
7. 总结
在本教程中,我们学习了 OpenShift 中两种健康检查探针的使用:
- ✅ Liveness Probe:用于检测容器是否存活,失败则重启
- ✅ Readiness Probe:用于检测容器是否就绪,失败则不转发流量
两者结合使用,可以有效提升应用的可用性和自愈能力。完整的示例代码可以在 GitHub 上找到:GitHub 示例。