1. 引言
GraphQL 是 Facebook 推出的一项相对较新的技术。它是一种查询语言,用于从服务器检索数据,是 REST、SOAP 或 gRPC 的替代方案。
在本教程中,我们将学习如何使用 Spring Boot 设置 GraphQL 服务器,以便将其添加到现有应用程序或用于新项目。
2. 什么是 GraphQL?
传统的 REST API 围绕服务器管理的资源构建,通过标准的 HTTP 动词进行操作。虽然在这种框架内有效,但当偏离该框架或客户端需要同时从多个资源获取数据时,它们就会遇到困难,通常由于不必要的数据导致响应体积较大。
GraphQL 通过赋予客户端在单个查询中精确请求所需数据的能力来解决这些挑战,支持导航子资源,并允许同时执行多个查询。 这种方法类似于 RPC(远程过程调用),强调命名查询和变更(mutation),使 API 开发者和消费者都能有效控制功能和期望结果。
例如,一个博客可能允许以下查询:
query {
recentPosts(count: 10, offset: 0) {
id
title
category
author {
id
name
thumbnail
}
}
}
这个查询将:
- 请求最新的 10 篇文章
- 对于每篇文章,请求 ID、标题和类别
- 对于每篇文章,请求作者信息,返回 ID、名称和缩略图
在传统的 REST API 中,这需要 11 个请求(一个请求文章,10 个请求作者),或者在文章详情中包含作者详情。
2.1. GraphQL 模式
GraphQL 服务器暴露一个描述 API 的模式(schema)。该模式由类型定义组成。每个类型有一个或多个字段,每个字段接受零个或多个参数并返回特定类型。
图(graph)源于这些字段相互嵌套的方式。注意,图不必是非循环的,循环是完全可以接受的,但它是有向的。客户端可以从一个字段导航到其子字段,但不能自动返回父字段,除非模式显式定义了这一点。
博客的 GraphQL 模式示例可能包含以下定义,描述文章(Post)、文章的作者(Author)以及用于获取博客最新文章的根查询(root query):
type Post {
id: ID!
title: String!
text: String!
category: String
author: Author!
}
type Author {
id: ID!
name: String!
thumbnail: String
posts: [Post]!
}
# The Root Query for the application
type Query {
recentPosts(count: Int, offset: Int): [Post]!
}
# The Root Mutation for the application
type Mutation {
createPost(title: String!, text: String!, category: String, authorId: String!) : Post!
}
某些名称末尾的“!”表示该类型不可为空。任何没有此标记的类型在服务器响应中可以为空。GraphQL 服务会正确处理这些情况,允许我们安全地请求可空类型的子字段。
GraphQL 服务还通过一组标准字段暴露模式,允许任何客户端提前查询模式定义。
这使得客户端能够自动检测模式何时更改,并允许客户端动态适应模式的工作方式。一个非常有用的例子是 GraphiQL 工具,它允许我们与任何 GraphQL API 进行交互。
3. 介绍 GraphQL Spring Boot Starter
Spring Boot GraphQL Starter 提供了一种在极短时间内启动 GraphQL 服务器的绝佳方式。通过自动配置和基于注解的编程方法,我们只需要编写服务所需的代码。
3.1. 设置服务
为此,我们只需要正确的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-graphql</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
由于 GraphQL 是传输无关的,我们在配置中包含了 web starter。这通过 Spring MVC 在默认的 /graphql 接口上通过 HTTP 暴露 GraphQL API。对于其他底层实现(如 Spring Webflux),可以使用其他 starter。
如果需要,我们还可以在 application.properties 文件中自定义此接口。
4. 编写模式
GraphQL Boot starter 通过处理 GraphQL 模式文件来构建正确的结构,然后将特殊的 bean 连接到该结构。Spring Boot GraphQL starter 会自动查找这些模式文件。
我们需要将这些“*.graphqls”或“.gqls*”模式文件保存在 src/main/resources/graphql/** 位置,Spring Boot 会自动拾取它们。通常,我们可以通过 spring.graphql.schema.locations 和 spring.graphql.schema.file-extensions 配置属性来自定义位置和文件扩展名。
一个要求是必须有一个根查询(root query)和最多一个根变更(root mutation)。与模式的其余部分不同,我们不能将其拆分到多个文件中。这是 GraphQL 模式定义的限制,而不是 Java 实现的限制。
5. 实现我们的模式
编写模式后,我们需要能够在代码中实现它。这包括我们可以实现的三种不同类型的代码:
- 根查询解析器(Root Query Resolver)—— 用于解析模式中顶级查询的值。
- 字段解析器(Field Resolver)—— 用于解析响应中嵌套的值。
- 变更(Mutations)—— 用于实现模式中的变更操作。
所有这些都是通过在应用程序中编写 bean 并用适当的注解来实现的。
5.1. 根查询解析器
根查询需要使用特殊注解的方法来处理此根查询中的各个字段。与模式定义不同,对根查询字段只有一个 Spring bean 没有限制。
我们需要使用 @QueryMapping 注解来注解处理方法,并将这些方法放在应用程序中的标准 @Controller 组件内。这将注解的类注册为 GraphQL 应用程序中的数据获取组件:
@Controller
public class PostController {
private PostDao postDao;
@QueryMapping
public List<Post> recentPosts(@Argument int count, @Argument int offset) {
return postDao.getRecentPosts(count, offset);
}
}
上面定义了方法 recentPosts,我们将用它来处理对之前定义的模式中 recentPosts 字段的任何 GraphQL 查询。此外,该方法必须具有用 @Argument 注解的参数,这些参数对应于模式中的相应参数。
它还可以选择性地接受其他 GraphQL 相关参数,例如 GraphQLContext、DataFetchingEnvironment 等,以访问底层上下文和环境。
该方法还必须返回 GraphQL 模式中类型的正确返回类型,正如我们即将看到的。我们可以使用任何简单类型,如 String、Int、List 等,使用等效的 Java 类型,系统会自动映射它们。
5.2. 使用 Bean 表示类型
GraphQL 服务器中的每个复杂类型都由一个 Java bean 表示,无论它是从根查询加载还是从结构中的任何其他位置加载。同一个 Java 类必须始终表示相同的 GraphQL 类型,但类的名称并不重要。
Java bean 中的字段将根据字段名称直接映射到 GraphQL 响应中的字段:
public class Post {
private String id;
private String title;
private String category;
private String authorId;
}
Java bean 中不映射到 GraphQL 模式的任何字段或方法将被忽略,但不会引起问题。这对于字段解析器的工作很重要。
例如,这里的 authorId 字段与我们之前定义的模式中的任何内容都不对应,但它可用于下一步。
5.3. 复杂值的字段解析器
有时,字段的值加载起来并不简单。这可能涉及数据库查询、复杂计算或其他任何操作。**@SchemaMapping* 注解将处理方法映射到模式中同名字段,并将其用作该字段的数据获取器(DataFetcher)。
@SchemaMapping
public Author author(Post post) {
return authorDao.getAuthor(post.getAuthorId());
}
重要的是,如果客户端没有请求某个字段,GraphQL 服务器就不会执行检索该字段的工作。这意味着如果客户端检索 Post 但没有请求 author 字段,则不会执行上面的 author() 方法,也不会进行 DAO 调用。
或者,我们也可以在注解中指定父类型名称和字段名称:
@SchemaMapping(typeName="Post", field="author")
public Author getAuthor(Post post) {
return authorDao.getAuthor(post.getAuthorId());
}
这里,注解属性用于声明此方法为模式中 author 字段的处理器。
5.4. 可空值
GraphQL 模式具有某些类型可空而其他类型不可空的概念。
我们在 Java 代码中通过直接使用 null 值来处理这个问题。相反,我们可以使用 Java 8 中的新 Optional 类型来表示可空类型,系统会正确处理这些值。
这非常有用,因为这意味着我们的 Java 代码从方法定义上就明显与 GraphQL 模式一致。
5.5. 变更
到目前为止,我们所做的一切都是从服务器检索数据。GraphQL 还能够通过变更(mutations)更新服务器上存储的数据。
从代码的角度来看,查询不能更改服务器上的数据是没有理由的。我们可以轻松编写查询解析器,接受参数,保存新数据并返回这些更改。这样做会给 API 客户端带来意外的副作用,因此被认为是不好的做法。
相反,应该使用变更来通知客户端这将导致存储的数据发生更改。
与查询类似,变更通过在控制器中使用 @MutationMapping 注解处理方法来定义。变更字段的返回值与查询字段的处理方式完全相同,也允许检索嵌套值:
@MutationMapping
public Post createPost(@Argument String title, @Argument String text,
@Argument String category, @Argument String authorId) {
Post post = new Post();
post.setId(UUID.randomUUID().toString());
post.setTitle(title);
post.setText(text);
post.setCategory(category);
post.setAuthorId(authorId);
postDao.savePost(post);
return post;
}
6. GraphiQL
GraphQL 还有一个名为 GraphiQL 的配套工具。这个 UI 工具可以与任何 GraphQL 服务器通信,有助于使用和开发 GraphQL API。它的可下载版本是一个 Electron 应用程序,可以从这里获取。
Spring GraphQL 内置了 GraphiQL。默认情况下它是关闭的,但我们可以通过在 application.yml 中添加以下内容来启用它:
spring:
graphql:
graphiql:
enabled: true
完成后,我们可以导航到应用程序的 /graphiql 接口,获取完整的 GraphiQL 用户界面来与我们的 API 交互。这提供了一个非常有用的浏览器内工具来编写和测试查询,特别是在开发和测试期间:
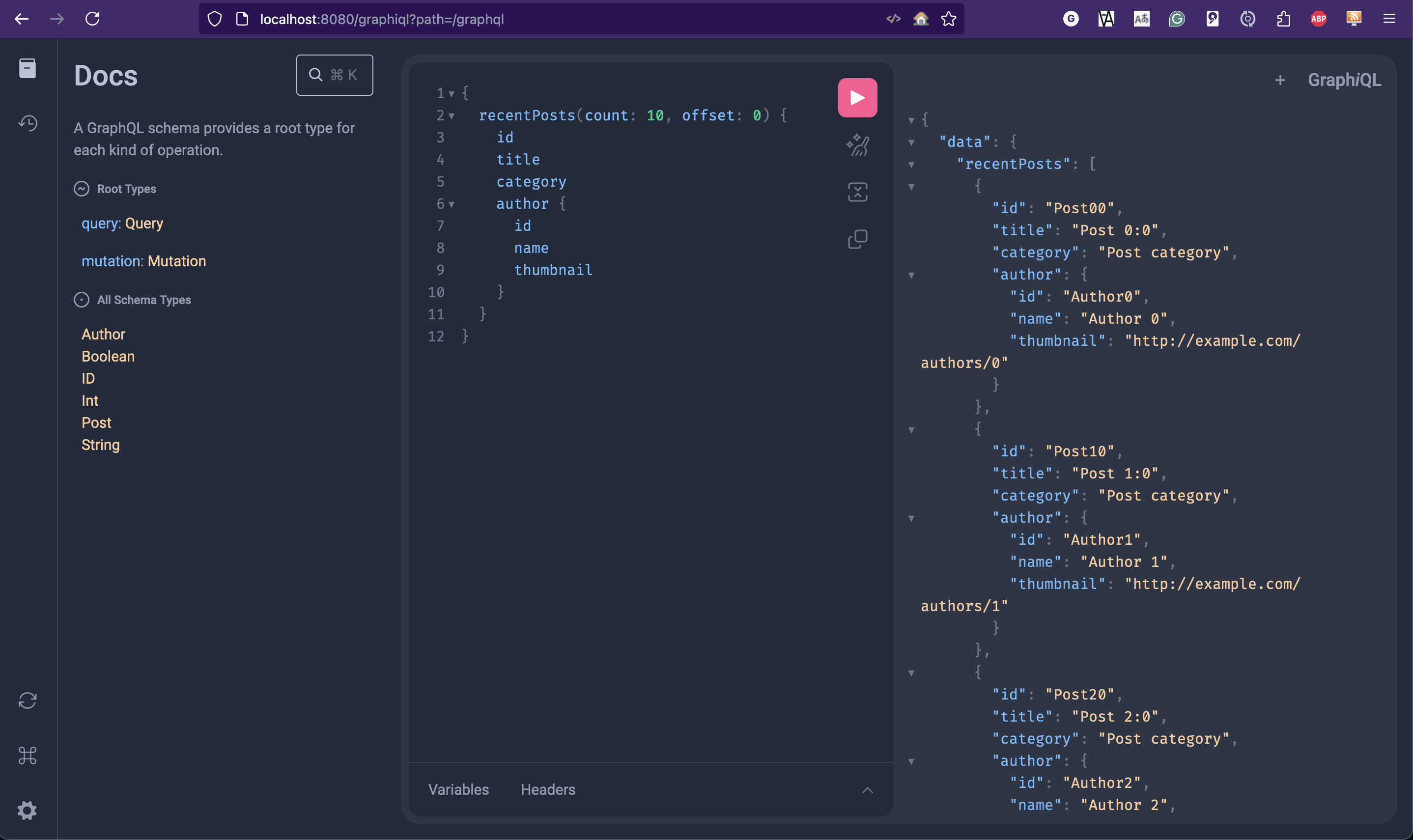
7. 总结
GraphQL 是一项令人兴奋的新技术,有潜力彻底改变我们开发 Web API 的方式。
Spring Boot GraphQL Starter 使得将这项技术添加到任何新的或现有的 Spring Boot 应用程序变得简单。