1. 概述
在编程中,优化代码性能是关键,特别是在处理昂贵操作或数据检索过程时。一个有效的性能提升方法是使用缓存。Project Reactor库提供了cache()方法,用于缓存那些几乎不会改变的昂贵操作或数据,以避免重复操作并提高效率。
本教程将探讨记忆化(memoization),一种缓存形式,并展示如何使用Project Reactor库的Mono.cache()来缓存来自JSONPlaceholder API的HTTP GET请求结果。同时,我们将通过大理石图理解Mono.cache()方法的内部工作原理。
2. 记忆化理解
记忆化是一种缓存机制,它存储昂贵函数调用的结果。当相同的函数再次被调用时,返回缓存的结果。
在涉及递归函数(/java-recursion)或对于给定输入始终产生相同输出的计算时,它非常有用。
让我们看一个Java示例,使用斐波那契数列来演示记忆化。首先,创建一个Map对象来存储结果:
private static final Map<Integer, Long> cache = new HashMap<>();
接下来,定义一个计算斐波那契序列的方法:
long fibonacci(int n) {
if (n <= 1) {
return n;
}
if (cache.containsKey(n)) {
return cache.get(n);
}
long result = fibonacci(n - 1) + fibonacci(n - 2);
logger.info("First occurrence of " + n);
cache.put(n, result);
return result;
}
在这段代码中,我们在进一步计算之前检查整数n是否已存储在Map对象中。如果已存在,我们返回缓存的值;否则,我们递归计算结果并将其存储在Map对象中供后续使用。
这个方法通过避免冗余计算显著提高了斐波那契计算的性能。
让我们为方法编写一个单元测试:
@Test
void givenFibonacciNumber_whenFirstOccurenceIsCache_thenReturnCacheResultOnSecondCall() {
assertEquals(5, FibonacciMemoization.fibonacci(5));
assertEquals(2, FibonacciMemoization.fibonacci(3));
assertEquals(55, FibonacciMemoization.fibonacci(10));
assertEquals(21, FibonacciMemoization.fibonacci(8));
}
在测试中,我们调用fibonacci()来计算序列。
3. 描述Mono.cache()的大理石图
Mono.cache()操作器帮助缓存Mono发布者的结果,并在后续订阅时返回缓存的值。
大理石图有助于理解反应式类的内部细节以及它们的工作方式。以下是一个说明cache()操作行为的大理石图:
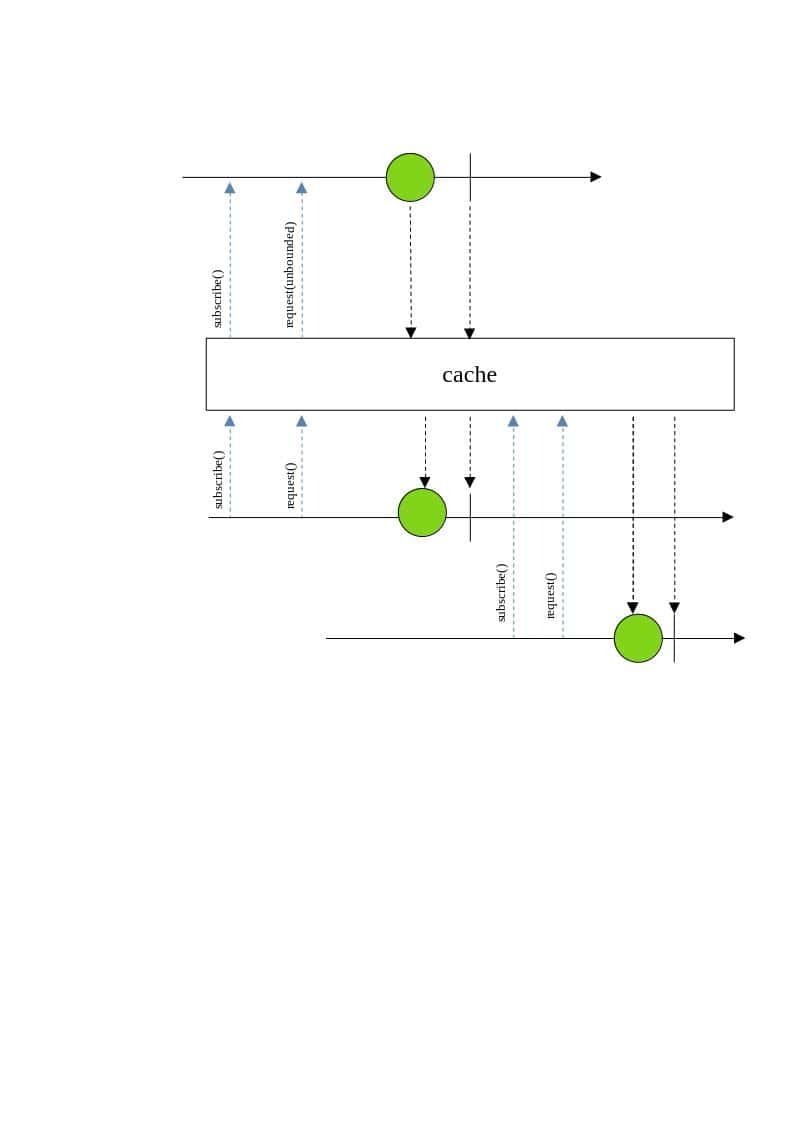
在上图中,对Mono发布者的首次订阅会发出数据并将其缓存。后续订阅会检索缓存的数据,而不会触发新的计算或数据获取。
4. 示例设置
为了演示Mono.cache()的用法,我们需要在pom.xml中添加reactor-core:
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
<version>3.6.5</version>
</dependency>
该库提供了Mono、Flux等操作符,用于在Java中实现反应式编程。
同时,我们也需要添加spring-boot-starter-webflux到pom.xml:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
<version>3.2.5</version>
</dependency>
这个依赖提供了WebClient类来消费API。
此外,让我们看一下GET请求到https://jsonplaceholder.typicode.com/users/2时的样本响应:
{
"id": 2,
"name": "Ervin Howell",
"username": "Antonette"
// ...
}
接下来,创建一个名为User的POJO类,用于解析从GET请求接收到的JSON响应:
public class User {
private int id;
private String name;
// standard constructor, getter and setter
}
然后,创建一个WebClient对象并设置API的基URL:
WebClient client = WebClient.create("https://jsonplaceholder.typicode.com/users");
这将作为使用cache()方法缓存HTTP响应的基础URL。
最后,创建一个AtomicInteger对象:
AtomicInteger counter = new AtomicInteger(0);
这个对象用于跟踪我们向API发起GET请求的次数。
5. 不使用记忆化的数据获取
首先,定义一个从WebClient对象获取用户的方法:
Mono<User> retrieveOneUser(int id) {
return client.get()
.uri("/{id}", id)
.retrieve()
.bodyToMono(User.class)
.doOnSubscribe(i -> counter.incrementAndGet())
.onErrorResume(Mono::error);
}
在这段代码中,我们根据特定ID获取用户,并将响应体映射到User对象。每次订阅时,我们还会增加计数器。
这里有一个不使用缓存获取用户的测试案例:
@Test
void givenRetrievedUser_whenTheCallToRemoteIsNotCache_thenReturnInvocationCountAndCompareResult() {
MemoizationWithMonoCache memoizationWithMonoCache = new MemoizationWithMonoCache();
Mono<User> retrieveOneUser = MemoizationWithMonoCache.retrieveOneUser(1);
AtomicReference<User> firstUser = new AtomicReference<>();
AtomicReference<User> secondUser = new AtomicReference<>();
Disposable firstUserCall = retrieveOneUser.map(user -> {
firstUser.set(user);
return user.getName();
})
.subscribe();
Disposable secondUserCall = retrieveOneUser.map(user -> {
secondUser.set(user);
return user.getName();
})
.subscribe();
assertEquals(2, memoizationWithMonoCache.getCounter());
assertEquals(firstUser.get(), secondUser.get());
}
这里,我们两次订阅retrieveOneUser Mono,每次订阅都会触发对WebClient对象的单独GET请求。我们断言计数器会增加两次。
6. 使用记忆化的数据获取
现在,我们修改先前的示例,利用Mono.cache()并缓存第一次GET请求的结果:
@Test
void givenRetrievedUser_whenTheCallToRemoteIsCache_thenReturnInvocationCountAndCompareResult() {
MemoizationWithMonoCache memoizationWithMonoCache = new MemoizationWithMonoCache();
Mono<User> retrieveOneUser = MemoizationWithMonoCache.retrieveOneUser(1).cache();
AtomicReference<User> firstUser = new AtomicReference<>();
AtomicReference<User> secondUser = new AtomicReference<>();
Disposable firstUserCall = retrieveOneUser.map(user -> {
firstUser.set(user);
return user.getName();
})
.subscribe();
Disposable secondUserCall = retrieveOneUser.map(user -> {
secondUser.set(user);
return user.getName();
})
.subscribe();
assertEquals(1, memoizationWithMonoCache.getCounter());
assertEquals(firstUser.get(), secondUser.get());
}
与前一个示例的主要区别在于,我们在订阅retrieveOneUser对象之前调用了cache()操作。这将缓存第一次GET请求的结果,后续订阅将接收缓存的结果,而不是触发新的请求。
在测试案例中,我们断言计数器只增加一次,因为第二次订阅使用了缓存值。
7. 设置缓存持续时间
默认情况下,Mono.Cache()无限期地缓存结果。但在数据可能随着时间而过时的情况下,设置缓存时长至关重要:
// ...
Mono<User> retrieveOneUser = memoizationWithMonoCache.retrieveOneUser(1)
.cache(Duration.ofMinutes(5));
// ...
在代码中,cache()方法接受一个Duration实例作为参数。缓存的值将在5分钟后过期,之后的任何订阅都将触发新的GET请求。
8. 总结
在这篇文章中,我们学习了记忆化的基本概念以及如何在Java中使用斐波那契数列示例实现。然后,我们深入探讨了Project Reactor库中的Mono.cache()的用法,并展示了如何缓存HTTP GET请求的结果。
缓存是提高性能的强大工具。然而,确保过时数据不会无限期提供至关重要,需要考虑缓存失效策略。
如往常一样,示例的完整源代码可在GitHub上找到。