1. 什么是事务
在编程中,事务(Transaction)指的是一组需要作为整体执行的相关操作。换句话说,它是一个逻辑上的工作单元,其对外的影响要么全部生效,要么完全不生效。我们引入事务,核心目的就是为了保障数据的一致性和完整性。
举个常见的场景:在一个基于事件驱动的微服务架构中,我们通常需要做两件事:
- 更新本地数据库
- 向消息队列发送一条事件,供其他服务消费

我们希望这两个操作要么都成功,要么都失败。如果只成功一半(比如数据库更新了但消息没发出去),就会导致系统状态不一致。
解决办法就是把这两个操作包装在一个事务里:

这里的数据库、消息中间件等,我们统称为事务的参与资源(participating resources)。
✅ 关键点:
- 事务 = 原子性操作单元
- 目标:保证数据最终一致性
- 典型场景:DB + MQ 联动
2. 事务的发展简史
事务的概念最早与关系型数据库紧密绑定。它的演进史,基本就是数据库技术的发展史。
1970年,Edgar F. Codd 发表了关于关系模型的奠基性论文,为现代数据库和事务理论打下基础。
2.1 早期事务模型
随着关系型数据库普及,多用户并发访问的系统变得复杂,数据一致性问题凸显。于是,ACID 四大特性应运而生:
- Atomicity(原子性)
- Consistency(一致性)
- Isolation(隔离性)
- Durability(持久性)
ACID 保证了事务的原子性和可串行化,非常适合短事务、单数据库的场景。
但随着业务增长,出现了长事务、复杂业务流程的需求。简单的 ACID 模型扛不住了,于是出现了更复杂的事务模型,比如:
- 子事务(Sub-transaction)
- 事务组(Transaction Groups)
这些模型能更精细地处理长事务中的失败场景。
2.2 高级事务模型
接下来的演进方向是分布式事务和嵌套事务:
- 分布式事务:自底向上,将复杂事务拆分为跨多个资源的子事务
- 嵌套事务:自顶向下,支持事务中再开启子事务
随着参与资源变得异构(数据库、MQ、Web 服务等),X/Open DTP 模型诞生,成为跨系统事务的事实标准。
另外两个重要模型:
- Chained Transactions(链式事务):把长事务拆成多个顺序执行的短事务
- Sagas(Saga 模式):在链式事务基础上,引入补偿机制来回滚已执行的子事务
⚠️ 重点:Saga 模式之所以在微服务时代大放异彩,正是因为它放宽了强一致性要求,用最终一致性换取可用性和灵活性。
我们后面会详细展开这些概念。
3. 本地事务 vs 分布式事务
根据参与资源的数量和位置,事务分为两类:
| 类型 | 特点 | 示例 |
|---|---|---|
| ✅ 本地事务 | 所有操作在同一个资源内完成 | 单个数据库内的多表操作 |
| ❌ 分布式事务 | 操作跨越多个独立资源 | DB + MQ、跨库操作 |
图示如下:

⚠️ 注意:这里的“资源”可以是:
- 同一台机器的不同数据库实例
- 不同机器上的消息队列
- 远程 Web 服务(如支付接口)
资源的位置和数量,直接决定了事务实现的复杂度和可选方案。
4. 事务的保障机制
使用事务的核心目标是保证数据完整性。但不同的系统,提供的保障级别不同。
4.1 ACID 特性
ACID 是事务最经典的保障模型,由 Jim Gray 提出:
| 特性 | 说明 |
|---|---|
| ✅ Atomicity(原子性) | 要么全成功,要么全失败,不存在中间状态 |
| ✅ Consistency(一致性) | 事务前后,数据必须满足所有预定义约束(如外键、唯一索引) |
| ✅ Isolation(隔离性) | 并发事务之间互不干扰,通过隔离级别(如 READ_COMMITTED)控制 |
| ✅ Durability(持久性) | 一旦提交,数据必须永久保存(通常落盘) |
📌 划重点:ACID 是理想模型,但在分布式系统中,往往需要做权衡。
4.2 CAP 定理
分布式系统绕不开的铁律——CAP 定理(Brewer 提出):
在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)三者不可兼得,最多只能同时满足两个。
| 维度 | 说明 |
|---|---|
| ✅ Consistency | 所有节点在同一时间看到的数据是一致的(强一致性) |
| ✅ Availability | 非故障节点总能在合理时间内返回结果(高可用) |
| ✅ Partition Tolerance | 网络分区时系统仍能继续运行 |
⚠️ 现实选择:
- 分区容错(P)是必选项(网络不可靠)
- 所以实际只能在 CP(强一致) 和 AP(高可用) 之间二选一
比如:
- ZooKeeper:CP 系统
- Cassandra:AP 系统
💡 注意:这里的“Consistency”是 CAP 中的“一致性”,和 ACID 中的 C 不是一个概念,别搞混。
4.3 BASE 理论
为了在 CAP 中选择 AP,诞生了 BASE 理论,它是对 ACID 的反向补充:
| 缩写 | 含义 |
|---|---|
| ✅ Basically Available(基本可用) | 系统允许暂时返回旧数据,保证可用性 |
| ✅ Soft State(软状态) | 系统状态可以在没有外部输入的情况下变化 |
| ✅ Eventual Consistency(最终一致性) | 数据最终会达到一致状态 |
📌 简单粗暴理解:
- ACID:强一致,事务结束即一致
- BASE:弱一致,事务结束可能不一致,但最终会一致
微服务架构中,Saga 模式、事件驱动架构,本质上都是 BASE 思想的体现。
5. 分布式提交协议
本地事务由数据库自己管,但分布式事务需要协调者。
5.1 两阶段提交(2PC)
最经典的分布式事务协议,分两步走:

准备阶段(Prepare)
协调者问所有参与者:“你们准备好提交了吗?”
参与者锁定资源,写日志,回复“Yes”或“No”。提交阶段(Commit)
- 如果所有参与者都同意 → 发送
commit指令 - 任一拒绝 → 发送
rollback指令
- 如果所有参与者都同意 → 发送
✅ 优点:保证 ACID
❌ 缺点:阻塞!
- 协调者挂了,所有参与者卡住
- 某个参与者挂了,事务无法推进
5.2 三阶段提交(3PC)
为了解决 2PC 的阻塞问题,3PC 引入了预提交阶段:

三个阶段:
- CanCommit? → 询问是否可以执行
- PreCommit → 预提交,参与者准备资源
- DoCommit → 正式提交
✅ 改进:PreCommit 阶段达成“共识”,即使协调者挂了,参与者也能根据状态决定是提交还是回滚。
⚠️ 局限:
- 延迟更高(多一轮通信)
- 网络分区下仍可能出问题
6. 工业级事务规范
为了避免厂商私有实现导致的兼容问题,业界推出了标准规范。
6.1 X/Open DTP 模型
XA(eXtended Architecture)是分布式事务的事实标准,1991 年由 X/Open 联盟发布。
核心组件:

| 角色 | 职责 |
|---|---|
| ✅ 应用程序(AP) | 定义事务边界,调用资源 |
| ✅ 事务管理器(TM) | 协调全局事务,驱动 2PC |
| ✅ 资源管理器(RM) | 管理具体资源(如 MySQL、RabbitMQ),支持 XA 接口 |
📌 Java 中的实现:
- JTA(Java Transaction API)是 XA 的 Java 标准
- 常见 TM:Atomikos、Narayana
- 支持 XA 的 RM:MySQL、Oracle、ActiveMQ 等
6.2 OMG OTS 模型
OTS(Object Transaction Service)是 OMG(对象管理组织)为 CORBA 系统设计的事务规范。
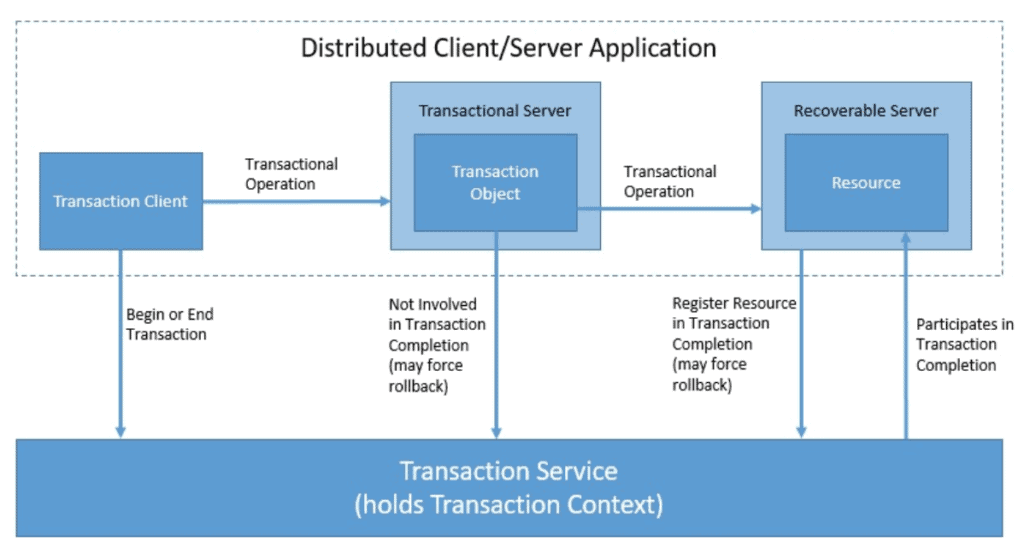
- 基于 CORBA IDL 接口
- 本质上是 XA 在对象模型中的映射
- 现在用得少,了解即可
7. 长事务处理模式
2PC/3PC 适合短事务,但长业务流程(如订单支付、物流跟踪)不能一直锁资源。
7.1 Saga 模式
Saga 将长事务拆为多个本地事务 + 补偿事务:
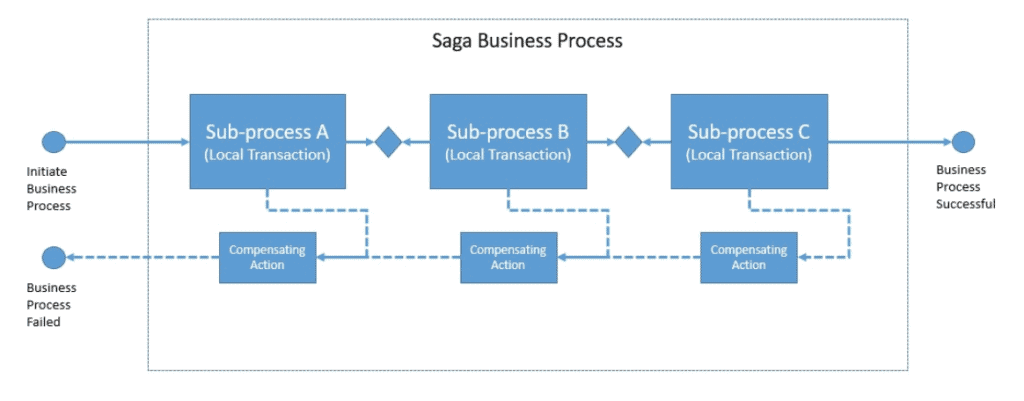
流程:
- T1 执行 → 成功
- T2 执行 → 失败
- 执行 T2 的补偿(Compensating Action)→ 回滚 T2
- 执行 T1 的补偿 → 回滚 T1
⚠️ 关键点:
- 不能真正回滚,只能“反向操作”来抵消影响
- 补偿操作要幂等(Idempotent),防止重复执行出错
- 适合高并发、松耦合的微服务场景
📌 实现方式:
- 编排式(Orchestration):一个中心服务控制流程
- 编配式(Choreography):服务间通过事件通信,无中心节点
7.2 OASIS WS-BA
WS-BA(Web Services – Business Activity)是为 SOAP 服务设计的 Saga 协议。
两种模式:
- Coordinator Completion:协调者决定何时完成
- Participant Completion:参与者自己决定完成时间
两种结果:
- Atomic Outcome:全部成功或全部补偿
- Mixed Outcome:允许部分成功
📌 适合传统 SOA 架构,现代微服务中较少使用。
7.3 OASIS BTP
BTP(Business Transaction Protocol)提供跨组织的业务事务协调。
两种事务类型:
- Atomic Transactions(Atoms):类似 2PC,结果原子
- Cohesive Transactions(Cohesions):允许不同参与者有不同结果
BTP 的核心是基于补偿的语义,适合异构环境下的业务流程协调。
8. 高级共识算法
2PC 本质是共识算法,但不够健壮。现代分布式系统用更先进的算法。
8.1 Paxos
由 Leslie Lamport 提出,首个被形式化证明正确的共识算法。
核心角色:
- Proposer:提出提案
- Acceptor:接受提案
- Learner:学习最终结果
两阶段 + 两子阶段:

- **Prepare (1A)**:Proposer 发起提案(带唯一编号)
- **Promise (1B)**:Acceptor 承诺不再接受更小编号的提案
- **Accept (2A)**:Proposer 收到多数 Promise 后,发送 Accept 请求
- **Accepted (2B)**:Acceptor 接受提案(除非已承诺更高编号)
✅ 优点:异步网络下仍能达成共识
⚠️ 缺点:太难懂,实现复杂
8.2 Raft
Raft 是 Paxos 的“易懂版”,目标是易于理解和实现。
三大核心:
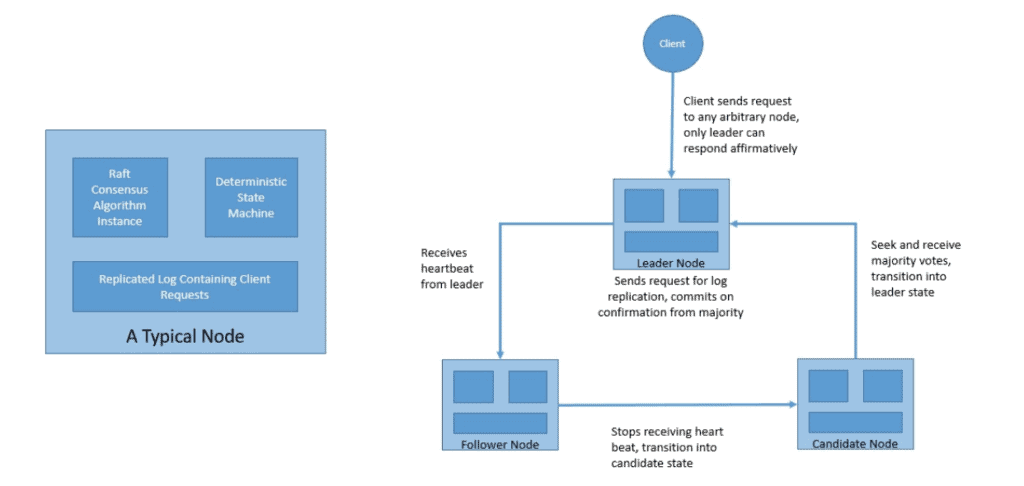
Leader 选举
- 节点状态:Follower / Candidate / Leader
- 心跳超时 → 转为 Candidate → 拉票 → 获多数票 → 成为 Leader
日志复制
- 客户端请求发给 Leader
- Leader 写日志 → 广播给 Follower
- 多数节点确认 → 提交 → 返回客户端
安全性
- 保证日志一致性(Log Matching)
- 选举限制(Election Restriction),避免脑裂
✅ 优点:
- 比 Paxos 好理解
- 被 etcd、Consul 等广泛采用
9. 总结
本文系统梳理了事务的核心概念与演进路径:
- 本地事务:单资源,ACID 原生支持
- 分布式事务:多资源,需协调协议(2PC/3PC)
- 工业标准:XA、JTA 是 Java 生态主流
- 长事务:Saga 模式 + 补偿机制,微服务首选
- 共识算法:Paxos 理论奠基,Raft 实践更优
📌 选型建议:
- 简单场景 → 本地事务 + 消息表
- 跨库事务 → XA + JTA(慎用,性能差)
- 微服务长流程 → Saga 模式(推荐)
- 高可用系统 → 最终一致性 + 补偿
事务没有银弹,关键是根据业务场景做权衡。踩过坑才知道,有时候“不一致”比“不可用”更可怕。