1. 引言
激活函数(Activation Functions),也被称为非线性函数,是神经网络结构和设计中不可或缺的一部分。但它们到底是什么?本文将从激活函数的基本概念讲起,介绍它们在神经网络中的作用,接着会讲解一些常见的激活函数,并探讨它们各自的优缺点。最后,我们还会提供一些选择激活函数的实用建议。
2. 什么是激活函数?
在深入讨论激活函数之前,我们先回顾一下标准前馈神经网络的基本结构。
一个标准的神经网络层可以表示为:
这是一个标准的线性变换,输入为  ,权重为
,权重为  ,偏置为
,偏置为  。
。
此时的模型本质上是一个线性回归模型。通过堆叠多个这样的层,我们可以构建一个神经网络。而在这之间,我们插入激活函数来引入非线性。
一个简单的神经网络通常包含两次线性变换:
- 第一层将输入转换为隐藏层的表示;
- 第二层将隐藏层映射到输出;
- 在第一层之后加入一个非线性激活函数。
这种结构非常强大,能够以任意精度逼近任意函数(即所谓的“通用函数逼近器”)。
那么,为什么这么简单的结构如此强大?什么是非线性激活函数?它又为什么如此重要?我们通过一个分类的例子来说明。
2.1 分类示例:AND 与 XOR
考虑一个简单的分类问题,比如判断两个输入是否满足某个布尔条件。例如,AND 函数就是一个线性可分函数。我们可以用散点图来表示它的输入输出关系:
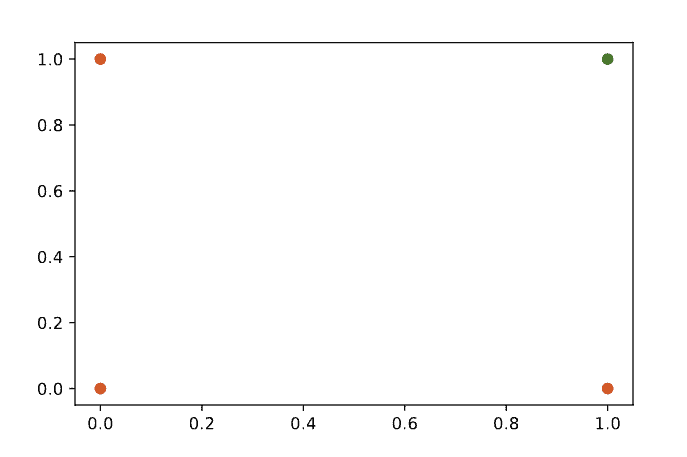
在这个图中,绿色点表示输出为 True,红色点表示输出为 False。我们可以用一条直线将它们分隔开。
如果我们使用单层网络,实际上就等同于逻辑回归模型。我们可以通过设置一个阈值来判断输出是 True 还是 False。这种函数可以看作是一个“阶跃函数(Step Function)”,但它不连续,不利于反向传播(Backpropagation)训练。
因此,我们需要一个连续版本的阶跃函数 —— 这就是 Sigmoid 函数。它将所有值压缩到 [0,1] 区间内,且中间部分变化陡峭,使得大多数值接近 0 或 1。
✅ 激活函数的本质:对输入数据进行非线性变换
虽然 Sigmoid 在输出层很有用,但在深层网络中也扮演着重要角色。我们将在下一节讨论为什么需要非线性激活函数。
3. 为什么需要激活函数?
在上一节中,我们讨论了激活函数如何帮助我们生成接近二分类的输出信号。但在深层神经网络中,非线性激活函数更是不可或缺。
3.1 大多数问题本质上是非线性的
现实世界中的大多数预测问题输出都不是线性的。许多任务需要非线性的决策边界。例如,XOR 函数就无法用一条直线进行分类。
神经网络之所以被称为“通用函数逼近器”,是因为它可以通过叠加线性变换和非线性激活函数来拟合任意复杂的函数。如果没有激活函数,整个网络就只是一个线性变换的组合,也就等价于一个线性模型。
✅ 没有激活函数 → 整个网络是线性的
通过在层之间插入非线性激活函数,我们可以构建出非常复杂的决策边界。
3.2 深度网络的训练挑战
激活函数在构建深度网络时也起着至关重要的作用。训练深度网络依赖于梯度信号在层之间的传播。
传统的 Sigmoid 函数在输入值接近最大值或最小值时会“饱和”,导致梯度趋近于零。这在深层网络中会造成“梯度消失(Vanishing Gradient)”问题,使训练变得困难。
为了解决这些问题,研究者提出了多种激活函数,比如 ReLU 及其变体。
4. 常见的激活函数
随着神经网络的发展,多种激活函数被提出。有些是为了应对特定问题而设计的,有些则逐渐成为主流。
早期常用激活函数:
- Sigmoid:将值压缩到 [0,1],适合输出为概率的场景
- Tanh:与 Sigmoid 类似,但输出范围为 [-1,1]
这两种函数在 RNN 架构中也常用于 LSTM 和 GRU 单元的设计。
⚠️ 缺点:容易饱和,导致梯度消失,在深层网络中表现不佳。
4.1 ReLU(Rectified Linear Unit)
ReLU 是目前最常用的激活函数之一。尽管它看起来是线性的,但它在神经网络中表现非常出色,能够有效缓解梯度消失问题。
✅ 公式:
图形如下: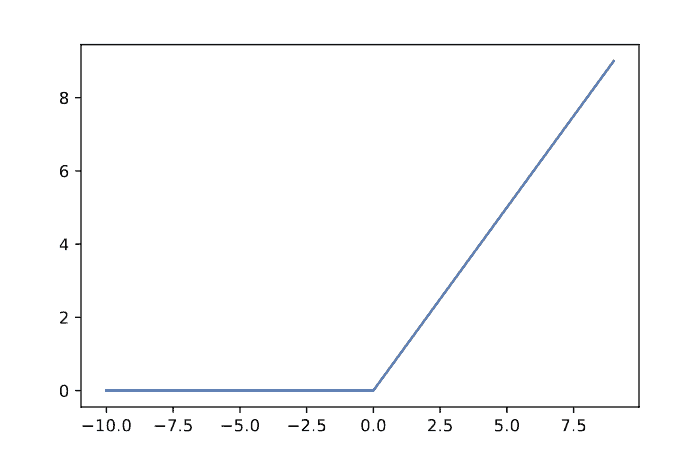
⚠️ 缺点:可能会导致“死神经元(Dead Neurons)”问题。
为了解决这个问题,Leaky ReLU 被提出,它允许一个很小的负值梯度通过。
4.2 其他激活函数
除了上述激活函数外,还有许多其他选择,适用于不同的场景:
- Softmax:用于多分类输出
- Swish:Google 提出的新型激活函数
- GELU:在 Transformer 模型中广泛使用
- Sinusoidal:用于周期性任务
✅ 提示:你也可以自定义激活函数,只要它满足可导性等训练需求。
5. 总结
本文我们讨论了激活函数在神经网络中的关键作用。随着网络架构的发展,激活函数也在不断演进,以适应更复杂的训练需求。
即使是一个只有一层隐藏层的简单神经网络,配合一个非线性激活函数,也能具备强大的表达能力。虽然激活函数的选择看似复杂,但建议从 ReLU 开始尝试,如果效果不佳再考虑其他变体。
✅ 建议:
- 分类任务输出层常用 Sigmoid 或 Softmax
- 隐藏层首选 ReLU 或其变体(如 Leaky ReLU)
- 特殊任务可考虑自定义激活函数或使用周期性激活函数
激活函数虽小,但影响深远。选择合适的激活函数,往往能带来性能上的显著提升。