1. 概述
本文将介绍语言处理器(Language Processor)的基本概念、作用及其分类,帮助读者理解编译器、解释器和汇编器之间的差异,以及它们在程序执行过程中的不同特点。
2. 什么是语言处理器?
✅ 语言处理器(Language Processor),也被称为翻译器(Translator),是一种将源代码从一种编程语言转换为另一种语言的程序。它不仅负责翻译代码,还会在过程中识别并报告错误。
我们编写的程序通常使用高级语言(如 Java、Python、C++)编写,但计算机只能理解机器码(即二进制的 0 和 1)。因此,语言处理器的作用就是将高级语言代码转换为机器能识别的指令。
语言处理器主要分为三类:
- 汇编器(Assembler)
- 编译器(Compiler)
- 解释器(Interpreter)
3. 汇编器
汇编器用于将汇编语言(Assembly Language)翻译成机器码。汇编语言是一种低级语言,与具体机器架构紧密相关,由类似 ADD、SUB、MOV 这样的指令组成。
举个例子:
MOV A, 5
ADD A, B
汇编器会将上述代码转换为对应的二进制指令。
下图展示了汇编器的工作流程:

4. 编译器
编译器读取整个源代码文件,将其一次性翻译为机器码,并生成一个目标文件(Object File)。
如果在编译过程中发现错误,编译器不会立即停止,而是继续读取代码,直到全部读完,再将所有错误信息一次性反馈给用户。
常见的编译型语言包括:C、C++、Java、Rust、Go、C# 等。
编译器的工作流程如下图所示:

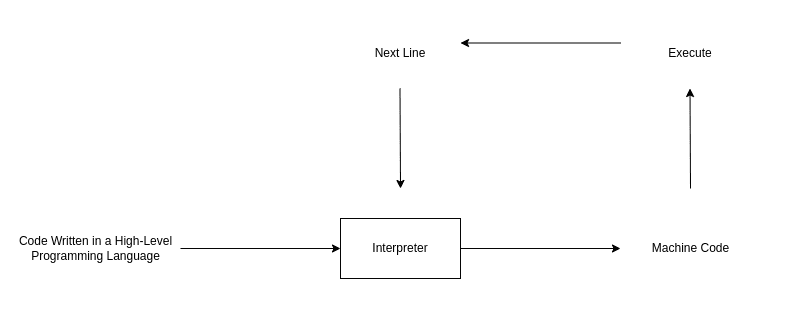
5. 解释器
解释器按行读取源代码,逐行翻译并执行,翻译一行执行一行,不生成目标文件。
当解释器遇到错误时,会立即停止执行,并提示错误信息。
常见的解释型语言包括:Python、JavaScript、PHP、Ruby 等。
解释器的执行流程如下图所示:
6. 编译器 vs 解释器 对比
| 对比维度 | 编译器 | 解释器 |
|---|---|---|
| ✅ 错误调试 | 报错延迟,编译完才提示所有错误 | 遇错立即停止,调试更直观 |
| ❌ 目标文件 | 生成目标文件(Object File) | 不生成目标文件 |
| ⚠️ 执行速度 | 快(目标代码可直接运行) | 慢(每次都要翻译) |
| ✅ 源代码依赖 | 一旦编译完成,不需要源码即可运行 | 每次运行都需要源代码 |
| ❌ 内存占用 | 占用内存较多 | 占用内存较少 |
6.1 调试体验
解释器在调试时更友好,遇到错误会立即停止,方便定位问题。而编译器会继续读取整个文件,直到结束才报告错误,可能需要反复编译才能找到所有错误。
6.2 是否生成目标文件
编译器会生成目标文件,程序运行时不再依赖源代码。解释器则不会生成任何中间文件,每次都必须从源代码开始执行。
6.3 执行效率
编译型语言通常执行速度更快,因为代码已经被翻译为机器码。而解释型语言每次都要翻译,效率相对较低。
6.4 源代码依赖
使用编译器生成的目标文件后,程序可以脱离源代码独立运行。而解释器必须始终依赖源代码来执行程序。
6.5 内存消耗
编译器需要生成目标代码,因此通常比解释器占用更多内存。
7. 总结
语言处理器是编程中不可或缺的一部分,它决定了程序的执行方式和性能表现。本文介绍了三种主要类型:
- 汇编器:将汇编语言翻译为机器码
- 编译器:一次性翻译整个程序,生成目标文件
- 解释器:逐行翻译并执行源代码
每种处理器都有其适用场景。选择合适的语言类型(编译型或解释型)对性能优化、开发效率和调试体验都有重要影响。
✅ 建议:根据项目需求选择语言类型,例如注重执行效率的系统开发优先选择编译型语言(如 C++、Rust),而快速开发或脚本任务更适合解释型语言(如 Python、JavaScript)。