1. 概述
本文将深入探讨卷积神经网络(CNN)的原理和结构。
我们会先介绍 CNN 通常解决的问题——特征提取,以及为何传统前馈神经网络在图像识别等任务中表现不佳。接着,我们会从矩阵运算的角度解释卷积操作,帮助理解 CNN 的工作机制。
最后,我们还会介绍除卷积层之外的其他关键组件,如池化层(Pooling)和 Dropout 层的作用。
学完本文后,你将了解 CNN 是什么,以及它为何能有效解决高维数据的分类问题。
2. 何时使用 CNN
2.1. 图像识别为何如此困难?
CNN 主要用于从数据中提取和识别抽象特征。以下图为例:

上图中的图像都是苹果,但它们在形状、大小、颜色等方面各不相同。人眼很容易识别它们都是苹果,但对计算机来说却并不简单:
![]()
这些图像在人类看来相似,但在计算机眼中却几乎毫无共同点。因为人类视觉系统依赖上下文线索来识别物体,而计算机只能看到像素组成的数值矩阵。
因此,计算机必须完全依赖数据本身来完成图像识别任务。但正如上面的例子所示,图像数据本身变化极大,如何构建一个能适应这种变化的系统?
2.2. 抽象是解决方案
图像识别之所以困难,是因为像素太多,每个像素单独携带的信息却很少。这意味着图像具有很高的“熵”(Entropy),即信息混乱度高。我们需要通过某种方式降低这种熵。
如果我们能学习图像的抽象特征,比如苹果通常有果梗、平底、圆形等特征:
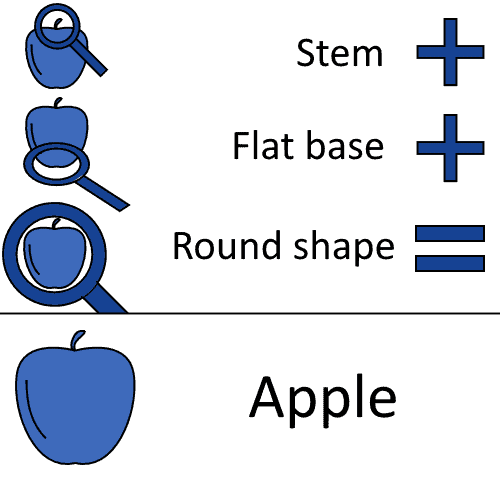
我们就可以把这些特征编码进分类算法中,从而更容易识别新图像是否是苹果:

CNN 正是通过这种方式工作,只不过它能自动学习这些抽象特征。这使得它成为一种有效的算法,能够缓解“维度灾难”问题。
3. 神经网络与维度灾难
3.1. CNN 要解决的问题
按照我们介绍机器学习模型的传统方式,我们先问一个问题:
✅ “为什么不能直接使用前馈神经网络来做图像分类?”
我们知道前馈神经网络理论上可以逼近任意连续函数,但它并不保证一定能学到目标函数。一般来说,神经网络很容易过拟合训练数据中的噪声,而无法真正学习目标函数:
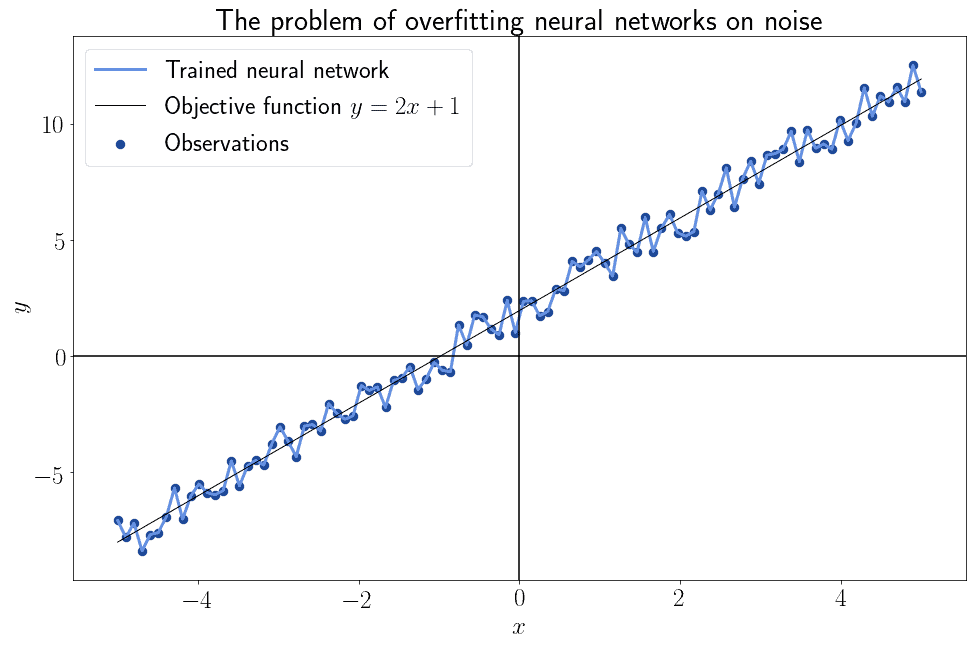
3.2. 卷积与正则化
为了减少神经网络训练过程中的噪声影响,我们使用一种叫“正则化”(Regularization)的技术。卷积是一种特殊的正则化方法,它利用特征之间的线性依赖关系来降低数据熵。
简单来说,正则化就是将高熵特征映射到低熵特征空间,从而减少过拟合风险。数学上表示为:
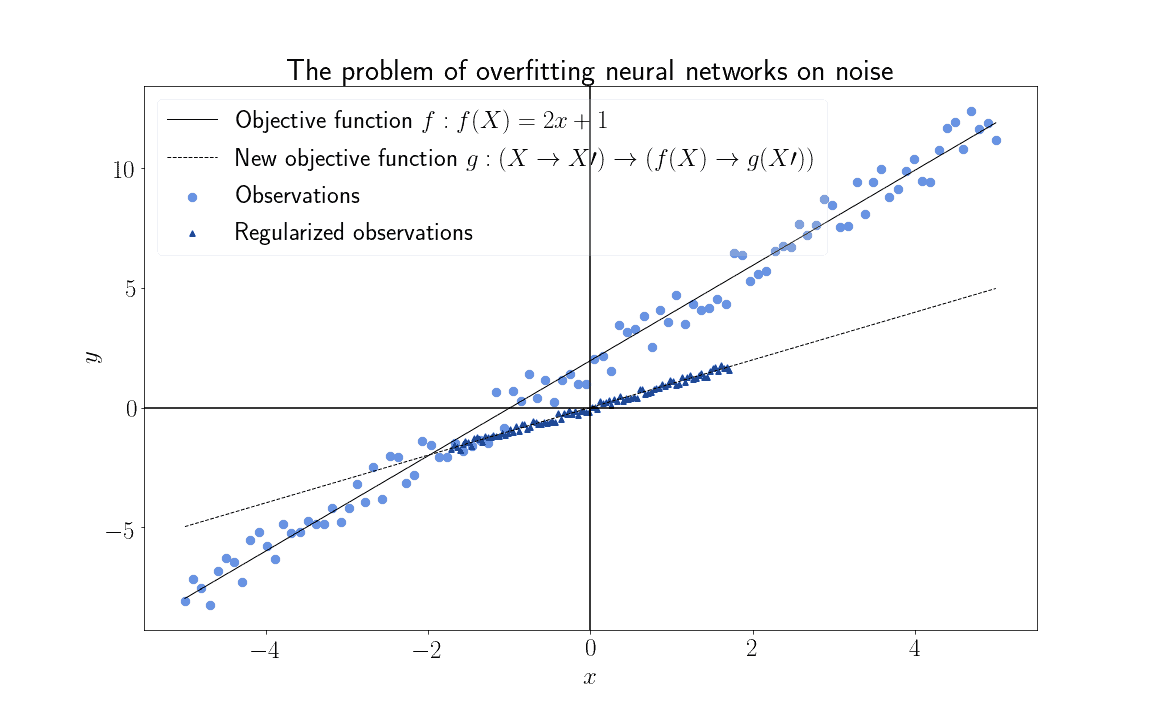
卷积正是通过这种方式,将高熵的图像特征转化为更复杂的低熵特征表达。
3.3. 特征的线性相关性
我们用一个例子来说明“特征线性相关”的概念。
假设我们有两个变量 X 和 Y,并且我们知道它们之间存在线性关系:Y = 2X + 1。这说明 X 和 Y 是线性相关的。
如果我们用这两个变量来训练一个目标函数 Z = g(X; Y),比如 Z = (X + Y)²:
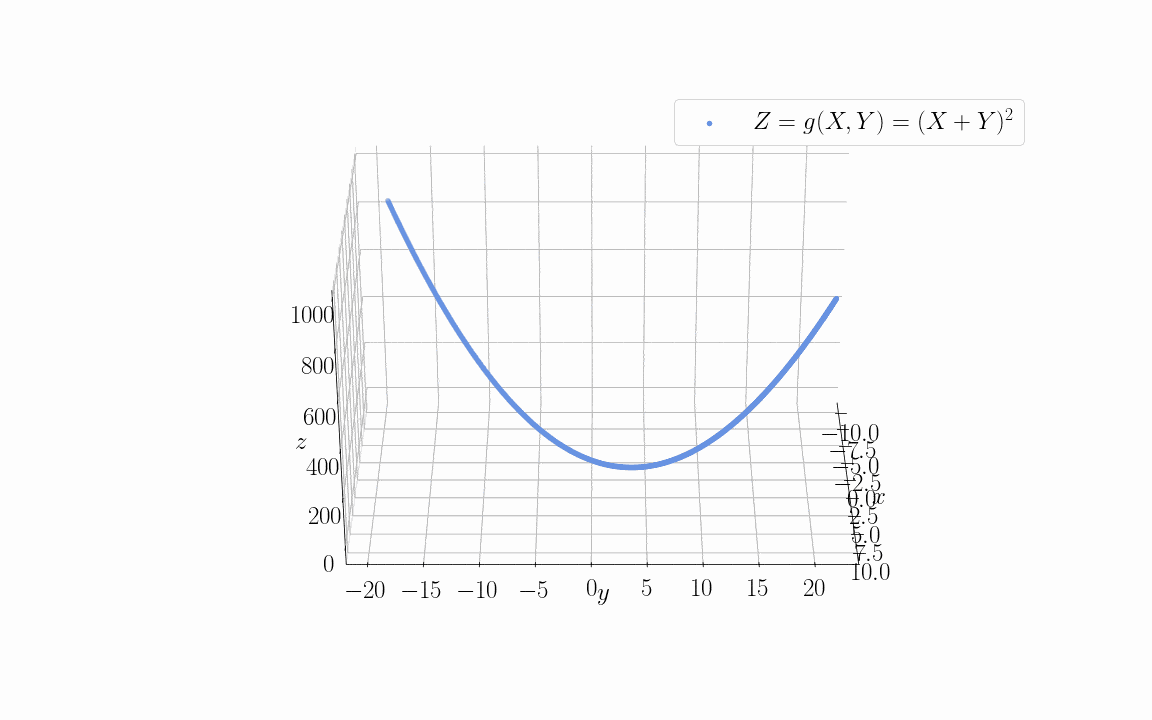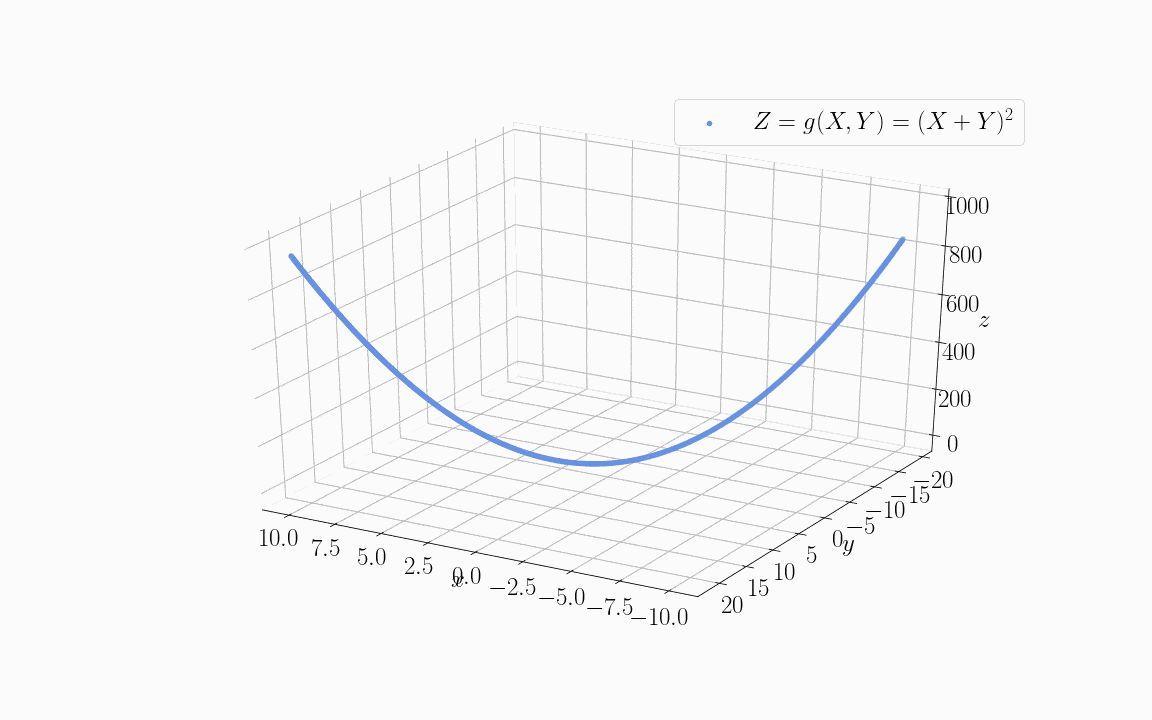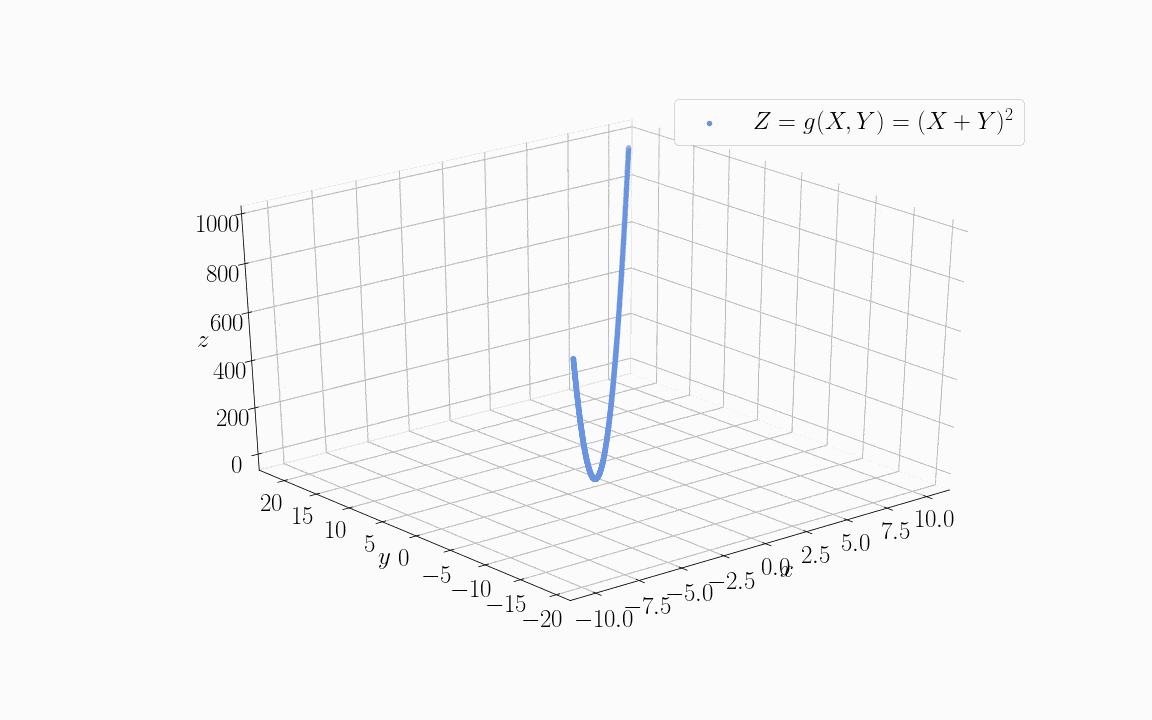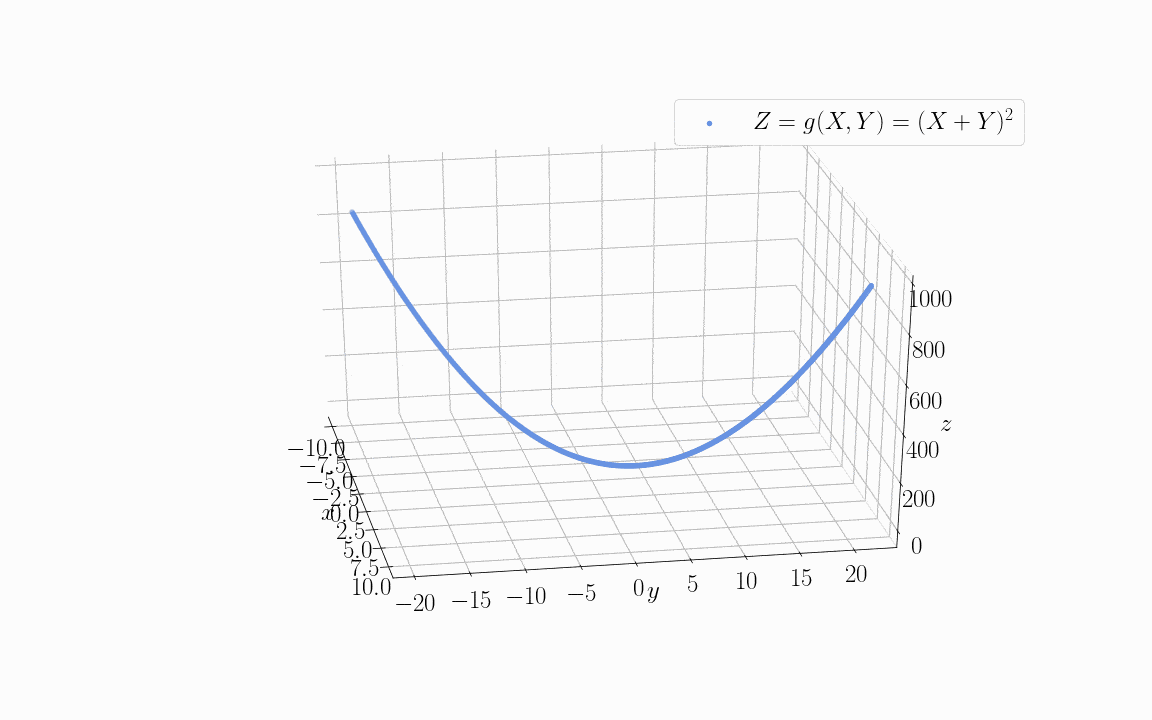
我们会发现,如果直接使用 X 和 Y 作为输入特征,模型需要学习 5 个参数(X、Y、X²、Y²、偏置项)。但由于它们线性相关,我们可以只用它们的线性组合(X + Y)来代替。
✅ 这样不仅减少了参数数量,还保留了模型的表达能力。
3.4. 将相关特征转化为独立特征
回到前面的例子,目标函数 Z = (X + Y)² = X² + 2XY + Y²。如果我们不利用 X 和 Y 的线性关系,就需要分别学习 X 和 Y 的系数。
但如果我们知道 Y = f(X),就可以简化模型,只学习一个组合参数:
✅ 这相当于将原始空间 (X, Y, Z) 映射到新的空间 (X+Y, Z),从而减少输入维度。
3.5. 维度灾难
如果输入特征之间存在线性相关性,我们就可以通过某种方式减少模型参数数量,从而缓解“维度灾难”问题。
✅ CNN 特别适合处理以下类型的高维数据:
- 文本:词与上下文之间存在依赖
- 音频:频率变化是连续的
- 图像:相邻像素颜色通常相似
- 视频:帧之间变化较小
这些数据具有高维且特征之间存在强相关性,非常适合使用 CNN 来降维。而像发动机参数等线性无关的数据则不适合使用 CNN。
3.6. CNN 的优势
使用 CNN 的最大优势是能有效缓解“维度灾难”问题。
在前面的例子中,我们通过降维将参数数量减少了 40%。在真实世界的问题中,这个比例往往更高。
✅ 因此,在处理高维数据时,使用卷积等降维技术几乎是必须的,而不是可选的。
4. 神经网络中的卷积
4.1. 卷积的数学定义
卷积是 CNN 的核心操作。它通过对输入矩阵进行局部加权求和来提取特征。
假设我们有一个图像矩阵 A,其维度为 (x, y),再定义一个卷积核(Kernel)k,卷积操作定义如下:
$$ k * A = \sum^{x-1}{i=0} \sum^{y-1}{j=0} k_{(x-i)(y-j)}A_{(1+i)(1+j)} $$
4.2. 卷积对矩阵的影响
我们以一张苹果图像为例来看看不同卷积核的效果:

✅ 模糊图像(Blur)
使用如下卷积核:
$$ k = \frac{1}{9} \begin{bmatrix} 1 & 1 & 1 \ 1 & 1 & 1 \ 1 & 1 & 1 \end{bmatrix} $$
效果如下:

✅ 边缘检测(Edge Detection)
使用如下卷积核:
$$ k = \begin{bmatrix} -1 & -1 & -1 \ -1 & 8 & -1 \ -1 & -1 & -1 \end{bmatrix} $$
效果如下:

✅ 特征锐化(Sharpen)
使用如下卷积核:
$$ k = \begin{bmatrix} 0 & -1 & 0 \ -1 & 5 & -1 \ 0 & -1 & 0 \end{bmatrix} $$
效果如下:

✅ 不同的卷积核可以提取不同的图像特征,这对 CNN 的训练至关重要。
5. CNN 的其他特性
5.1. CNN 的整体结构
虽然名字叫“卷积神经网络”,但 CNN 并不只是由卷积层构成。它还包括以下关键组件:
- 池化层(Pooling)
- Dropout 层
- 特殊激活函数(如 ReLU)
典型的 CNN 结构如下:
- 多个卷积层 + 池化层 + Dropout 层交替堆叠
- 最后一层为分类或回归层
5.2. 池化层(Pooling)
池化层的作用是从矩阵中提取一个低维矩阵,保留局部最大值或平均值。最常用的是最大池化(Max Pooling)。
举个例子,假设我们有一个 3x3 的矩阵 A:
$$ A = \begin{bmatrix} 1 & 2 & 3 \ 6 & 5 & 4 \ 3 & 1 & 2 \end{bmatrix} $$
我们使用 2x2 的窗口进行池化,得到如下四个子矩阵:
$$ \begin{bmatrix} 1 & 2 \ 6 & 5 \end{bmatrix}, \begin{bmatrix} 2 & 3 \ 5 & 4 \end{bmatrix}, \begin{bmatrix} 6 & 5 \ 3 & 2 \end{bmatrix}, \begin{bmatrix} 5 & 4 \ 2 & 1 \end{bmatrix} $$
取每个子矩阵的最大值,得到池化后的结果:
$$ \begin{bmatrix} 6 & 5 \ 6 & 5 \end{bmatrix} $$
✅ 池化层能有效降低维度,同时保留图像的主要特征。
5.3. Dropout 层
Dropout 层的作用是随机关闭部分神经元,防止模型过拟合。
对于给定的 dropout 参数 d(0 ≤ d ≤ 1),每个神经元有 d 的概率被设为 0。
举个例子,假设我们有如下矩阵 A:
$$ A = \begin{bmatrix} 1 & 2 & 3 \ 6 & 5 & 4 \ 3 & 1 & 2 \end{bmatrix} $$
设置 d = 0.4,可能的 Dropout 结果如下:
$$ \begin{bmatrix} 0 & 0 & 3 \ 6 & 5 & 0 \ 3 & 0 & 2 \end{bmatrix} $$
✅ Dropout 能有效减少模型对训练数据的依赖,提高泛化能力。
6. 总结
在本文中,我们学习了卷积神经网络的核心原理和结构。
- ✅ CNN 能有效处理高维且特征线性相关的数据,缓解维度灾难。
- ✅ 卷积操作通过不同卷积核提取图像的抽象特征。
- ✅ 除了卷积层,CNN 还包括池化层和 Dropout 层,用于降维和防止过拟合。
通过这些机制,CNN 能在图像识别、文本处理等任务中表现出色。