1. 概述
在机器学习模型的训练过程中,学习曲线是一个非常重要的诊断工具。本文将讲解学习曲线的概念、作用及其在训练过程中的应用。我们还将通过不同类型的曲线来识别模型是否出现了欠拟合、过拟合等问题,并判断训练/验证数据集是否具有代表性。
通过本文的学习,你将掌握如何通过学习曲线优化模型训练过程,避免常见的训练陷阱。准备好开始了吗?我们开始吧!
2. 学习曲线
2.1. 什么是学习曲线?
学习曲线是一种用于反映模型在训练过程中性能变化趋势的图表。通常,横轴表示训练的进度(如训练轮数、样本数量等),纵轴表示某种性能指标(如损失值、准确率等)。
学习曲线帮助我们:
✅ 监控模型训练过程
✅ 诊断训练问题(如欠拟合、过拟合)
✅ 判断数据集是否具有代表性
✅ 决定最佳的训练停止时机
2.2. 单一学习曲线
最常见的学习曲线包括:
- 损失值(Loss)随时间变化曲线:反映模型在训练过程中误差的变化
- 准确率(Accuracy)、精确率(Precision)、召回率(Recall)曲线:反映模型在分类任务中的表现
示例:损失值曲线
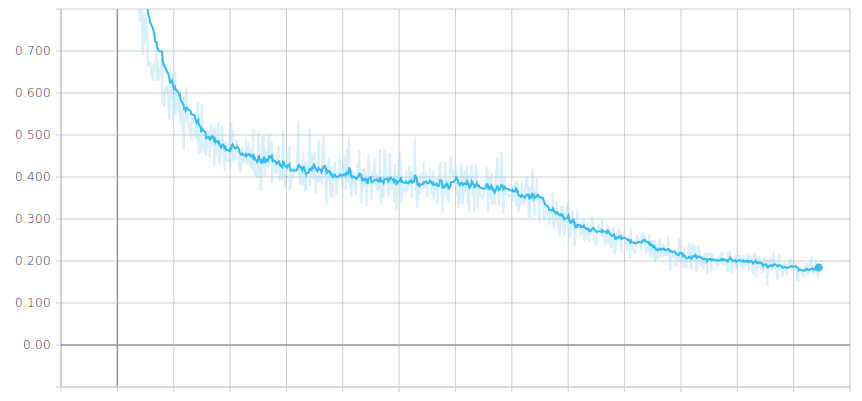
虽然曲线有小幅波动,但整体趋势是下降的,说明模型在不断学习。
示例:准确率曲线
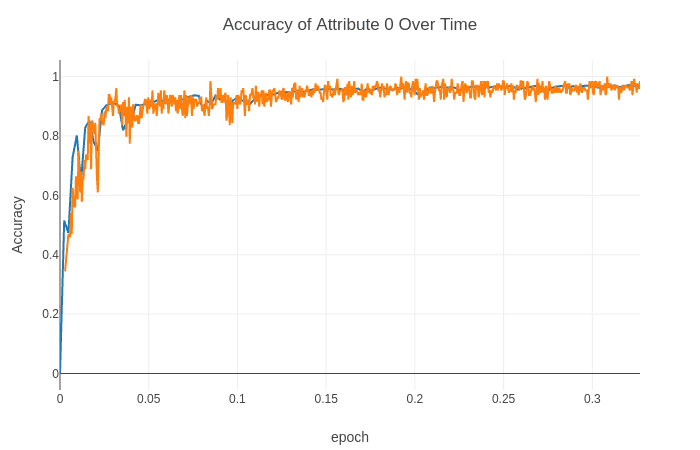
准确率随时间上升,说明模型性能在提升。当曲线趋于平稳时,表示模型已基本“学完”了当前数据的规律。
2.3. 多条学习曲线
在实际应用中,我们常常同时绘制训练集和验证集的指标曲线,以便更好地分析模型行为。
常见组合:
- 训练损失 vs 验证损失
- 训练准确率 vs 验证准确率
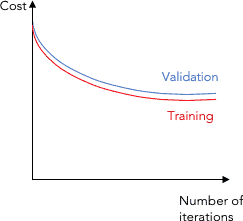
示例:训练损失 vs 验证损失曲线
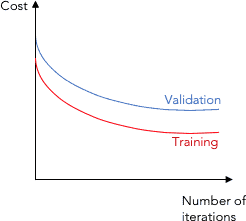
从图中可以看出训练损失和验证损失都较高,说明模型可能处于欠拟合状态。
2.4. 两种主要类型的学习曲线
优化型学习曲线(Optimization Learning Curves)
用于优化模型参数的指标,如损失值(Loss)、均方误差(MSE)性能型学习曲线(Performance Learning Curves)
用于评估模型性能的指标,如准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 分数等
示例:BLEU + Loss 曲线
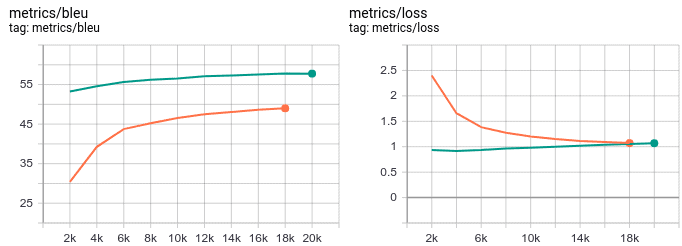
图中橙色和绿色分别代表两个模型的表现,可以看到它们在优化目标(Loss)与性能目标(BLEU)上的差异。
3. 如何通过学习曲线判断模型行为
3.1. 高偏差 / 欠拟合(High Bias / Underfitting)
什么是高偏差与欠拟合?
- 高偏差:模型未能捕捉数据中的关键特征
- 欠拟合:模型在训练集和验证集上表现都很差
案例说明:
假设我们想用一条直线拟合一组数据点:

如果我们拟合出的直线如下:

显然这条线没有反映出数据的真实趋势。当新数据到来时,预测效果也很差:
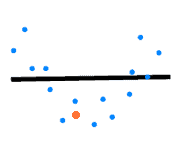
学习曲线特征:
- 训练损失和验证损失都很高
- 损失值没有随着训练轮数下降
- 模型无法从训练数据中学习到有效模式
✅ 解决方案:
- 增加模型复杂度
- 添加更多特征
- 减少正则化强度
3.2. 高方差 / 过拟合(High Variance / Overfitting)
什么是高方差与过拟合?
- 高方差:模型过于复杂,捕捉了数据中的噪声
- 过拟合:模型在训练集上表现很好,但在验证集上表现差
案例说明:
还是用那组数据点进行拟合:
如果我们拟合出的曲线非常复杂,如下图:
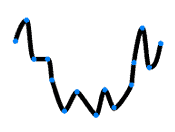
虽然完美拟合了训练数据,但面对新数据时:
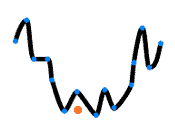
预测效果很差。
学习曲线特征:
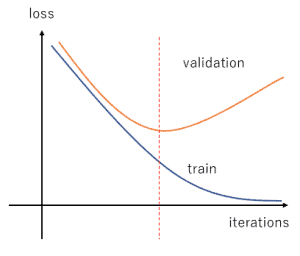
- 训练损失持续下降
- 验证损失先下降,之后开始上升
- 训练和验证损失之间有明显差距
✅ 解决方案:
- 增加训练数据量
- 使用正则化(L1/L2)
- 减少模型复杂度
- 使用交叉验证
3.3. 找到偏差与方差的平衡点
最佳拟合曲线示例:

当新数据点到来时:

预测效果明显更好。
学习曲线判断方法:
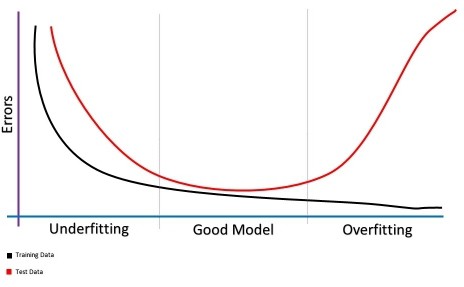
- 在验证损失开始上升时停止训练
- 停止太早 → 欠拟合
- 停止太晚 → 过拟合
4. 如何判断数据集是否具有代表性
4.1. 数据集代表性意味着什么?
一个具有代表性的训练集应能反映真实数据的统计分布特征。如果训练集和验证集来自不同分布,则会影响模型泛化能力。
4.2. 训练集不具代表性
学习曲线特征:
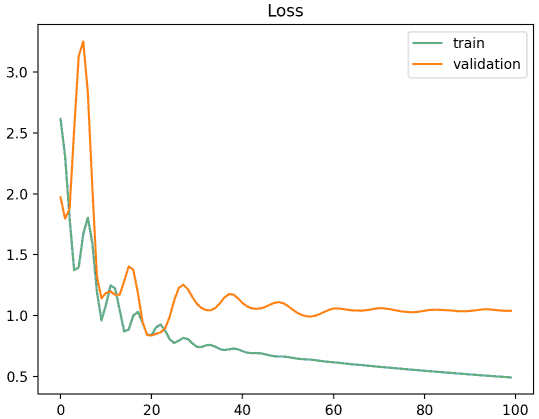
- 训练损失和验证损失都在下降
- 两者之间有较大差距
- 说明训练集不足以代表验证集
✅ 解决方案:
- 增加训练数据多样性
- 调整采样策略
- 使用数据增强技术
4.3. 验证集不具代表性
场景一:验证集样本太少
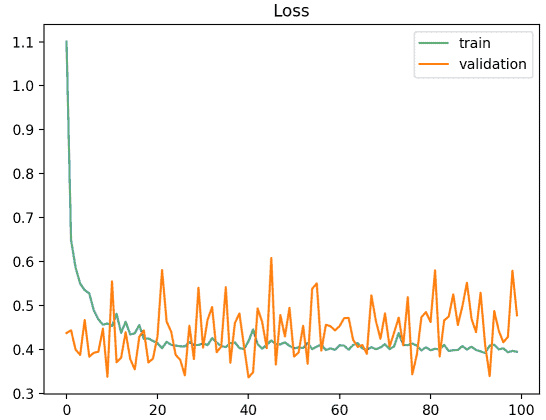
- 验证损失曲线波动大
- 与训练损失曲线差异大
- 可能是验证集样本太少或分布不均
场景二:验证集比训练集更简单
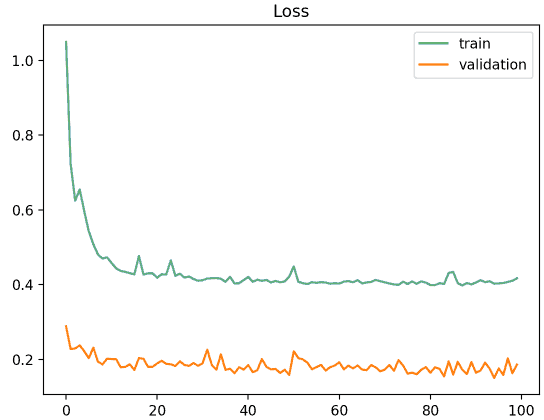
- 验证损失明显低于训练损失
- 表示验证集可能更容易预测
- 说明验证集不能代表真实场景
✅ 解决方案:
- 确保验证集与训练集来自相同分布
- 使用交叉验证
- 增加验证集样本量
5. 总结
通过本文我们学习了:
✅ 学习曲线的定义与作用
✅ 如何通过学习曲线识别模型是否欠拟合或过拟合
✅ 如何判断训练集与验证集是否具有代表性
✅ 如何利用学习曲线优化训练过程并选择最佳停止时机
学习曲线是模型训练中不可或缺的诊断工具,熟练掌握其分析方法,有助于我们快速定位问题并提升模型性能。在实际项目中,建议将学习曲线作为训练监控的标准手段之一。